Data has become an essential part of our daily lives in today’s digital age. From searching for a product on e-commerce platforms to placing an order and receiving it at home, we are constantly generating and consuming data. Today’s data-driven world generates data from various sectors like retail, automobile, finance, technology, aviation, food, media, etc. These data sets are in different forms and massive in quantity.
Extracting valuable insights from these data sets requires using modern tools and technologies to handle the data’s scale and complexity. With the right tools, organizations can gain a deeper understanding of their operations and make data-driven decisions to improve their performance.
In this article, we will work on a case study, and the data we will use is from the retail industry. The tool we use for this case study is PySpark and Databricks. To work on this case study, I am using the Databricks Community Edition.
.png)
Learning Objectives
This article was published as a part of the Data Science Blogathon.
Retail data is information that a retail shop owner might collect to better their firm. This information gives merchants information about their customers, sales patterns, and inventories across the retail industry. Datarade can assist you in locating retail data APIs and datasets.
Retail data plays a crucial role in the decision-making process of retailers. By collecting and analyzing various forms of data, retailers can gain valuable insights into their business performance and make informed decisions to improve their bottom line. By using the retail data, we will see how a retail company can improve its operations and increase its profits with the help of data analysis. We are going to find the hidden insight from this data.
.png)
We will create a dataframe from the provided dataset. We have six datasets with customer details, product order details, product details, and product category information.
Dataset Link: https://github.com/kishanpython/Data-Articles/tree/main/Article’s%20Datasets/retails_data
.png)
We are going to create six data frames. Which contains the following information:-
1. Customer Dataframe: This dataframe contains information related to the customer. It has nine columns which are as follows:-
Now we will create the schema for the customer dataframe.
# define the schema for customer dataset
customers_schema = StructType([
StructField('customer_id', IntegerType(), nullable=True),
StructField('customer_fname', StringType(), nullable=True),
StructField('customer_lname', StringType(), nullable=True),
StructField('customer_email', StringType(), nullable=True),
StructField('customer_password', StringType(), nullable=True),
StructField('customer_street', StringType(), nullable=True),
StructField('customer_city', StringType(), nullable=True),
StructField('customer_state', StringType(), nullable=True),
StructField('customer_zipcode', StringType(), nullable=True)])
We will make the dataframe using the above schema.
# file location and type of files
file_loc = '/FileStore/tables/'
file_type = "csv"
# file path
customer_data = file_loc + 'customers.csv'
# file options
first_row_is_header = "True"
delimiter = ","
# create a dataframe using the above details
customers_df = spark.read.format(file_type)
.option("sep", delimiter)
.option("header", first_row_is_header)
.schema(customers_schema)
.load(customer_data)
The customer dataframe will look like this:
+-----------+--------------+--------------+--------------+-----------------+--------------------+-------------+--------------+----------------+ |customer_id|customer_fname|customer_lname|customer_email|customer_password| customer_street|customer_city|customer_state|customer_zipcode| +-----------+--------------+--------------+--------------+-----------------+--------------------+-------------+--------------+----------------+ | 2| Mary| Barrett| XXXXXXXXX| XXXXXXXXX|9526 Noble Embers...| Littleton| CO| 80126| | 3| Ann| Smith| XXXXXXXXX| XXXXXXXXX|3422 Blue Pioneer...| Caguas| PR| 00725| | 4| Mary| Jones| XXXXXXXXX| XXXXXXXXX| 8324 Little Common| San Marcos| CA| 92069| | 5| Robert| Hudson| XXXXXXXXX| XXXXXXXXX|10 Crystal River ...| Caguas| PR| 00725| | 6| Mary| Smith| XXXXXXXXX| XXXXXXXXX|3151 Sleepy Quail...| Passaic| NJ| 07055| | 7| Melissa| Wilcox| XXXXXXXXX| XXXXXXXXX|9453 High Concession| Caguas| PR| 00725| | 8| Megan| Smith| XXXXXXXXX| XXXXXXXXX|3047 Foggy Forest...