Introduction
A game-changing innovation has arrived in AI‘s fast-evolving landscape, reshaping how machines engage with human language. Enter Retrieval Augmented Generation (RAG), a fusion of retrieval and generation models in NLP. RAG isn’t just a tech buzzword; it’s revolutionizing human-machine communication. Join us as we uncover the secrets of RAG, explore its applications, and its profound AI impact. RAG is at the forefront of NLP, seamlessly merging retrieval and generation for a transformative AI approach, enhancing how machines grasp and interact with human language.
Learning Objectives
- Grasp the foundational concepts of retrieval-based and generation-based models in Natural Language Processing (NLP), including their applications, differences, and similarities.
- Analyze the limitations of pure retrieval or generation models in NLP, exploring real-world examples.
- Understand the scenarios where this integration is essential and recognize the importance of bridging retrieval and generation models in NLP.
- Dive into the Retrieval Augmented Generation (RAG) architecture and understand its components.
- Develop practical skills in implementing RAG, including generating embeddings and understanding the aspects of transparency and accuracy.
This article was published as a part of the Data Science Blogathon.
Table of contents
- Introduction
- Understanding Retrieval and Generation
- Key Differences and Similarities
- Limitations of Purely Retrieval or Generation Models
- Real-World Examples Showcasing the Limitations of Traditional NLP Methods
- What is the Need for Bridging Retrieval and Generation?
- Architecture of RAG
- How does RAG Work?
- What are the Components of RAG?
- RAG for Large Language Models
- Implementing RAG: Code Demonstration
- RAG to Promote Transparency and Avert LLM Hallucinations
- Generating Embeddings for RAGs
- Customizing Retrieval Methods: Enhancing Precision
- Fine-Tuning for Mastery: Elevating RAG with Your Data
- Conclusion
- Frequently Asked Questions
Understanding Retrieval and Generation
Let’s delve into the understanding of retrieval-based and generation-based models and the key differences and similarities between these approaches in natural language processing.

Retrieval-Based Models in NLP
Retrieval-based models in NLP are designed to select an appropriate response from a predefined set of responses based on the input query. These models compare the input text (a question or query) with a database of predefined responses. The system identifies the most suitable response by measuring the similarity between the input and stored responses using techniques like cosine similarity or other semantic matching methods. Retrieval-based models are efficient for tasks like question-answering, where the responses are often fact-based and readily available in a structured form.
Generation-Based Models in NLP
Generation-based models, on the other hand, create responses from scratch. These models use complex algorithms, often based on neural networks, to generate human-like text. Unlike retrieval-based models, generation-based models do not rely on predefined responses. Instead, they learn to generate responses by predicting the next word or sequence of words based on the context provided by the input. This ability to generate novel, contextually appropriate responses makes generation-based models highly versatile and suitable for creative writing, machine translation, and dialogue systems where responses must be diverse and contextually rich.
Key Differences and Similarities
| Retrieval-Based Models | Generation-Based Models | |
| Data Dependence | Rely heavily on the availability of predefined responses in the dataset. | Do not require predefined responses; they generate responses based on learned patterns. |
| Response Variety | Limited to the set of responses available in the database, which can result in repetitive or generic answers. | Can produce diverse and contextually rich responses, leading to more engaging and creative interactions. |
| Contextual Understanding | Focus on matching the input query with existing responses, lacking a deep understanding of the context. | Capture nuanced context and can generate responses tailored to the specific input, enhancing the quality of interactions. |
| Training Complexity | Generally more straightforward to train, as they involve matching input patterns with predefined responses. | A more complex training process often requires large datasets and sophisticated neural network architectures. |
In summary, retrieval-based models excel in tasks where predefined responses are available, and speed is crucial. In contrast, generation-based models shine in tasks requiring creativity, context awareness, and diverse and original content generation. Combining these approaches in models like RAG provides a balanced solution, leveraging the strengths of both methods to enhance the overall performance of NLP systems.
