Basics of Big Data and Hadoop- Beginner’s Guide
Introduction
In this technical era, big data and hadoop is proven as revolutionary as it is growing unexpectedly. According to the survey reports, around 90% of the present data was generated only in the past two years. Big data is nothing but the vast volume of datasets measured in terabytes or petabytes or even more.
Big data helps multiple companies to know their products and services better and generate valuable insights about them. Big Data technology is expanding in every field, and it can be used to refine the industry’s marketing campaigns and techniques, as well as it is helping in the expansion of Artificial Intelligence (AI) segments and automation.
Nowadays, employment opportunities are immense as every business worldwide seeks requirements for Big Data professionals to streamline and manage their business services. Employers can easily fetch the job by showing their strong knowledge and interest in data and the market. Big Data offers various positions like Data Analyst, Data Scientist, Database administrator(DBA), Big Data Engineer(BDA), Hadoop Engineer, etc.
Learning Objectives
- Understand Big Data to set a pace for a strong career as a Big Data analyst.
- Have a deep knowledge of big data and its types.
- Know the essential V’s in big data and their importance.
- Learn about the use cases and applications of big data and Hadoop.
- Understand how Hadoop is used in big data.
This article was published as a part of the Data Science Blogathon.
Table of contents
Understanding the Term: Big Data
Big Data is associated with extensive and often complicated datasets, which are vast enough that conventional relational databases can’t handle. They need special tools and methodologies to perform operations on a huge data collection. Big Data consists of structured, semi-structured, and unstructured datasets like audio, videos, photos, websites, etc. There are n-number of sources from which we are getting these data. Some of the data sources are:-
- Email tracking
- Server logs
- Smartphones & Smartwatches
- Internet cookies
- Social media
- Medical records
- Machinery sensors & IoT Devices
- Online purchase transaction forms
Businesses are collecting these unstructured and raw datasets daily, and to manage this data and understand their businesses better, they need Big data technology. Big data manage the datasets by extracting meaningful information, which helps industries to make better business decisions backed by data.
Let’s understand the working of Big Data as a three-step process!
- Integration: is the first step of working, which involves collecting data from various heterogeneous sources. It merges the collected data and molds it into a format that can be analyzed in such a way as to provide business insights.
- Management: After collection, the data must be carefully managed to be mined for valuable information and transformed into workable insights. The huge amount of Big Data is unstructured, so we can’t store it in conventional relational databases, which store data in tabular format.
- Analysis: In this analysis phase, data is mined, and data scientists often use advanced technologies such as machine learning, deep learning, and predictive modeling to examine large datasets and gain a deeper understanding of the data.
Different Types of Big Data
Three types of Big Data are structured, semi-structured, and unstructured. Let’s understand each one of them!

Structured Data: As the name suggests, data is highly organized data that follows a specific format to store and process data. We can easily retrieve the data as the attributes are arranged, e.g., mobile numbers, social security numbers, PIN codes, employee details, designation details, and salaries. Data stored in RDBMS(Relational database management) is an example of structured data, and we can use SQL (Structured Query Language) to process and manage such kind of data.
Unstructured Data: As the name suggests, unstructured data is highly unorganized data that does not follow any specific structure or format to store and process data. It can’t be stored in RDBMS, and we can’t even analyze it until it is transformed into a structured format. Unstructured data is the highest generating data daily, and it is available in multiple formats such as images, audio, video, social media posts, surveillance data, online shopping data, etc. According to experts, around 80% of the data in an organization is unstructured.
Semi-structured Data: Semi-structured data is a combination of structured and unstructured data which doesn’t have a specific format but has classifying characteristics associated with it. For example, videos and images may contain internal semantic tags or metadata or markings related to the place, date, or by whom they were taken, but the information within has no structure. XML or JSON files are common examples of semi-structured data.
The 5 V’s in Big Data
The term 5 V’s in Big data represents:

- Volume: Volume is nothing but the humungous amount of data that is growing at a high rate. Nowadays, data volume is in terabytes, petabytes, or even more. This huge volume of data is stored in warehouses and needs to be examined and processed. The data is so vast that we can’t store it in relational databases. We need distributed systems like Hadoop and MongoDB to store the parts of data in multiple locations and brought together by software.
- Velocity: Velocity is the rate at which vast amounts of data are generated, stored, and analyzed. Velocity shows the pace at which data is being generated in real-time. We can take the example of social media, which generates audio, videos, posts, etc., every second. Hence, unstructured data is increasing at lightning speed around the world.
