Introduction
Object detection’s main challenge is effectively representing objects at vastly different scales. Existing techniques for object detection either rely on multi-level feature detectors or adopt the DETR framework. However, each of these methods has disadvantages. For instance, multi-level feature detectors cannot detect objects of vastly different scales with high accuracy. Furthermore, although the DETR framework eliminates the need for many hand-designed components in object detection, it introduces a decoder demanding an extra long time to converge. As a result, these existing methods aren’t suitable for large-scale applications. In light of this, researchers from Tencent Youtu Lab and Zhejiang University have proposed a novel decoder-free fully transformer-based (DFFT) object detector, which helps achieve high efficiency in both training and inference stages.
I stumbled upon this exciting research work the other day and was intrigued to learn more about their approach. This post is essentially a summary article based on the aforementioned research paper. All credit for this research goes to the researchers of this project.
Now let’s dive in and see how a Decoder-free, Fully Transformer-based object detector can achieve high efficiency in both the training and inference stages.
This article was published as a part of the Data Science Blogathon.
Table of contents
Method Overview of DFFT
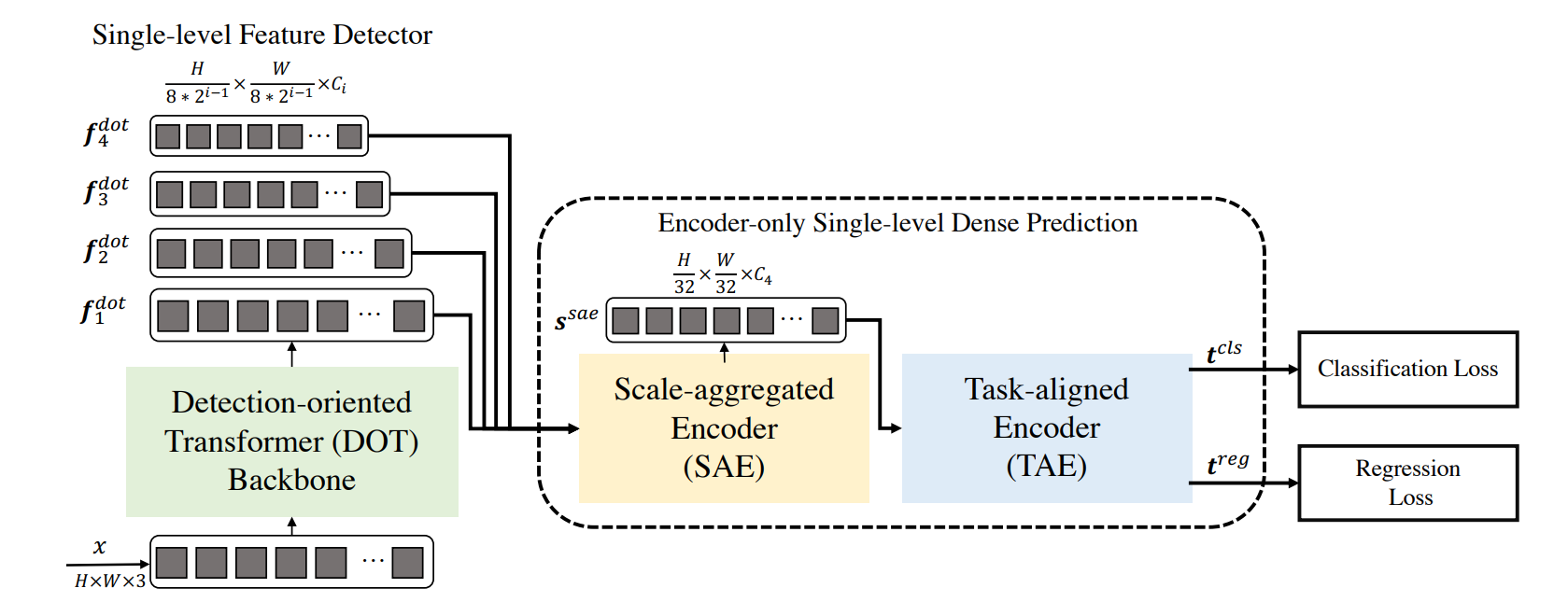
To design a lightweight object detection pipeline and maintain high training efficiency and efficient Decoder-Free, a Fully Transformer-based (DFFT) object detector is proposed (as shown in Figure 1).