Limitations of Purely Retrieval or Generation Models
In the dynamic world of artificial intelligence, where conversations between humans and machines are becoming increasingly sophisticated, two predominant models have taken the stage: retrieval-based and generation-based models. While these models have their own merits, they are not without their limitations.
Limited Context Understanding
The Retrieval Models rely on pre-existing responses, often lacking the ability to understand the conversation’s context deeply. The Generation Models, though capable of producing contextually relevant responses, might lack access to specific, factual information that retrieval models can provide.
Repetitive and Generic Responses
Due to a fixed set of responses, the Retrieval Model can become repetitive, offering similar answers to different queries. Without a well-defined dataset, generation models might generate generic or nonsensical responses, especially if the training data does not cover a wide range of scenarios.
Handling Ambiguity
Ambiguous queries often result in suboptimal or incorrect responses since Retrieval Models lack the ability to effectively disambiguate the context. Dealing with ambiguous queries requires a nuanced understanding of the context for Generation Models, which can be challenging to achieve without extensive training data.
Real-World Examples Showcasing the Limitations of Traditional NLP Methods
As technology advances and our expectations grow, these methods are starting to show their limitations in handling the complexities of real-world conversations. Let’s delve into some real-world examples illuminating the challenges traditional NLP methods face.
| Customer Support Chatbots | Language Translation | Medical Diagnosis Systems | Educational Chatbots |
| Retrieval-based chatbots can offer predefined responses for common queries but struggle when faced with unique or complex issues, leading to frustrated customers. | Generation-based translation models might translate words individually, ignoring the context of the entire sentence. This can lead to inaccurate translations, especially for idiomatic expressions. | Retrieval models might lack the ability to incorporate the latest medical research and advancements, leading to outdated or inaccurate information. | Generation models might struggle with generating step-by-step explanations for complex concepts, hindering the learning experience for students. |
| A customer asks a specific technical question outside the chatbot’s predefined responses, resulting in a generic and unhelpful reply. | Translating the phrase “kick the bucket” into another language word-for-word might not convey its idiomatic meaning, resulting in confusion for the reader. | A patient’s symptoms might match an outdated database entry, causing the system to suggest incorrect diagnoses or treatments. | When a student asks a chatbot to explain a complex mathematical theorem, the generated response might lack clarity or fail to cover all necessary steps, causing confusion. |
Understanding these limitations is crucial for developing advanced NLP models like RAG, which aim to overcome these challenges by integrating the strengths of both retrieval and generation approaches. RAG’s ability to retrieve specific information while generating contextually appropriate responses addresses many of the shortcomings of traditional NLP methods, paving the way for more effective and engaging human-computer interactions.
What is the Need for Bridging Retrieval and Generation?
Imagine a world where conversations with chatbots are not only contextually rich but also personalized to individual needs. RAG makes this vision a reality by combining retrieval and generation methodologies. In interactive dialogues, context is key.
RAG ensures that responses are relevant, diverse, and engaging, enhancing the user experience in scenarios like customer service interactions or virtual assistant applications. It facilitates personalized responses, tailoring information to individual users’ needs, and enables dynamic information retrieval, ensuring the latest data is comprehensively presented.
Applications that Benefit from Bridging Retrieval and Generation
- Consider educational platforms seamlessly blending factual information from a knowledge base with custom-tailored explanations generated in real time.
- Visualize content creation tools crafting diverse narratives by retrieving relevant data and generating creative content.
- Envision medical diagnosis systems providing precise advice by integrating patient history (retrieval) with contextually accurate diagnostic reports (generation).
- Legal consultation chatbots translate complex legal jargon into understandable language, combining retrieval of legal data with clear, comprehensible explanations.
- Interactive storytelling platforms and video games come alive with predefined story elements and dynamically generated narratives based on user interactions, enhancing immersion and engagement.