- Variety: Variety means the different types of data we use daily. In the past, data was very simple and could be stored in a structured format(name, mobile number, address, email id, etc.), but now data is very different. Now we have a variety of data that can be structured, unstructured, and semi-structured, collected from varied sources. We need specific analyzing and processing technologies with innovative and suitable algorithms to handle the data in various formats like text, audio, videos, etc.
- Veracity: Veracity is nothing but the quality or trustworthiness of available data. Data veracity deals with the accuracy and certainty of the data analyzed. For example, Twitter is generating posts per second with hashtags, spellings, abbreviations, typos, etc., and this tons of data is useless if we can’t trust the accuracy and quality of the data.
- Value: Raw data is produced daily, but it is useless. We have to convert it into something valuable to extract helpful information. We can consider the data valuable if we produce a meaningful investment return.
Different Approaches to Dealing with Big Data
Big Data is proven to be an extraordinary competitive arm to a business over its competitors; a business can decide how it wants to utilize the capabilities of big data. Organizations can streamline the various business activities per their objectives and use the potential of Big Data as per their requirements.
The basic approach to dealing with Big Data is based on the needs/demands of the business and the available budgetary provisions. Firstly we have to decide what problem we are solving, what kind of data we need, what we want from our data to answer, and what we want to achieve from that. After this, we can go with the below approaches for Big Data processing.
- Batch processing: In batch processing, we collect similar data, group it(called batch), and feed it into an analytics system for processing. We can use batch processing when we have to process a high volume of data, and the data size is known and finite.
- Stream processing: In stream processing, we process a continuous stream of data immediately as it is produced, and the processing is usually done in real time. We can use stream processing when the data stream is continuous and requires immediate response and the data size is unknown and infinite.
Top 3 Use Cases of Big Data and Hadoop
Netflix
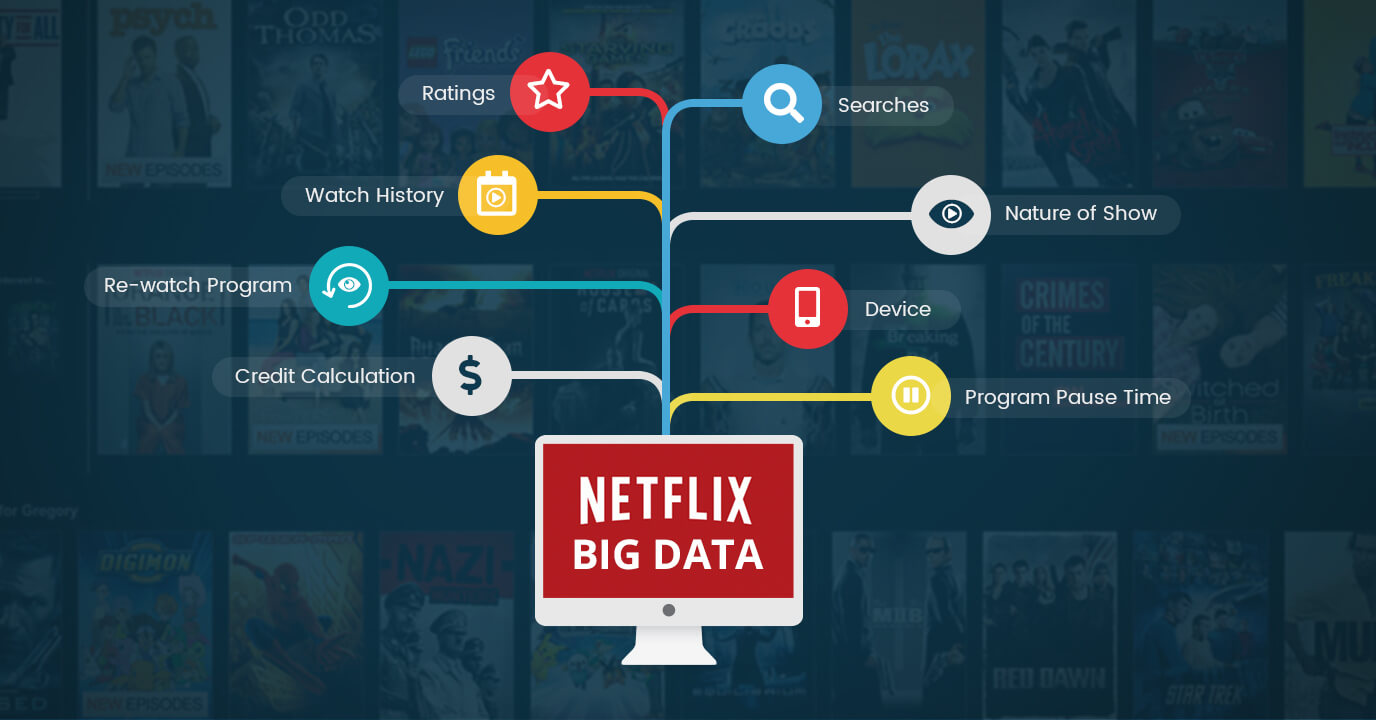
Netflix is a world-famous entertainment company that offers high-quality on-demand streaming video for its users.