| Lawrence| MA| 01841| | 9| Mary| Perez| XXXXXXXXX| XXXXXXXXX| 3616 Quaking Street| Caguas| PR| 00725| | 10| Melissa| Smith| XXXXXXXXX| XXXXXXXXX|8598 Harvest Beac...| Stafford| VA| 22554| | 11| Mary| Huffman| XXXXXXXXX| XXXXXXXXX| 3169 Stony Woods| Caguas| PR| 00725| | 12| Christopher| Smith| XXXXXXXXX| XXXXXXXXX|5594 Jagged Ember...| San Antonio| TX| 78227| | 13| Mary| Baldwin| XXXXXXXXX| XXXXXXXXX|7922 Iron Oak Gar...| Caguas| PR| 00725| | 14| Katherine| Smith| XXXXXXXXX| XXXXXXXXX|5666 Hazy Pony Sq...| Pico Rivera| CA| 90660| | 15| Jane| Luna| XXXXXXXXX| XXXXXXXXX| 673 Burning Glen| Fontana| CA| 92336| | 16| Tiffany| Smith| XXXXXXXXX| XXXXXXXXX| 6651 Iron Port| Caguas| PR| 00725| | 17| Mary| Robinson| XXXXXXXXX| XXXXXXXXX| 1325 Noble Pike| Taylor| MI| 48180| | 18| Robert| Smith| XXXXXXXXX| XXXXXXXXX|2734 Hazy Butterf...| Martinez| CA| 94553| | 19| Stephanie| Mitchell| XXXXXXXXX| XXXXXXXXX|3543 Red Treasure...| Caguas| PR| 00725| | 20| Mary| Ellis| XXXXXXXXX| XXXXXXXXX| 4703 Old Route|West New York| NJ| 07093| | 21| William| Zimmerman| XXXXXXXXX| XXXXXXXXX|3323 Old Willow M...| Caguas| PR| 00725| +-----------+--------------+--------------+--------------+-----------------+--------------------+-------------+--------------+----------------+
Now we will create a Product dataframe.
2. Product dataframe: The product information contained in this dataframe. The six columns within it are as follows:-
First, we will create the schema for this dataframe. Which will look like this:-
# define schema for products dataset
products_schema = StructType([
StructField('product_id', IntegerType(), nullable=True),
StructField('product_category_id', IntegerType(), nullable=True),
StructField('product_name', StringType(), nullable=True),
StructField('product_description', StringType(), nullable=True),
StructField('product_price', FloatType(), nullable=True),
StructField('product_image', StringType(), nullable=True)])
Now we will make the dataframe using the above product schema.
# create the dataframe
products_df = spark.read.format(file_type)
.option("sep", delimiter)
.option("header", first_row_is_header)
.schema(products_schema)
.load(products_data)
The product dataframe will look like this:-
+----------+-------------------+---------------------------------------------+-------------------+-------------+---------------------------------------------------------------------------------------+ |product_id|product_category_id|product_name |product_description|product_price|product_image | +----------+-------------------+---------------------------------------------+-------------------+-------------+---------------------------------------------------------------------------------------+ |2 |2 |Under Armour Men's Highlight MC Football Clea|null |129.99 |http://images.acmesports.sports/Under+Armour+Men%27s+Highlight+MC+Football+Cleat | |3 |2 |Under Armour Men's Renegade D Mid Football Cl|null |89.99 |http://imagess.acmesports.sports/Under+Armour-Men%27s+Renegade+D+Mid+Football+Cleat | |4 |2 |Under Armour Men's Renegade D Mid Football Cl|null |89.99 |http://imagess.acmesports.sports/Under+Armour-Men%27s+Renegade+D+Mid+Football+Cleat | |5 |2 |Riddell Youth Revolution Speed Custom Footbal|null |199.99 |http://images.acmesports.sports/Riddell+Youth+Revolution+Speed+Custom+Football+Helmet | |6 |2 |Jordan Men's VI Retro TD Football Cleat |null |134.99 |http://images.acmesports.sports/Jordan+Men%27s+VI+Retro+TD+Football+Cleat | |7 |2 |Schutt Youth Recruit Hybrid Custom Football H|null |99.99 |http://images.acmesports.sports/Schutt+Youth+Recruit+Hybrid+Custom+Football+Helmet+2014| |8 |2 |Nike Men's Vapor Carbon Elite TD Football Cle|null |129.99 |http://imagess.acmesports.sports/Nike-Men%27s+Vapor+Carbon+Elite+TD+Football+Cleat | |9 |2 |Nike Adult Vapor Jet 3.0 Receiver Gloves |null |50.0 |http://images.acmesports.sports/Nike+Adult+Vapor+Jet+3.0+Receiver+Gloves | |10 |2 |Under Armour Men's Highlight MC Football Clea|null |129.99 |http://imagess.acmesports.sports/Under+Armour-Men%27s+Highlight+MC+Football+Cleat | |11 |2 |Fitness Gear 300 lb Olympic Weight Set |null |209.99 |http://images.acmesports.sports/Fitness+Gear+300+lb+Olympic+Weight+Set | +----------+-------------------+---------------------------------------------+-------------------+-------------+---------------------------------------------------------------------------------------+
3. Categories DataFrame: This dataframe has a list of product categories. It has three columns product_id, product_category_id, and category_name.