Bridging the Gap with RAG
RAG’s ability to balance accurate information retrieval with creative, contextually appropriate generation transforms various fields. In the world of RAG, chatbots provide not just answers but meaningful, tailored interactions. Educational experiences become dynamic and personalized. Content creation becomes an art, blending facts with creativity. Medical consultations turn precise and empathetic. Legal advice becomes accessible and understandable. Interactive stories and games evolve into immersive adventures.
Architecture of RAG
In the intricate design of Retrieval-Augmented Generation (RAG) systems, a carefully choreographed two-step process unfolds to generate responses that are not just informative but also deeply engaging. Let’s unravel this process, where retrieval and generation seamlessly collaborate to craft meaningful interactions.

Retrieval Phase
At the heart of RAG’s functionality lies the retrieval phase. In this stage, the system delves into vast databases or collections of documents, meticulously searching for the most pertinent facts and passages related to the user’s query. Whether it’s scouring indexed webpages for general inquiries or consulting controlled manuals and articles for specific domains like customer support, RAG expertly extracts relevant snippets of external knowledge. These morsels of information are then seamlessly integrated with the user’s original input, enriching the context of the conversation.
Generation Phase
With the augmented context, the system gracefully transitions to the generation phase. The language model springs into action, meticulously analyzing the expanded prompt. It ingeniously references both the retrieved external information and its internally trained patterns. This dual-reference system allows the model to craft accurate responses that flow naturally, mimicking human conversation. The result is an insightful and contextually relevant answer that seamlessly integrates the retrieved data with the system’s inherent linguistic finesse.
The final response, born from this collaborative dance of retrieval and generation, can optionally feature links to the sources from which the information was retrieved. This enhances the response’s credibility and enables users to explore the origin of the provided information, fostering trust and understanding.
In essence, RAG systems combine the power of searching for information and the art of creative language to give you accurate and engaging responses, making your interactions with technology feel more like conversations with knowledgeable friends.
How does RAG Work?
RAG enriches user input with context from external data sources like documents or databases.
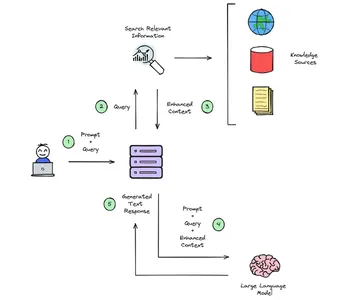
Initially, user queries and information are called Vector Embeddings, translated into numerical value embedding language models. These embeddings are organized in a vector store, where a search for relevance is conducted by comparing user query embeddings. The pertinent context found is added to the original user prompt, enhancing the overall context. The foundational language model then utilizes this enriched context to craft a text response. Additionally, a distinct process can be established to update the information in the vector store separately, ensuring constant updates.
Retrieval Component
The first step in RAG is retrieval. RAG fetches relevant information from a dataset or knowledge base using specialised algorithms or APIs. Here’s a basic example of how retrieval can be done using an API.
import requests
def retrieve_information(query):
api_endpoint = "https://example.com/api"
response = requests.get(api_endpoint, params={"query": query})
data = response.json()
return data
Augmentation Component
Once the information is retrieved, Rag augments it to enhance context. Augmentation can involve entity recognition, sentiment analysis, or simple text manipulation. Here’s an essential text augmentation example using the NLTK library:
import nltk
def augment_text(text):
tokens = nltk.word_tokenize(text)
augmented_tokens = [token.upper() for token in tokens]
augmented_text = " ".join(augmented_tokens)
return augmented_text
Generation Component
The final step involves generating natural language responses based on the retrieved and augmented information. This is typically done using pre-trained language models. Here’s an example using the Transformers library from Hugging Face:
from transformers import GPT2LMHeadModel, GPT2Tokenizer
def generate_text(prompt):
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("gpt2")
inputs = tokenizer.encode(prompt, return_tensors="pt")
outputs = model.generate(inputs, max_length=100, num_return_sequences=1)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
return generated_text
What are the Components of RAG?