Netflix is setting up the pace in the market by providing its users with the exact content they enjoy. But do you know how Netflix knows what you like? The answer is obvious using Big Data Analytics.
Netflix is using Big data analytics to build its highly accurate recommendation system and satisfy the user’s demand.
Thinking, how?
Netflix analyzes our data about what we’re watching or searching, extracting the data points from that, like what titles customers watch, what genre they like, how often playback stopped, ratings are given, etc., and feeding that to its recommendations system. This will make decisions smooth and firm in terms of knowing the customers’ needs rather than assuming them (what most companies do).
The major data structures used in this process include Hadoop, Hive, Pig, and other traditional business intelligence.
Uber
Nowadays, we can’t imagine our life without Uber; wherever we want to go, Uber is just a click away, and we can also use it to send deliverables.
Now you might be thinking about how Uber is using our data or the role of big data in Uber.
So, let’s think first, you often went to the same places, but did you pay the same amount every time? The answer is obviously no.
This is how Uber is using our data. Uber put its focuses on the demand for the services and supply to manage the prices of the provided services.
Surge Pricing is the major benefit of big data taken by Uber. For instance, if you’re looking for a cab to a railway station or airport, you are ready to pay whatever amount it asks, and Uber understands this criticality of time and increases the prices. Or even on festival days, you will see an increase in prices.
Walmart
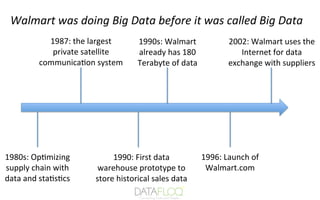
Walmart is the world’s largest retailer and revenue giant, with over 2 million employees and 20,000 stores across 28 countries.
Walmart has been using Big data analytics for years, even when we didn’t know the term “big data.” It is discovering data patterns, providing product recommendations, and analyzing customer demands using Data Mining.
This usage of analytics helps Walmart increase its customer conversion rate, optimize its shopping experience, and provide the best-in-class e-commerce technologies to deliver a superior customer experience.
Walmart uses technologies like NoSQL and Hadoop to provide internal users with access to real-time data collected from various sources and centralized for effective use.
The Use of Hadoop in Big Data
Big data consists of volumes of various types of data, which can be in unstructured and structured data generated at high speed. Big Data can be considered an asset, and we need a tool to deal with that asset. Hadoop is a tool used to deal with the issue of storing, processing, and analyzing big data. Hadoop is an open-source software program used to process, store, and analyze complex unstructured data sets and run applications on clusters of commodity hardware. It provides massive storage for any data and makes it easy as it is distributed across multiple machines and processed parallelly.
Let’s discuss some of the commonly used Hadoop commands to understand how Hadoop handles big data in a better way!
1. The Mkdir Command in Hadoop
The mkdir stands for “make directory”; the command creates a new directory with a given name in the specified path of the Hadoop cluster; the only constraint is that the directory should not already exist. If the directory with the same name is present in the cluster, it will generate an error signifying the directory’s existence.
Syntax:-
Hadoop fs -Mkdir /path_name/directory_name2. The “Touchz” Command in Hadoop
The “Touchz” command in Hadoop is used to create a new empty file with a given name in the specified path of the Hadoop cluster. This command only works if the given directory exists otherwise, it won’t create any file and instead show an error signifying the directory’s absence in the cluster.
Syntax:-
Hadoop fs -touchz/directory_name/file_name3. LS Command in Hadoop
LS stands for list in Hadoop; the command displays the list of files/contents available in the specified directory or the path. We can add various options with the ls command to get more information about the files or to get information in a filtered format, for example:
- -c: We can use the “-c” option with the “ls” command to get the full address of the files or directories.
- -R: This option is used when we want the content of directories in a recursive order.
- -S: This option sorts the files in the directory based on their size. So, whenever we want the file with the highest or the lowest size, we can go with this function.
- -t: This is also the most commonly used option with the “ls” command because it sorts the file based on the modification time, which means it puts the most recently used file in the first position of the list.
Syntax:-
Hadoop fs -ls/path_name4. Test Command in Hadoop
As the name suggests, this command is used to test the existence of a file in the Hadoop cluster, and it will return “1” only if the path exists in the cluster. This command uses multiple options like “[defsz]”, let’s understand them!
