Knowledge Graphs: Deep Dive into its Theories and Applications
Introduction
Let me share a story with you. Years back, when the data team of the International Consortium of Investigative Journalists (ICIJ) received a dump of data that today we know as the Panama Papers, they would probably have thought it to be a futile endeavor. With that massive amount of complex data, it should have appeared to be an overwhelming call of duty for the knowledge workers! To quote ICIJ, the Panama Papers is a “giant leak of more than 11.5 million financial and legal records exposes a system that enables crime, corruption, and wrongdoing, hidden by secretive offshore companies.” The rouge offshore financial scandals that we have been reading about in the news since 2015 were the efforts of the team of ICIJ to leverage the power of knowledge graphs (KG) that gave context and connection to the data. The complex, multi-year multimedia data in Knowledge Graphs were linked so investigators could walk through the connections to unravel some of the biggest scandals of the past.

Source: Panama Papers
Now that we are familiar with the potential of KGs let’s see what is there for us! By the end of this article, I promise to leave you with a detailed understanding of the concepts behind KGs, why, where, and how we can use KGs.
Learning Objectives
This article’s learning goal is to make our data more intelligent and smart using a technique called Knowledge Graphs. KGs score brownie points over the rest of the normal graphs because of the addition of organizing techniques. The article also explores how to find knowledge graphs in the real world and help you build one.
This article was published as a part of the Data Science Blogathon.
Table of contents
- Introduction
- What is a Knowledge Graph?
- Organizing Principles of a Knowledge Graph
- KGs Using Taxonomies for Hierarchy
- Knowledge Graphs Using Ontologies for Multilevel Relationships
- How to Implement Knowledge Graphs?
- Where would you Find Knowledge Graphs in the Real World?
- Frequently Asked Questions
- Conclusion
What is a Knowledge Graph?
A knowledge graph is a structured representation of knowledge that uses a graph-based data model. It organizes information into nodes and edges, where nodes represent entities or concepts, and edges denote relationships between them. Knowledge graphs enable efficient storage, retrieval, and inference of interconnected knowledge, facilitating advanced search, analysis, and reasoning tasks.
Most of us know that graphs in the computation are a pleasant and flexible way of data modeling that supports various complex algorithms and data science and computation. But what differentiates KGs from graphs is the application of an organizing principle that helps humans and software to interpret it quickly. So rather than repeatedly encoding intelligent behavior into applications, we directly encode it into the data once and for all! KGs results from decades of research into semantic computation, but with the advent of modern graph computations, they can be easily extended into real-world problems.
Thus we can say the KGs are structured knowledge bases that represent real-world entities and the relationships between them. Most KGs store this knowledge in triplets known as Subject-Predicate-Object (SPO) format, which aligns with the Resource Description Framework (RDF) standards. The existence of a particular SPO triplet indicates that the respective triplets possess a relationship of a specific type. For example, consider the following knowledge.
“Leonard Nimoy was an actor who played the character Spock in the science-fiction movie Star Trek.”
A sample knowledge graph of the following is shown in the figure below. Here the nodes represent entities, the edge labels represent types of relations, and the edges themselves represent existing relationships.
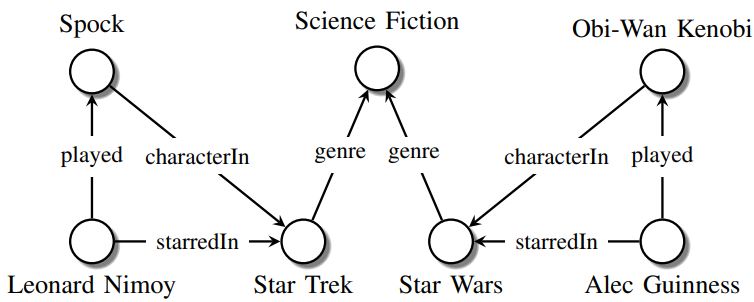
Source: arxiv.org
While the SPO triplets that can be extracted from the given knowledge are shown below:
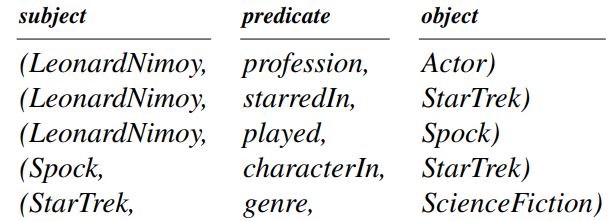
Source: arxiv.org
Now we understand the structure of KGs. Next, we would look into the organizing principles of KGs, which bring out their essence and differentiate it from typical graphs.