In the intricate realm of Retrieval-Augmented Generation (RAG) systems, a carefully orchestrated symphony of components is essential for their effective implementation. Let’s break down these core elements that form the backbone of a robust RAG architecture, seamlessly integrating retrieval and generation for a transformative conversational experience.

Language Model
A pre-trained language model, such as the renowned GPT-3, is central to any RAG setup. These models are the cornerstone, possessing unparalleled language comprehension and synthesis abilities. They are the engines that power engaging and coherent conversational dialogues.
Vector Store
The vector store is at the heart of the retrieval process. It is a database that preserves document embeddings. These embeddings serve as unique signatures, rapidly identifying pertinent contextual information. Think of it as a vast repository allowing quick and efficient searches for relevant data.
Retriever Module
The retriever module acts as the gatekeeper, leveraging the vector store for semantic matching. Using advanced neural retrieval techniques, this component efficiently sifts through documents and passages to augment prompts. Its prowess lies in its ability to identify the most relevant information swiftly.
Embedder
An embedder plays a pivotal role in populating the vector store. This component encodes source documents into vector representations that the retriever comprehends. Models like BERT are tailor-made for this task, transforming textual information into abstract vector forms for efficient processing.
Document Ingestion
Robust pipelines work behind the scenes. They ingest and preprocess source documents, breaking them into manageable chunks or passages. These processed snippets are fed to the embedder, ensuring the information is structured and optimized for efficient lookup.
By harmonizing these core components, RAG systems empower language models to delve into extensive knowledge repositories. Through this intricate interplay, these systems transform mere interactions into profound exchanges of information and creativity, revolutionizing the landscape of human-computer communication.
RAG for Large Language Models
In the vast landscape of Artificial Intelligence, a revolutionary approach has emerged, transforming how machines communicate and understand human language. Retrieval Augmented Generation, or RAG, is not just another acronym in the tech world; it’s a game-changing framework that marries the brilliance of large language models (LLMs) with the wealth of real-world knowledge, enhancing the accuracy and transparency of AI interactions.
Text is produced by pre-trained language models using patterns found in their training data. RAG enhances its capabilities by bynenting information frequently and obtaining updated knowledge. Instead of relying solely on encoded patterns, this bases the language model’s predictions on actual data.
Implementing RAG: Code Demonstration
In the previous sections of our journey through RAG (Retrieval-Augmented Generation) in NLP, we delved into the theory behind this innovative approach. Now, it’s time to roll up our sleeves and get our hands dirty with some code.
Setting the Stage: Libraries and Tools
We will use the Hugging Face Transformers library, a treasure trove of pre-trained models and NLP tools. If you haven’t installed it yet, you can do so via pip:
pip install transformers
pip install torch
Step 1: Importing the Libraries
Let’s start by importing the necessary libraries. We’ll import the pipeline module from transformers to easily access pre-trained models and text generation.
from transformers import pipeline
Step 2: Setting Up the RAG Model
Now, let’s set up our RAG model. We’ll use the pipeline function with the text2text-generation task to initiate an RAG model.
rag_pipeline = pipeline("text2text-generation", model="facebook/rag-token-base",
retriever="facebook/rag-token-base")
This code uses the Facebook RAG model, which combines a retriever and a generator in one powerful package.
Step 3: Integrating Retrieval Methods
One of the most exciting aspects of RAG is its ability to perform retrieval before generation. To demonstrate this, let’s set up a sample context and query for our RAG model to retrieve relevant information.
context = "Albert Einstein was a German-born theoretical physicist who
developed the theory of relativity, one of the two pillars of modern physics."
query = "What is the theory of relativity?"Step 4: Generating Text with RAG
Let’s utilize our RAG model to generate text based on the provided context and query.
generated_text = rag_pipeline(query, context=context)[0]['generated_text']
print("Generated Text:")
print(generated_text)
RAG to Promote Transparency and Avert LLM Hallucinations
Retrieval Augmented Generation (RAG) acts like a fact-checker and a storyteller, ensuring that when AI responds to your questions, it’s not just making things up. Here’s how it works:
Providing Real-World Context
Imagine you ask a question, and instead of guessing an answer, RAG checks real-world sources for accurate information. This ensures that what it tells you is based on actual knowledge, making the responses trustworthy and reliable.