Let’s create the schema for this dataset.
# define schema for categories
categories_schema = StructType([
StructField('category_id', IntegerType(), nullable=True),
StructField('category_department_id', IntegerType(), nullable=True),
StructField('category_name', StringType(), nullable=True)])
Using the categories_schema, we are going to create the categories_df dataframe.
# create the dataframe
categories_df = spark.read.format(file_type)
.option("sep", delimiter)
.option("header", first_row_is_header)
.schema(categories_schema)
.load(categories_data)
The categories dataframe will look like this:-
+-----------+----------------------+-------------------+ |category_id|category_department_id| category_name| +-----------+----------------------+-------------------+ | 2| 2| Soccer| | 3| 2|Baseball & Softball| | 4| 2| Basketball| | 5| 2| Lacrosse| | 6| 2| Tennis & Racquet| | 7| 2| Hockey| | 8| 2| More Sports| | 9| 3| Cardio Equipment| | 10| 3| Strength Training| | 11| 3|Fitness Accessories| +-----------+----------------------+-------------------+
4. Orders Dataframe: In this dataframe, we have details related to item orders and their payment status. It has four columns which are as follows:-
Let’s create a schema and ‘orders_df‘ dataframe using this dataset.
# define the schema for orders
orders_schema = StructType([
StructField('order_id', IntegerType(), nullable=True),
StructField('order_date', StringType(), nullable=True),
StructField('order_customer_id', IntegerType(), nullable=True),
StructField('order_status', StringType(), nullable=True)])
# create the dataframe
orders_df = spark.read.format(file_type)
.option("sep", delimiter)
.option("header", first_row_is_header)
.schema(orders_schema)
.load(orders_data)
The ‘orders_df’ will look like this:-
+--------+--------------------+-----------------+---------------+ |order_id| order_date|order_customer_id| order_status| +--------+--------------------+-----------------+---------------+ | 2|2013-07-25 00:00:...| 256|PENDING_PAYMENT| | 3|2013-07-25 00:00:...| 12111| COMPLETE| | 4|2013-07-25 00:00:...| 8827| CLOSED| | 5|2013-07-25 00:00:...| 11318| COMPLETE| | 6|2013-07-25 00:00:...| 7130| COMPLETE| | 7|2013-07-25 00:00:...| 4530| COMPLETE| | 8|2013-07-25 00:00:...| 2911| PROCESSING| | 9|2013-07-25 00:00:...| 5657|PENDING_PAYMENT| | 10|2013-07-25 00:00:...| 5648|PENDING_PAYMENT| | 11|2013-07-25 00:00:...| 918| PAYMENT_REVIEW| +--------+--------------------+-----------------+---------------+
5. Departments Dataframe: In this dataframe, we have department details. It has two columns which are as follows:-
Now we will create a schema and dataframe for the department dataset.