Organizing Principles of a Knowledge Graph
There are several ways to organize data in graphs, each with advantages and drawbacks. In this section, we will be discussing each of the organizing hierarchies. We would start with plain simple graphs and try to explain how adding successive layers of organization helps make the data smart and more interpretable, thereby helping solve increasingly sophisticated problems.
Plain Old Graphs
These are graphs that haven’t had any organizing principle applied to them. Still, we know that they help solve our daily challenges as they underpin some very important systems. Instead of associating the “organizing principles”‘ with the data, the programs and systems that consume these graph data are embedded with the “organizing principles.”
A typical example of the same would be the sales of an online store. The figure below shows a small portion of the sales and product catalog graph, showing the customers and their purchases in the form of a plain old graph.
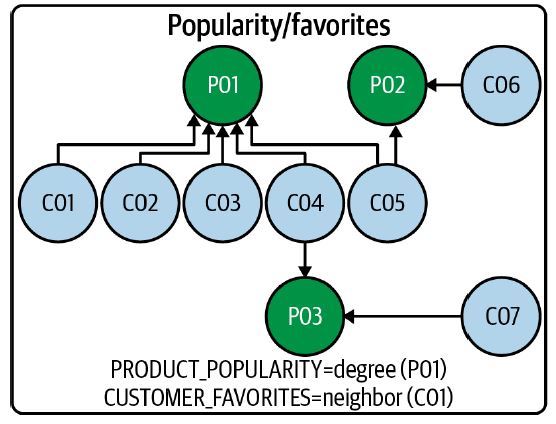
Source: neo4j.com
Looking straight into the graph might not be intuitive. Still, when the knowledge that P nodes represent products, C nodes represent customers, and the connections between the nodes represent purchases are encoded into the program, it would be easy to answer questions like products that a particular customer bought and vice versa or computing the popularity of the product. There is no doubt to the fact that these kind of graph information are helpful and does help compactly provide data, but in cases when data scientists with no prior knowledge of the domain try to dry run the code, then either someone will have to explain how to read the data, or he might have to reverse engineer the codes to understand how to interpret the data. Thus a better solution is to make the data smart by applying some organizing principles to the graphs, which we will see in the following three subsections.
Richer Graph Models
The first organizing principle that we would see is the property graph model. It is richer and far more organized and supports labeled nodes, types, and directions of relationships and properties (key-value pairs) on both nodes. Thus it can provide humans and machines with some essential clues about the information it contains. Thus this organizing style makes the graph self-descriptive to a certain level and is a clear step towards making the data smarter! Also, some preprocessing and visualizations can be carried out without any domain knowledge just by leveraging the features of property graph models.
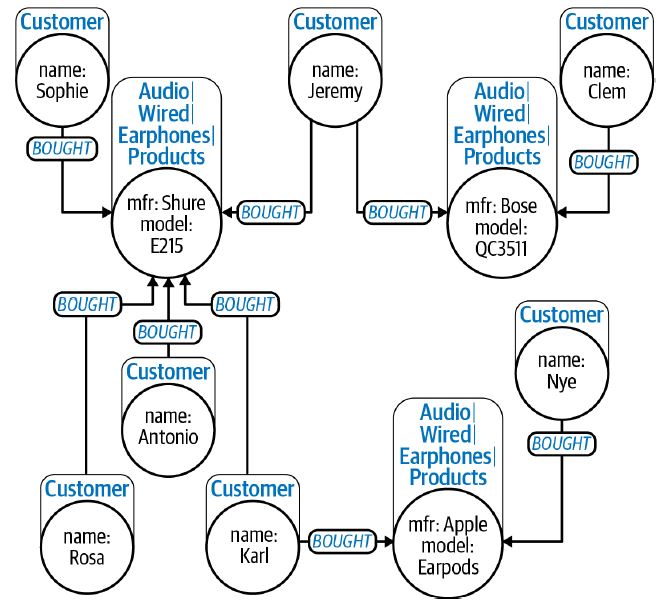
Source: neo4j.com
The figure above shows an enriched view of sales and product catalogs, which include labels, properties, and named relationships.
KGs Using Taxonomies for Hierarchy
In the above “organizing principle,” we saw that creating categories of nodes using labels is evidently useful. Still, on deeper thought, it may be realized that the associativity between the labels is missing!
Continuing our sales product catalog, a good way to proceed would be to enrich the product classification with some “higher order organizing principle”, so that even if the shopkeeper is out of stock with a particular product, he might be able to win a sale by suggesting some similar product. We need a taxonomy to support this kind of “x is a kind of y” reasoning.
Taxonomy is a classification scheme that allows a broader-narrower hierarchy. Items sharing similar properties are grouped in the same category, and the taxonomy helps relate one category to other globally. This kind of hierarchy allows positioning specific things like products at the bottom, and more general things like brands and products are placed towards the top of the hierarchy. The hierarchy in this type of “organizing principle” is constructed with category nodes connected by subcategory_of relationships. And the products are connected to the appropriate part of the taxonomy to classify them as ready for sale. The same is shown in the figure below.