Citing Sources for Verification
RAG doesn’t just give you an answer; it also tells you where the information was found. It’s like giving you a bibliography for an essay. This way, you can double-check the facts, ensuring the information is accurate and comes from credible sources.
Preventing False Information
RAG doesn’t make things up. It avoids creating stories or providing false information by relying on verified facts. This ensures that the responses are truthful and don’t lead to misunderstandings.
Keeping Information Current
Think of RAG as having access to a constantly updated library. It ensures its information is always up-to-date, avoiding outdated or irrelevant details. This way, you always get the latest and most relevant answers to your questions.
Generating Embeddings for RAGs
When equipping RAG with the right knowledge, generating embeddings is the key. These embeddings, or compact numerical representations of text, are essential for RAG to understand and respond accurately. Here’s how this process works:
Encoding External Documents
Imagine these external documents as books in a vast library. RAG translates these documents into numerical vectors using specialized models like BERT to make sense of them. These vectors capture the meaning of the text in a way that the model can understand. It’s like translating entire books into a language the computer can comprehend.
Pretrained Language Models
RAG employs powerful language models like BERT or RoBERTa. These models are pre-trained to understand the nuances of human language. By inputting a document into these models, RAG creates a unique numerical representation for each document. For instance, if the document is about Paris, these models encode the essence of that information into a vector.
Tailoring Embeddings for Specific Topics
RAG fine-tunes these language models on specific topics to make these embeddings even more precise. Imagine tweaking a radio station to get a clearer reception. By training BERT on documents related to specific subjects, like travel guides, RAG ensures that the embeddings are tailored specifically for the topics it will deal with, such as vacations or travel-related queries.
Custom Autoencoder Model
RAG can also train a custom autoencoder model and a specialized translator. This model learns to translate entire documents into numerical vectors by understanding the unique patterns within the text. It’s like teaching a computer to read and summarize the content in its language, making the information accessible for the AI to process.
Simple Aggregation Functions
RAG can use techniques like TF-IDF weighted averaging for a more straightforward approach. This method calculates numerical values for each word in a document, considering their importance, and then combines them to form a vector. It’s akin to summarizing a book using its most significant keywords, ensuring a quick and efficient way to represent the document numerically.
Choosing the proper embedding method depends on the type of documents, the information’s complexity, and the RAG system’s specific needs. Typically, language model encoding and fine-tuning methods are favoured, ensuring RAG is equipped with high-quality, contextually rich document representations for effective retrieval and generation.
Customizing Retrieval Methods: Enhancing Precision
As seasoned adventurers, we know that one size doesn’t fit all in NLP. Customizing our retrieval methods is akin to sharpening our swords for battle. With RAG, we can choose specific retrievers tailored to our needs. For instance, integrating the BM25 retriever allows us to enhance the precision and relevance of the retrieved documents. Here’s a glimpse of how it’s done:
from transformers import RagRetriever, RagTokenizer, pipeline
retriever = RagRetriever.from_pretrained("facebook/rag-token-base", retriever="bm25")
tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-base")
generator = pipeline('text-generation', model='facebook/rag-token-base')
# Prepare your context and query
context = "Albert Einstein was a German-born theoretical physicist who
developed the theory of relativity, one of the two pillars of modern physics."
query = "What is the theory of relativity?"
