Introduction
In order to build machine learning models that are highly generalizable to a wide range of test conditions, training models with high-quality data is essential. Unfortunately, a large part of the data collected is not readily ideal for training machine learning models. This increases the need for pre-processing steps such that the data is pipelined the way a machine learning model would expect. In data cleaning, one of the most crucial steps is to deal with/fill missing values (Imputing missing data or simply data imputation) accurately such that the machine learning model learns the patterns in data as expected.

Learning Objectives:
- Learn how to deal with/fill the missing data using ML algorithms.
- Familiarize the steps in data imputation process.
This article was published as a part of the Data Science Blogathon.
Some of the most commonly practiced methods of dealing with missing values are:
- Dropping off the rows with NULL values.
This method is one of the most commonly used techniques to eradicate the inconvenience of dealing with missing data in the training phase if in case, the training data available is huge. - Fill in the NULL values with some arbitrary constants such as 0 etc.
This method is rarely used in the machine learning community due to its less promising results. However, the method is subject to yield good results in certain situations. - Fill in the NULL values with statistically determined values based on the statistics of the training data such as training distribution mean, variance, etc.
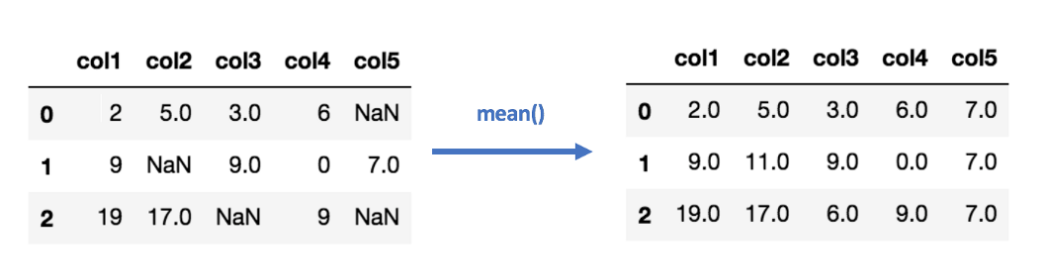
This method is the most generally used method to fill the missing values
4. Predict the NULL values with Machine Learning Algorithms using the entire training data (without NULL values).
Resources for the Statistical Methods
Since this article focuses on predicting the missing values instead of inferring them from the distribution of the dataset, the reference to the three methods mentioned above that either deal with/fills the missing values are gathered below. Consider checking them out to better understand where and when to use each of these methods.
Introduction to “Understanding and Tackling Missing Values” talks from scratch, all the way up to dealing with the most complex techniques with examples.
Furthermore “Dealing with Missing Values in Python” talks about the fundamentals and important ideas in dealing with missing values.
and Furthermore in “Dealing with Missing Values in Python“, and “Statistical Imputation for Missing Value“.

Data Imputation Using ML Algorithms
Fundamentally, the problem of data imputation using ML algorithms is broadly classified into two types, using the classification algorithm and the regression algorithm. Based on the type of training data, we need to use it to categorize the problem. In this article we take look at using a classification algorithm, however, using a regression algorithm is identical (refer to an example of a regression algorithm here). In order the solve the problem of missing values in the datasets using ML algorithms, data need to undergo certain steps including pre-processing and modelling. Below are the 5 most commonly categorized steps to fill the missing values with accurate data using ML algorithms.
0. Overview
On the high level, a dataset, by dropping the labels or y column, is considered and divided into two sets, one called the training set and another one the test set. The division takes place based on the rows with NULL values and rows without NULL values. Each of these datasets is further divided into X, and y such that we have X_train, y_train, X_test, and y_test. y_train and y _test are column(s) containing the missing values (to be predicted). Upon training, we predict the missing values using the test data. More on how this works in the below steps.
Throughout this article, we use the most popular Kaggle dataset on the regression problem statements. The Google Colab notebook with detailed code and documentation is available here.
1. Preparing the Data
After dropping the label or y column, the dataset is divided into training and testing. The division takes place with reference to the presence of NULL values in individual rows.
1. Import the data using pandas CSV:
Reading the CSV file using pandas read_csv() function
# Importing all the required packages import pandas as pd import numpy as np import matplotlib.pyplot as plt import sklearn
# Reading the csv file using pandas read_csv
df = pd.read_csv('/content/drive/MyDrive/TrainAndValid.csv/TrainAndValid.csv')
# I am importing data from my Gdrive but you can get access by downloading from Kaggle or from the following link:
# https://drive.google.com/file/d/19B2HAK4Tlma-YhlJfXiXg-Wy1F68DSb8/view?usp=sharing
2. Investigate the dataset using methods such as info(), describe(), etc:
EDA (Exploratory Data Analysis) is a crucial step in understanding the data and the very first few functions used to initiate this process are info(), describe(), isna(), etc.
# Let's learn about the dataset df.info() # Check out the df.describe() in a new cell to learn more.
3. Split the dataset based on NULL values in the dataset:
We drop the NULL values in our dataset and use that as a training set and then use the complete dataset to test on. Since we don’t have the true values for missing data it is a better option to use the complete dataset to evaluate the performance of the model.
from sklearn.model_selection import train_test_split
X_test = df.drop('UsageBand', axis=1)
y_test = df['UsageBand']
df_train = df.dropna()
X_train = df_train.drop('UsageBand', axis=1)
y_train = df_train['UsageBand']
2. Modelling
We use the Random Forest Classifier model for modelling to impute the data.
# Training the model based on the X_train and y_train data from sklearn.ensemble import RandomForestClassifier rfc = RandomForestClassifier() # fit the model rfc.fit(X_train, y_train)
3. Predict the Missing Values
Using the trained model Random Forest Classifier, fill/predict the class values of categorical column
# predict the values y_filled = rfc.predict(X_test)
4. Substitute the Data & Use the clean data
Replace the y_predicted with the column consisting of missing data in the original data set and continue the modelling.
# now we have the missing values filled so replace the column in original dataset and use the predicted one df['UsageBand'] = y_filled # Proceed and use the dataset for modelling the actual problem :)
Conclusion
In this article, we have seen, how to impute the missing data using ML algorithms? Also gathered some of the resources to learn various methods to impute the missing data such as statistical methods. Importantly, we have seen how to use the existing training data to train and infer missing values using a statistical machine learning model (Random Forest Regressor in this case). We have also explored some of the standard methods followed while predicting the missing values using machine learning models such as split data based on NULL values in a row, training a model based on training datatype, and predicting missing data based on the missing data density in the training data. We barely scratched the surface of EDA (Exploratory Data Analysis) in this article through functions such as drop(), dropna(), etcetera.
Key Takeaways:
- The idea of splitting the available data into train and test, to model an ML algorithm for predicting missing values, based on NULL values.
- Test the trained model using the complete train and test data. As a continuity, the imputed dataset is used to model any machine learning algorithm (which we couldn’t be trained before, because of the presence of missing data) to solve the actual problem i.e., in this case, predicting automobile prices.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
AI Alchemist with a passion for turning complex problems into elegant solutions. I'm a driven CS undergrad and ML student researcher at LPU, where I'm actively involved in open-source projects at sktime.net. When I'm not wrangling code, you'll find me on LeetCode.com, where I consistently rank in the top 10%. Cloud technologies are another area of fascination for me, and I'm always eager to explore new frontiers in this ever-evolving landscape.