(Source: Arxiv)
DFFT mainly comprises of following three major modules:
1. The i-th DOT Backbone Stage: A lightweight Detection-Oriented Transformer backbone with four DOT stages to extract features with rich semantic information (Figure 1 and Figure 2a).
2. Scale-aggregated Encoder: A Scale-Aggregated Encoder (SAE) with three SAE blocks to aggregate multi-scale features into one efficient feature map (Figure 1 and Figure 2b).
3. Task-Aligned Encoder: A Task-Aligned Encoder (TAE) to resolve conflicts between classification and regression tasks in the coupled detection head (Figure 1 and Figure 2c).
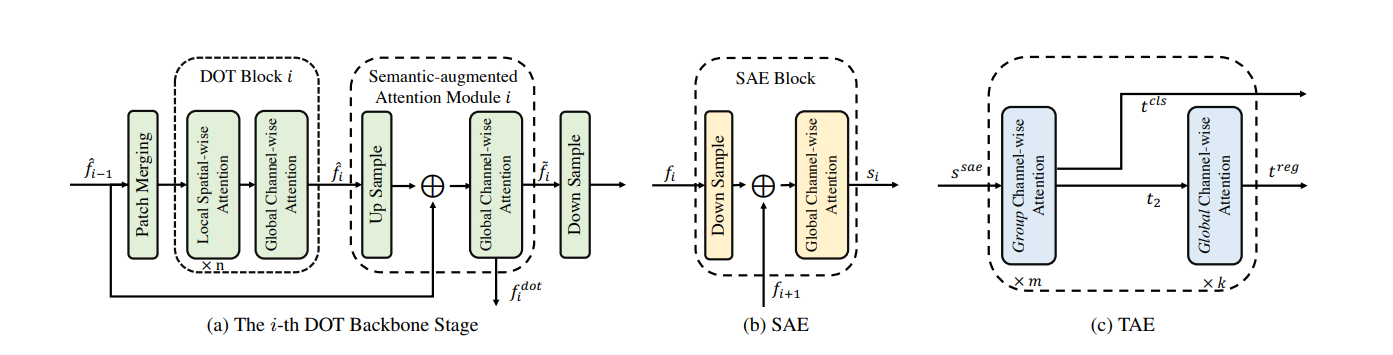
Figure 2. Illustration of the three major modules in the proposed DFFT
(Source: Arxiv)
This design simplifies the whole object detection pipeline to an encoder-only single-level anchor-based dense prediction task by centering around two entry points:
- Replace the training-inefficient decoder with two strong encoders to maintain the accuracy of single-level feature map prediction;
- Investigate low-level semantic features for the detection task with limited computational resources.
Furthermore, the Detection-oriented Transformer (DOT) backbone F of the DFFT framework extracts features at four scales and sends them to the following encoder-only single-level dense prediction module. The prediction module first aggregates the multi-scale feature into a single feature map through the Scale-Aggregated Encoder (SAE). Then the TaskAligned Encoder (TAE) is used to align the feature for classification and regression tasks simultaneously for higher inference efficiency.
Detailed Description of Object Detection
Now we’ll take a closer look at each module individually.