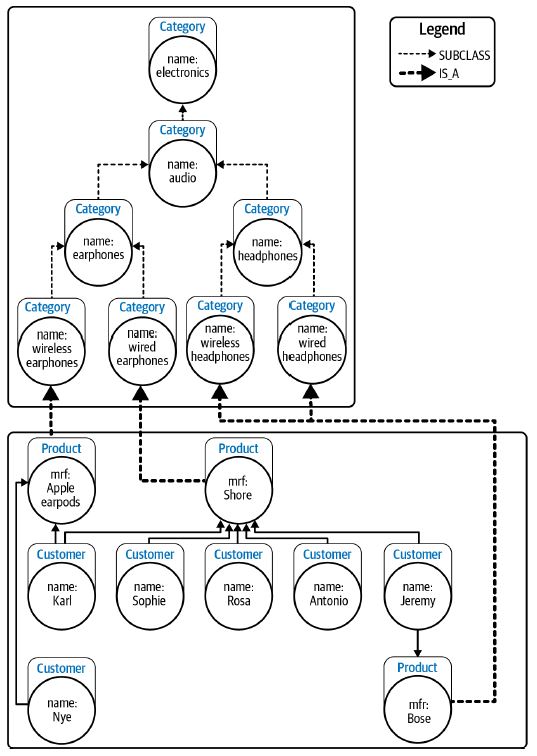
Source: neo4j.com
The figure above shows the product catalog hierarchy layered on top of customer and sales data. This enables a more organized visualization of the data. An even more interesting fact is that we can provide multiple hierarchical organizations simultaneously to help provide even more insight into the data.
Knowledge Graphs Using Ontologies for Multilevel Relationships
Taxonomies help organize by bringing in the subcategory_of relations; Ontology allows define more complex relationships between categories like part_of, compatible_with, and depends_on. Thus following the ontological instructions, we can not only explore the categories vertically (hierarchically), but it also allows for horizontal comparison. Besides this, they can be built in a modular fashion to make them more compact with sophisticated use of layering. Thus ontology helps make knowledge actionable. The figure below is an ontological representation showing the upgrade paths for products in a category.
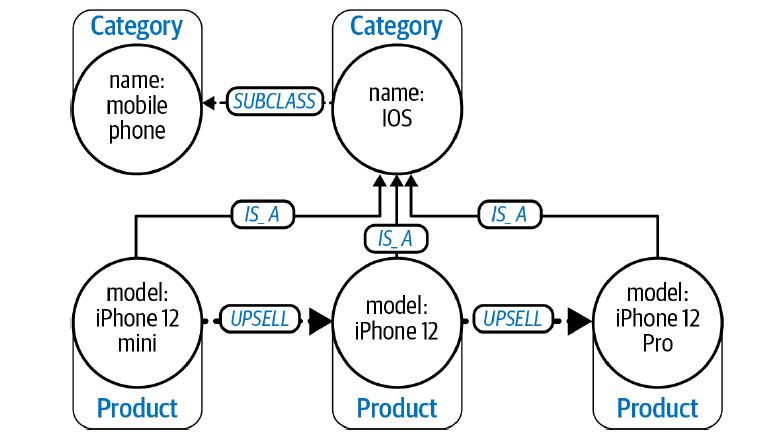
Source: neo4j.com
Thus till now, we have seen different types of organizing principles of KG. However, the organizing principle we choose to use should always be driven by its intended usage. It is advisable not to build rich and overcomplicated features into the organizing principles if no associate processes or agents would use them. It is a common mistake to opt for an overly ambitious organizing principle as it would be costly in terms of resources and time.
How to Implement Knowledge Graphs?
Now that we have understood KGs and the different organizing principles, the next question is how to implement them. Implementing KGs typically involves the following steps:
- Data Collection
The first step is collecting data from structured/ unstructured databases or text or multimedia data from images and videos.
- Pre-Process the Collected Data
The next step would be to pre-process it to remove irrelevant and redundant information to ensure that data is in a format that can be readily utilized for building the KGs
- Extract Entities and Relationships
The third step is to extract the entities and relationships from the data. Named Entity Recognition, relationship extraction, and object detection can achieve this.
- Construct Knowledge Graph
Once the entities and relationships have been extracted, the next step is constructing the knowledge graphs. Graph databases like Neo4j or Titan can achieve this.
- Populate KG with Extracted Entities and Relationships
Then, follow it by populating the KG with extracted entities and relationships.
- Unlocking Knowledge
Once KG has been constructed, it can be queried to achieve useful information.