# define schema for department
departments_schema = StructType([
StructField('department_id', IntegerType(), nullable=True),
StructField('department_name', StringType(), nullable=True)])
# create the dataframe
departments_df = spark.read.format(file_type)
.option("sep", delimiter)
.option("header", first_row_is_header)
.schema(departments_schema)
.load(departments_data)
The sample data will look like this:-
+-------------+---------------+ |department_id|department_name| +-------------+---------------+ | 3| Footwear| | 4| Apparel| | 5| Golf| | 6| Outdoors| | 7| Fan Shop| +-------------+---------------+
6. Order Items Dataframe: A collection of information about items ordered on an e-commerce platform or retail store is present in the order items dataframe. It comprises several columns providing details about each order item. The columns in the dataframe are as follows:-
Now we will create the schema and dataframe from the dataset.
# define the schema for order items
order_items_schema = StructType([
StructField('order_item_id', IntegerType(), nullable=True),
StructField('order_item_order_id', IntegerType(), nullable=True),
StructField('order_item_product_id', IntegerType(), nullable=True),
StructField('order_item_quantity', IntegerType(), nullable=True),
StructField('order_item_subtotal', FloatType(), nullable=True),
StructField('order_item_product_price', FloatType(), nullable=True)])
# create the dataframe
order_items_df = spark.read.format(file_type)
.option("sep", delimiter)
.option("header", first_row_is_header)
.schema(order_items_schema)
.load(order_items_data)
The dataframe will look like this:
+-------------+-------------------+---------------------+-------------------+-------------------+------------------------+ |order_item_id|order_item_order_id|order_item_product_id|order_item_quantity|order_item_subtotal|order_item_product_price| +-------------+-------------------+---------------------+-------------------+-------------------+------------------------+ | 2| 2| 1073| 1| 199.99| 199.99| | 3| 2| 502| 5| 250.0| 50.0| | 4| 2| 403| 1| 129.99| 129.99| | 5| 4| 897| 2| 49.98| 24.99| | 6| 4| 365| 5| 299.95| 59.99| | 7| 4| 502| 3| 150.0| 50.0| | 8| 4| 1014| 4| 199.92| 49.98| | 9| 5| 957| 1| 299.98| 299.98| | 10| 5| 365| 5| 299.95| 59.99| | 11| 5| 1014| 2| 99.96| 49.98| +-------------+-------------------+---------------------+-------------------+-------------------+------------------------+
# code orders_df.count() # output:- 68882
To calculate total orders, we have to use the count function.
# solution
avg_revenue = orders_df.join(order_items_df, col("order_id") == col("order_item_order_id"))
.select('order_item_subtotal', 'order_item_order_id')
.select((sum('order_item_subtotal') / countDistinct('order_item_order_id')).alias('avg_rev_per_order'))
avg_revenue.show()
# output:-
+-----------------+
|avg_rev_per_order|
+-----------------+
|597.6374824728177|
+-----------------+
Approach
Output
The average revenue per order is 597.637.
# solution
avg_rev_per_day = orders_df.join(order_items_df, col("order_id") == col("order_item_order_id"))
.select('order_date', 'order_item_subtotal', 'order_item_order_id')
.groupBy('order_date')
.agg((sum('order_item_subtotal') / countDistinct('order_item_order_id')).alias('avg_rev_per_day'))
.orderBy('order_date')
avg_rev_per_day.show(10)
# output:-
+--------------------+-----------------+
| order_date| avg_rev_per_day|
+--------------------+-----------------+
|2013-07-25 00:00:...|590.0334897082785|
|2013-07-26 00:00:...|585.9234878147109|
|2013-07-27 00:00:...|577.5676682063512|
|2013-07-28 00:00:...|551.4119109020958|
|2013-07-29 00:00:...|635.5883909684641|
|2013-07-30 00:00:...|564.5363838698838|
|2013-07-31 00:00:...|630.9955146643533|
|2013-08-01 00:00:...|608.4982189502356|
|2013-08-02 00:00:...|587.8871075517388|
|2013-08-03 00:00:...|599.1628419048382|
+--------------------+-----------------+
Approach:
Output:
The final output displays the average daily revenue.