1) The i-th DOT Backbone Stage
- Detection-oriented transformer (DOT) backbone extracts multi-scale features with strong semantics. As Figure 3a hierarchically stacks one embedding module and four DOT stages, where a novel semantic augmented attention module aggregates the low-level semantic information of every two consecutive DOT stages. For each input image x ∈ R H×W×3 , the DOT backbone extracts features at four different scales:
f1 dot , f2 dot , f3 dot , f4 dot = F(x)
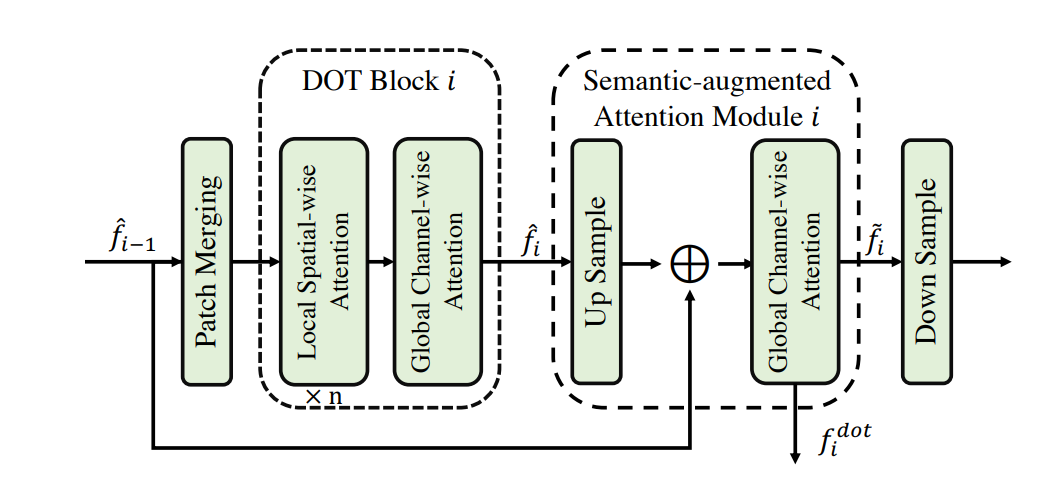
Figure 3. i-th DOT backbone stage
(Source: Arxiv)
2) Scale-aggregated Encoder (SAE)
This encoder is designed with three SAE blocks.
- Each SAE block takes features as the input and aggregates the features step by step across all SAE blocks
- SAE aggregates multiscale features into one feature map to reduce the inference stage’s computational costs.
- The scale of the final aggregated feature is set to H/32 × W/32 to balance the detection precision and computational costs. Before aggregation, the last SAE block up-samples the input feature to H/32 × W/32. This whole procedure can be described as:

where Satt is the global channel-wise attention block
ssae = s3 –> the final aggregated feature map
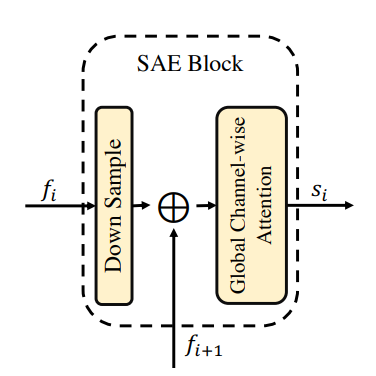
Figure 4. Scaled-aggregator Encoder
(Source: Arxiv)
The scale-aggregated encoder summarizes multi-scale cues to one feature map by progressively analyzing global spatial and semantic relations of two consecutive feature maps. Thus, instances of various scales are easily detected on the single feature map, avoiding exhaustive search across network layers.
3) Task-aligned Encoder (TAE)
- Benefiting from the group channel-wise attention’s capability of modeling semantic relations, TAE handles task conflicts in a coupled head and further generates task-aligned predictions in a single pass.
- This encoder primarily comprises two kinds of channel-wise attention blocks:
- The stacked group channel-wise attention blocks Tgroup align and finally split the aggregated feature ssae into two parts.
- The global channel-wise attention blocks Tglobal further encodes one of the two split features for the subsequent regression task.