- Ensuring Accuracy and Relevance:
Finally, the KG should be regularly maintained, updated with new data, and monitored for errors.
It is noteworthy to mention that these steps are not discrete and may vary depending on the specific use case and technology. Additionally, libraries and frameworks like OpenAI, GPT 3, and Google’s Tensor can help with the steps.
Where would you Find Knowledge Graphs in the Real World?
Now we know how to build KG, it would be interesting for you to be aware of the usage of KG.
- Fraud Detection – Representing fraud scenarios in a graphic visual way, which is the core of a knowledge graph, allows financial consultants to identify to extend their machine learning algorithm work to consider even more heterogeneous datasets that might not be directly related to the topic in hand, or reconsider features and variables that traditional machine learning capabilities can ignore. If your machine learning algorithms have determined them as non-fraud, it is most likely that they’re not. For example, the previous model didn’t account for email addresses as a valuable feature in determining fraud. But if two customers have the same email address, that might raise a red flag: they might be the same person. In this case, an email address is related to an entity (customer) connected to another customer through the same email address.
- Data Governance – As various divisions within a financial company generate new data over time, the data differences that occur lead to inconsistent quality and lack of usefulness to the overall organization. Graphs act as a semantic layer, modeling metadata and adding rich descriptive meaning to data elements.
The combined metadata and relationships form a semantic layer that fully describes the meaning of the data and allows for visualization of all the data in their granularity. By visualizing the data, knowledge graphs allow a user to identify duplicate or inconsistent data, as this data will have an interconnected relationship with other entities. Finally, the patterns seen from the relationships can help the organization develop analytics to understand the usability of the data. - Managing Information – KGs also have their applicability in the field of finance. Thomson Reuters launched its first knowledge graph in 2017 to provide a comprehensive view of the financial ecosystem and help organizations streamline their “investments, targets and prospects.”
Their knowledge graph brings together information about organizations, people, instruments and quotes, supplier-customer filings and reports, metadata and taxonomies, M&A deals, etc. It allows financial organizations to use it as a base for research projects, risk assessments, etc. - Insider Trading – involves exchanging information between two or more individuals or entities. Investigators working on insider trading schemes have to go through different types of data looking for relationships and information leaks to reach the desired person. Traditionally, the SEC and other government agencies examine sources such as phone calls, messages, email exchanges, and open-source information and combine them all to find new patterns. As you can imagine, using traditional methods can complicate this process. The Knowledge Graph allows us to represent all of these different data sources, enables pattern recognition even in the smallest of relationships, and is constantly fed with new information as it arrives.
Frequently Asked Questions
A. Yes, knowledge graphs are closely related to Natural Language Processing (NLP). They can be used in NLP tasks such as information retrieval, question answering, entity linking, and semantic parsing. Knowledge graphs provide a structured representation of knowledge that can enhance the understanding and processing of natural language text.
A. The use of knowledge graphs is diverse and extensive. They facilitate organizing, integrating, and representing complex knowledge from various sources in a structured and interconnected manner. Knowledge graphs enable advanced search, recommendation systems, question answering, semantic analysis, entity linking, data integration, and machine learning tasks. They enhance data understanding, reasoning, and decision-making by providing a comprehensive and interconnected view of information.
Conclusion
While I hope I have successfully sufficed your craving for knowledge for today, I want to leave you with some parting information. I want to introduce you to something called “Scene Graphs.” A scene graph(SG) differs from KG because SG extracts SPO from images and videos. Knowledge graphs are used to represent real-world entities and their relationships and are used to represent information in a structured format in a general sense. They can represent structures such as people, things, and concepts. Scene graphs, on the other hand, are used to embody objects, attributes, and spatial relationships between objects (containment, proximity, actions, etc.) in images and videos (3D environments).
Thus today, we have looked deeply into making our data more intelligent and smart. The technique that we utilized for the same is Knowledge Graphs. To briefly summarized today’s read, the key takeaways for you in this article would be:
- How Knowledge Graphs differ from normal graphs because of the addition of “organizing techniques.”
- We then looked into each of the organizing techniques in depth, explaining each case with our analogy of online sales of a shop.
- We followed it by building Knowledge Graphs and where we can find them in the real world.
- Finally, we ended with some additional information on Scene Graphs which are leveraged when we come across image and video data.
I hope you had a good read till here. If you enjoyed it, do stay tuned for my upcoming blogs! I wish you happy learning!
References:
- Knowledge Graphs Data in Context for Responsive Business – by Jesús Barrasa, Amy E. Hodler, and Jim Webber
- Beginners Guide to Knowledge Graphs and Scene Graphs – by Asad Haider Rizvi
- Knowledge Graph Representational and Applications in AI – by Parishad Behnam Ghader
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.