# solution avg_revenue_per_month = orders_df.join(order_items_df, col("order_id") == col("order_item_order_id")) \ .select('order_date', 'order_item_subtotal', 'order_item_order_id') \ .withColumn("date", to_date(col("order_date").cast("timestamp"))) \ .withColumn("month", month(col("date")))\ .withColumn("year", year(col("date")))\ .groupBy('month', 'year') \ .agg(avg('order_item_subtotal').alias('avg_rev_per_month')) \ .orderBy('month')
avg_revenue_per_month.show() # output +-----+----+------------------+ |month|year| avg_rev_per_month| +-----+----+------------------+ | 1|2014| 199.4031819907084| | 2|2014|197.99513431082633| | 3|2014| 199.4768129569396| | 4|2014|197.84314083932082| | 5|2014|200.16564445417947| | 6|2014|203.19154387871515| | 7|2013|200.12623683619873| | 7|2014|198.73016375184736| | 8|2013|198.25194523225554| | 9|2013|199.70922326100543| | 10|2013|198.59266499428136| | 11|2013| 199.2238976529843| | 12|2013| 199.1285441948526| +-----+----+------------------+
Approach:
Output:
The outcome has the average revenue calculated monthly basis.
# solution
top_perform_dept = orders_df.filter((col("order_status") != 'CANCELED') & (col("order_status") != 'SUSPECTED_FRAUD'))
.join(order_items_df, col("order_id") == col("order_item_order_id"), how='inner')
.join(products_df, col("order_item_product_id") == col("product_id"), how='inner')
.join(categories_df, col("product_category_id") == col("category_id"), how='inner')
.join(departments_df, col("category_department_id") == col("department_id"), how='inner')
.select('department_name', year(col("order_date")).alias('order_year'), 'order_item_subtotal')
.groupBy(col("department_name"), 'order_year')
.agg(sum(col("order_item_subtotal")).alias('total_revenue'))
.orderBy('department_name', 'order_year')
# output
+---------------+----------+------------------+
|department_name|order_year| total_revenue|
+---------------+----------+------------------+
| Apparel| 2013|3090985.6535224915|
| Apparel| 2014| 3917585.841217041|
| Fan Shop| 2013| 7290531.899988174|
| Fan Shop| 2014| 9095735.77280426|
| Footwear| 2013|1711492.5186824799|
| Footwear| 2014| 2122339.649032593|
| Golf| 2013| 1967396.959728241|
| Golf| 2014|2440585.2815055847|
| Outdoors| 2013| 420317.9507675171|
| Outdoors| 2014| 532437.6709976196|
+---------------+----------+------------------+
Approach:
Output:
The final output has all the department’s names with the highest revenues in that particular year.
# solutions
max_pt = products_df.select(max('product_price')).collect()[0][0]
most_expns_product_df = products_df.select('product_id', 'product_category_id', 'product_name', 'product_price')
.filter(col('product_price') == max_pt)
most_expns_product_df.show()
# output
+----------+-------------------+-------------------+-------------+
|product_id|product_category_id| product_name|product_price|
+----------+-------------------+-------------------+-------------+
| 208| 10|SOLE E35 Elliptical| 1999.99|
+----------+-------------------+-------------------+-------------+
Approach:
Output:
The final output contains complete information related to the item with the maximum cost.
Note: We can also use the windows function to answer this question.
# solution
highest_grossing_item = order_items_df.select('order_item_product_id', 'order_item_subtotal')
.groupBy('order_item_product_id')
.agg(F.sum('order_item_subtotal').alias('product_revenue'))
.orderBy('product_revenue', ascending=False)
.limit(1)
.join(products_df, col("order_item_product_id") == col("product_id"), how='inner')
.select('product_id', 'product_category_id', 'product_name', 'product_revenue')
.show(truncate=False)
# output
+----------+-------------------+-----------------------------------------+-----------------+
|product_id|product_category_id|product_name |product_revenue |
+----------+-------------------+-----------------------------------------+-----------------+
|1004 |45 |Field & Stream Sportsman 16 Gun Fire Safe|6929653.690338135|
+----------+-------------------+-----------------------------------------+-----------------+
Approach:
Output:
In final, we get the product that has contributed more in revenue.