This procedure can be described as :

where,
t1, t2: split features
tcls, treg: the final features
for the classification and regression tasks
Tglobal : global channel-wise attention
Tgroup : stacked group channel-wise attention blocks
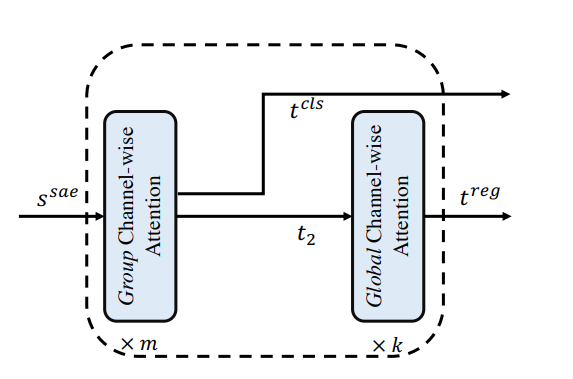
Figure 5. Task-aligned Encoder
(Source: Arxiv)
- TAE offers a better balance between learning task-interactive and task-specific features via stacking group channel-wise attention blocks in a coupled head.
- The key difference between the group channel-wise attention block and the global channel-wise attention block is that all the linear projections except the projections for key/query/value embeddings in the group channel-wise attention block are conducted in two groups. Thus, features interact in attention operations while deduced separately in output projections.
Results of Object Detection
1) Analysis of the impact of i-th DOT backbone
- The DOT backbone boosts the detection precision from 33.8% to 37.9%, indicating that it can obtain better semantic features (information) that are more suitable for the detection task.
- Even without the SAE, it gets competitive precisions with only the last stage’s outputs, suggesting that the SAA can capture multi-scale information when aggregating semantic information.
- SAA obtains richer low-level semantic features for object detection tasks by augmenting the semantic information from high-level features to low-level ones, sharing a similar effect as FPN.
2) Analysis of the impact of Scale-aggregated Encoder (SAE)
- SAE aggregates multiscale features into a single feature map to reduce the computational expenses at the inference stage. It also improves 1.1% AP from the dilated encoder of YOLOF. SAE outperforms a vanilla concatenation operation by 1.8% higher precision. Overall, SAE can offer better performance with low computational expenses.
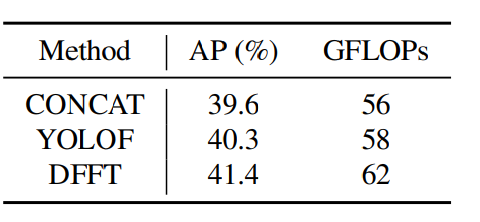
Table 1. Analysis of SAE
(Source: Arxiv)
3) Analysis of the impact of Task-aligned Encoder (TAE)
- The TAE enables DFFT to conduct classification and regression tasks in a coupled head simultaneously.
- After replacing TAE with YOLOF’s head in the baseline model, it was found that the best anchors for classification (red) and localization (orange) are distant. That is because YOLOF employs a task-unaligned decoupled head which leads to inconsistent predictions of classification and localization.
- Also, disabling TAE reduces the precision by 1.5%. This demonstrates the need for TAE to align and encode the classification and regression features.

Figure 6. Illustration of detection results from the best anchors for
classification (red) and localization (orange). Blue boxes and centers indicate ground truth.
(Source: Arxiv)
4) Analysis of the impact of DFFT on GFLOPs and FPS
When compared to deformable DETR, DFFT offers better AP and inference efficiency. At the same FPS, DFFT outperforms DETR regarding accuracy and GLOPS.