Syntax:-
Hadoop fs -test -[defsz]Options:-
- -d: This option tests whether the path provided by the user is a directory or not, and if the path is a directory, it will return “0”.
- -e: This option tests whether the path provided by the user exists, and if the path exists in the cluster, it will return “0”.
- -f: This option tests whether the path provided by the user is a file or not, and if the given path is a file, it will return “0”.
- -s: This option tests whether the path provided by the user is empty, and if the path is not empty, it will return “0”.
- -r: This option tests whether the path provided by the user exists or not and whether it is granted with read permission. It will only return “0” if the path exists and read permission is also granted.
- -w: This option tests whether the path the user provides exists and whether it is granted with written permission. It will only return “0” if the path exists and write permission is also granted.
- -z: This option tests whether the size of the given file is zero bytes or not, and if the file size is zero bytes, it will return “0”.
5. Find Command in Hadoop
As the name suggests, this command is used to search the files present in the Hadoop cluster. It scans the specified expression in the command with all the files in the cluster and returns the files that match the defined expression. If we didn’t specify the path explicitly, it took the present working directory by default.
Syntax:-
Hadoop fs -find ..6. Text Command in Hadoop
The text command in Hadoop is mainly used to decode the zip file and display the source file’s content in text format. It encodes the source file, processes it, and finally decodes its content into plain text format.
Syntax:-
Hadoop fs -text7. The Count Command in Hadoop
As the name suggests, this command counts the number of files, directories, and bytes under the specified path. We can use the count command with various options to modify the output as per our requirements, for example:
- -q – This option is used to show the quota, which means the limit on the total number of names and usage of space used for individual directories.
- -u – This option displays only the quotas and usage.
- -h – This option displays the file sizes in a human-readable format.
- -v – This option is used to display the header line.
Syntax:-
Hadoop fs -count [option]8. GetMerge Command in Hadoop
As obvious as its name, the Getmerge command merges one or multiple files in a specified directory on the Hadoop cluster into a single local file on the local filesystem. The words “src_dest” and “local_dest” in syntax represent the source and local destinations.
Syntax:-
Hadoop fs -Getmerge9. AppendToFile Command in Hadoop
This shell command is used to append the content of single or multiple local files into a single file onto the provided destination file in the Hadoop cluster. While executing this command, the given local source files are appended to the destination source based on the filename given in the command. Also, if the destination file is not in the directory, it will create a new file with that name.
Syntax:-
Hadoop fs -AppendToFileConclusion
This blog covers some important Big Data topics that will help you start your career in big data analysis. Using these beginner topics as a reference, you can better understand the concept of big data and Hadoop, which will help you prepare for interviews and set a pace for becoming a data analyst, Hadoop developer, data scientist, etc. The key takeaways from this data blogs are:
- Big Data is a non-conventional strategy mainly used by businesses and organizations to understand their products or services and gain valuable insight from that.
- We discussed the various data types generated from multiple sources like social media posts, emails, cell phones, credit cards, etc.
- We discussed the 5 V’s of Big data, which includes:
- Volume:- Amount of data we have.
- Velocity:- Speed by which data is created, moved, or accessed.
- Variety:- The different types of data sources we have.
- Veracity:- How trustable is our data?
- Value:- The meaningful return our data is providing on investment.
- We also discussed stream and batch processing in big data.
- We discussed a bit about Hadoop, a Java-written framework used to handle the massive amount of data optimally.
- At last, we discussed some of the commonly used Hadoop commands with their syntaxes.
Frequently Asked Questions
A. Big Data refers to vast volumes of structured, semi-structured, and unstructured data that cannot be processed effectively using traditional database management tools. It is significant because it enables organizations to derive valuable insights from large datasets, leading to informed decision-making and improved business strategies.
A. Big Data is categorized into structured, semi-structured, and unstructured data. Structured data follows a specific format and is easily searchable, while unstructured data lacks a predefined format and requires advanced analytics for interpretation. Semi-structured data falls between these two categories, containing some organizational properties but lacking the structure of fully structured data.
A. The “5 V’s” of Big Data refer to Volume, Velocity, Variety, Veracity, and Value. These characteristics describe the volume, speed, diversity, reliability, and usefulness of data, respectively. Understanding the “5 V’s” helps organizations comprehend the challenges and opportunities associated with managing and analyzing large datasets effectively.
A. Hadoop is an open-source framework designed to store, process, and analyze large volumes of data in a distributed computing environment. It provides scalable and cost-effective solutions for handling Big Data by leveraging clusters of commodity hardware. Hadoop’s distributed file system (HDFS) and MapReduce programming model enable parallel processing of data, making it suitable for various Big Data applications.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.