# solution
popular_category_df = order_items_df.join(products_df,
col("order_item_product_id") == col("product_id"), how='inner')
.join(categories_df, col("category_id") == col("product_category_id"), how='inner')
.groupBy('category_name')
.agg(F.sum('order_item_quantity').alias('order_count'))
.orderBy('order_count', ascending=False)
.limit(10)
popular_category_df.show()
# output
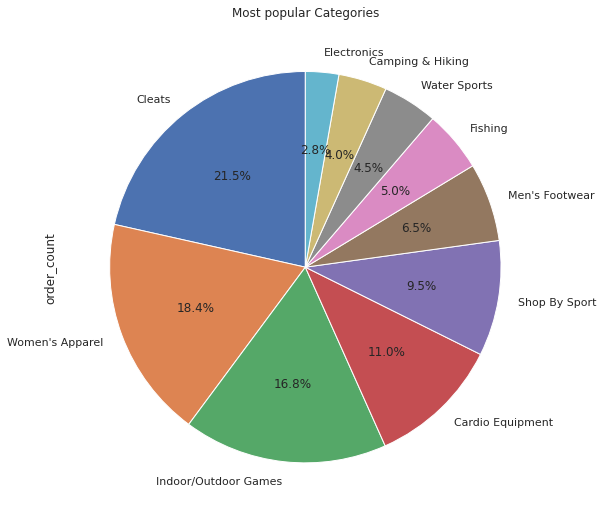
+--------------------+-----------+
| category_name|order_count|
+--------------------+-----------+
| Cleats| 73734|
| Women's Apparel| 62956|
|Indoor/Outdoor Games| 57803|
| Cardio Equipment| 37587|
| Shop By Sport| 32726|
| Men's Footwear| 22246|
| Fishing| 17325|
| Water Sports| 15540|
| Camping & Hiking| 13728|
| Electronics| 9436|
+--------------------+-----------+
Approach:
Output:
The result clearly shows Cleats are the most popular category, with 73734 products sold, followed by Women’s Apparel, Indoor/Outdoor Games, Cardio Equipment, Shop By Sport, etc.
Let’s create a pie chart for better understanding.
# convert it in pandas dataframe pop_cat = popular_category_df.toPandas() # create the pie-chart pop_cat.plot(kind='pie', y = 'order_count', autopct='%1.1f%%', startangle=90, labels=pdf['category_name'], legend=False, title='Most popular Categories', figsize=(9, 9));
# solution
orders_by_status = orders_df.groupBy(col("order_status"))
.agg(count(col("order_status")).alias("total_status"))
orders_by_status.show()
# output
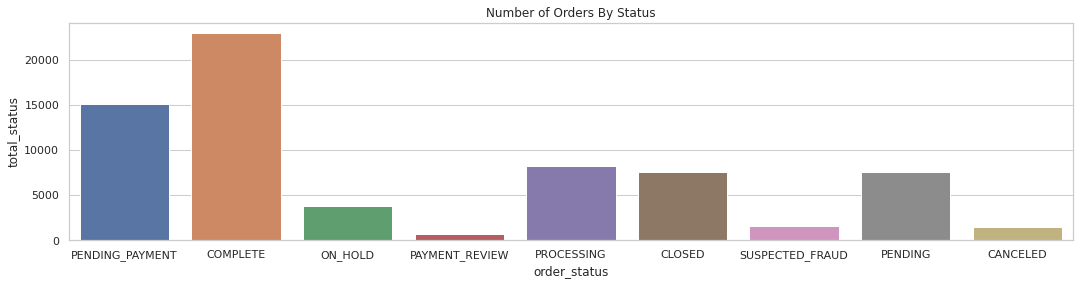
+---------------+------------+
| order_status|total_status|
+---------------+------------+
|PENDING_PAYMENT| 15030|
| COMPLETE| 22899|
| ON_HOLD| 3798|
| PAYMENT_REVIEW| 729|
| PROCESSING| 8275|
| CLOSED| 7555|
|SUSPECTED_FRAUD| 1558|
| PENDING| 7610|
| CANCELED| 1428|
+---------------+------------+
Approach:
Output:
Now we will plot the data on a graph for better understanding.