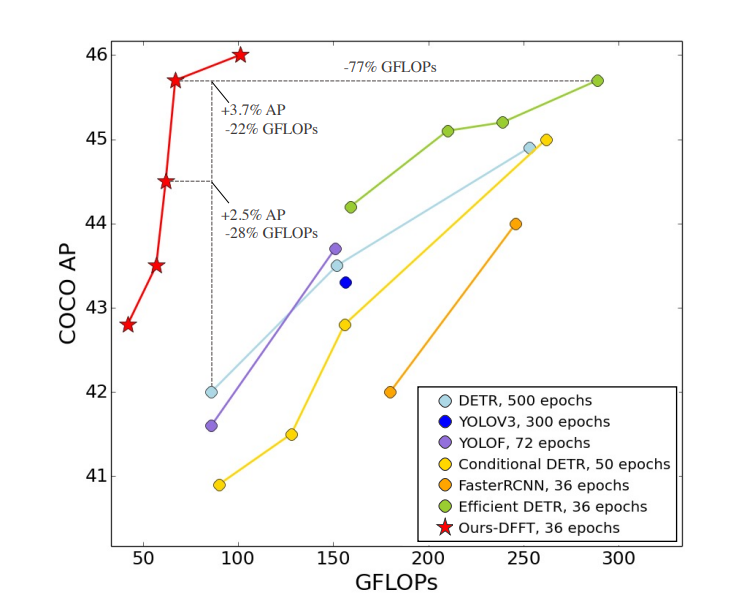
Figure 7. The trade-off between performance (AP) and efficiency (Epochs & GFLOPs) for detection methods.
Conclusion
So, in this post, we saw how a lightweight, decoder-free, fully transformer-based object detector can be employed to achieve high efficiency in both the training and inference stages without sacrificing noticeable detection precision. The design also trims the training-inefficient decoder for more than 10× training acceleration over DETR. Extensive evaluation reveals DFFT’s unique advantages in capturing low-level semantic features in object detection and its ability to preserve detection precision while trimming the training-inefficient decoders in DETR.
To sum it up, the key takeaways from this post are:
1. DFFT simplifies object detection to an encoder-only single-level anchor-based dense prediction framework.
2. To design a lightweight object detection pipeline and maintain high training efficiency, the training-inefficient decoder is eliminated, and two strong transformer encoders in the feature fusion and class/box network are proposed to preserve the accuracy of single-level feature map prediction and to avoid performance decline after trimming the decoder.
3. DFFT introduces large receptive fields to cover large objects based on the transformer’s global relation modeling and meanwhile captures and aggregates low-level features with rich semantics through the scale-aggregated encoder (SAE). Such designs enable DFFT to detect objects of vastly different scales accurately.
4. Extensive experiments on the MS COCO benchmark demonstrate that DFFTSMALL outperforms DETR by 2.5% AP with 28% computation cost reduction and more than 10× fewer training epochs. Compared to the cutting-edge anchor-based detector RetinaNet, DFFTSMALL achieves over 5.5% AP gain while reducing computation cost by 70%.
5. DFFT achieves state-of-the-art performance while using only half the GFLOPs of previous approaches, indicating promising future work on the large-scale application of transformers in object detection.
The code is available at https://github.com/ Pealing/DFFT
Thanks for reading. If you have any questions or concerns, please leave them in the comments section below. Happy Learning!
Frequently Asked Questions
Q1. What is transformer based object detection?
A. Transformer-based object detection merges transformers with computer vision to identify objects in images. It utilizes self-attention mechanisms, enabling global context understanding.
Q2. What is the best object detection model?
A. The best object detection model varies based on requirements. EfficientDet, YOLOv4, and Faster R-CNN are among top performers, excelling in accuracy or speed.
Q3. What is the fastest model for object detection?
A. Speedy object detection peaks in models like YOLO (You Only Look Once) due to its single-stage architecture, processing images swiftly without compromising accuracy.
Q4. What are the advantages of DETR?
A. DETR (DEtection TRansformer) revolutionizes object detection by directly predicting objects’ positions, omitting the need for complex heuristics, enabling end-to-end training, and handling varying object counts. It streamlines and simplifies the detection process.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I'm a Researcher who works primarily on various Acoustic DL, NLP, and RL tasks. Here, my writing predominantly revolves around topics related to Acoustic DL, NLP, and RL, as well as new emerging technologies. In addition to all of this, I also contribute to open-source projects @Hugging Face.
For work-related queries please contact: [email protected]