# convert it in pandas dataframe
order_stat = orders_by_status.toPandas()
# plot the data using barplot
g = sns.barplot(x='order_status', y='total_status', data=order_stat)
g.set_title('Number of Orders By Status');
# solution
cancelled_orders = orders_df.filter(col('order_status') == 'CANCELED')
.join(order_items_df, col("order_id") == col("order_item_order_id"))
.groupBy("order_id", "order_date", "order_customer_id", "order_status")
.agg(sum('order_item_subtotal').alias('order_total'))
.filter(col('order_total') >= 1000)
.orderBy('order_id')
cancelled_orders.show(10)
# output
+--------+--------------------+-----------------+------------+------------------+
|order_id| order_date|order_customer_id|order_status| order_total|
+--------+--------------------+-----------------+------------+------------------+
| 753|2013-07-29 00:00:...| 5094| CANCELED| 1129.75|
| 2012|2013-08-04 00:00:...| 5165| CANCELED|1499.8600311279297|
| 2144|2013-08-05 00:00:...| 7932| CANCELED| 1099.900032043457|
| 2189|2013-08-06 00:00:...| 6829| CANCELED|1029.9400253295898|
| 2271|2013-08-06 00:00:...| 7603| CANCELED|1229.9300231933594|
| 2754|2013-08-09 00:00:...| 8946| CANCELED|1109.9500274658203|
| 3551|2013-08-14 00:00:...| 5363| CANCELED|1299.8700408935547|
| 4354|2013-08-20 00:00:...| 7268| CANCELED|1047.9000244140625|
| 4801|2013-08-23 00:00:...| 11630| CANCELED|1016.9500217437744|
| 5331|2013-08-26 00:00:...| 3361| CANCELED|1229.8100204467773|
+--------+--------------------+-----------------+------------+------------------+
Approach:
Output:
# solution
order_more_than_five = orders_df.filter((col('order_status') != 'CANCELED') & (col('order_status') != 'SUSPECTED_FRAUD'))
.filter((F.year('order_date') == 2013) & (F.month('order_date') == 8))
.join(order_items_df, col("order_id") == col("order_item_order_id"), how='inner')
.join(customers_df, col("order_customer_id") == col("customer_id"), how='inner')
.select('customer_id', 'customer_fname', 'customer_lname', 'order_id')
.groupBy('customer_id', 'customer_fname', 'customer_lname')
.agg(count('order_id').alias('order_count'))
.where(col('order_count') > 5)
.orderBy(col('order_count'), col('customer_id'), ascending=[0, 1])
# output
+-----------+--------------+--------------+-----------+
|customer_id|customer_fname|customer_lname|order_count|
+-----------+--------------+--------------+-----------+
| 791| Mary| Smith| 15|
| 5047| Shirley| Whitehead| 14|
| 5477| Mary| Smith| 14|
| 6088| Mary| Brooks| 14|
| 9371| Mary| Patterson| 14|
| 3295| Maria| Joseph| 13|
| 3536| Mary| Tanner| 13|
| 4582| Brian| House| 13|
| 5865| David| Middleton| 13|
| 8069| Tiffany| Mcdaniel| 13|
+-----------+--------------+--------------+-----------+
Approach
Output:
The resulting DataFrame will have all the customers who placed more than five orders in August 2013, along with their names and order count. This information helps identify the most active customers and take action to retain them and increase sales.
In this article, we solve a case study utilizing retail data to uncover hidden insights that can increase sales using PySpark. This analysis allows the store manager to understand which products require more attention. The insights gained from the data can assist in tracking individual product performance, identifying top-selling items, and adjusting inventory levels accordingly. Retailers can also use sales data to analyze customer purchasing patterns and make informed decisions about product placement, promotions, and pricing strategies.
Some Important Takeaways from this article are as follows:-
This case study helps you better understand the PySpark functions. If you have any opinions or questions, then comment down below. Connect with me on LinkedIn for further discussion. Keep Learning!!!
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Lorem ipsum dolor sit amet, consectetur adipiscing elit,








Hi Kishan, Great share, very informative! Lot to understand, but explained clearly! Thank you