input_dict = tokenizer(context, query, return_tensors="pt")
retrieved_docs = retriever(input_dict["input_ids"])
generated_text = generator(retrieved_docs["context_input_ids"])[0]["generated_text"]
print("Generated Text:")
print(generated_text)
Fine-Tuning for Mastery: Elevating RAG with Your Data
In our quest for NLP supremacy, we may need a specialized touch. Fine-tuning a pre-trained RAG model with our dataset can yield exceptional results. Imagine crafting a blade perfectly; every curve and angle is designed for precision. Here’s a glimpse into the world of fine-tuning:
from transformers import RagTokenizer, RagRetriever, RagSequenceForGeneration, RagConfig
from transformers import TextDataset, DataCollatorForLanguageModeling, Trainer, TrainingArguments
# Load and preprocess your dataset
dataset = TextDataset(tokenizer=tokenizer, file_path="path_to_your_dataset.txt")
# Define training arguments
training_args = TrainingArguments(
output_dir="./output",
num_train_epochs=3,
per_device_train_batch_size=4,
save_steps=500,
save_total_limit=2
)
# Initialize and train the model
model_config = RagConfig.from_pretrained("facebook/rag-token-base")
model = RagSequenceForGeneration.from_pretrained("facebook/rag-token-base",
config=model_config)
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=dataset
)
trainer.train()
Advanced RAG Configurations
Venturing further, we discover the secrets of advanced RAG configurations. Every adjustment impacts the outcome. Changing parameters like max_input_length and max_output_length can significantly alter the generated text.
Conclusion
In the ever-evolving landscape of artificial intelligence, Retrieval Augmented Generation (RAG) is a testament to the power of integrating knowledge and language. As we’ve explored, RAG represents a groundbreaking approach that marries the depth of external knowledge retrieval with the finesse of language generation. It ensures that when you interact with AI, you’re not just receiving responses based on learned patterns but engaging in conversations rooted in real-world facts and context.
This strategy combines LLM text generation with the ability to retrieve or search. It combines an LLM that generates answers using the data from relevant document snippets retrieved from a large corpus and the retriever system. RAG aids the model’s ability to “look up” external information and enhance its responses.
Key Takeaways
- Integrating retrieval-based and generation-based models, as exemplified by technologies like RAG, amplifies the effectiveness of AI conversations, ensuring responses grounded in real-world knowledge for accuracy and contextuality.
- Acknowledging the limitations of traditional NLP models fuels innovation, integrating retrieval and generation techniques to overcome challenges like ambiguity and foster more meaningful and nuanced interactions.
- Bridging the gap between retrieval and generation refines AI’s technical aspects and enhances the human experience. It creates reliable, accurate, and deeply contextual responses and transforms conversations into intuitive and empathetic exchanges.
Frequently Asked Questions
Q1. What are retrieval-based and generation-based models in NLP, and how do they differ?
A. Retrieval-based models retrieve pre-existing information, while generation-based models create responses from scratch. Retrieval models pull data from existing sources, whereas generation models construct responses using learned patterns.
Q2. Can you provide examples of limitations in purely retrieval or generation models in real-world applications?
A. A limitation of pure retrieval models is their inability to handle ambiguous queries effectively, leading to contextually inappropriate responses. On the other hand, pure generation models might generate creative but inaccurate responses, especially when the input is complex or nuanced.
Q3. What role does RAG play in bridging the gap between retrieval and generation in NLP?
A. Retrieval Augmented Generation (RAG) integrates the precision of retrieval models and the creativity of generation models. It enhances the accuracy and contextuality of AI-generated responses by combining relevant external context with learned patterns, thus bridging the gap between pure retrieval and generation methods.
Q4. How does RAG promote transparency and prevent Large Language Model (LLM) hallucinations?
A. RAG promotes transparency by grounding responses in real-world knowledge, providing clear visibility into the sources used for each prediction. It prevents LLM hallucinations by ensuring that responses are factually accurate, reducing the likelihood of generating false or misleading information.
Q5. Can you explain the process of generating embeddings for RAG and its significance in enhancing contextual understanding?
A. Embeddings for RAG are created by encoding external documents into numerical representations, enabling semantic similarity searches. Techniques like language model encoding and fine-tuning tailor these embeddings for specific domains, enhancing the model’s understanding of external context and ensuring contextually rich and accurate responses.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Technology can impact lives at a level that has never been realized in mankind's history. The idea that something I create can impact someone worldwide now or in the future drives my passion for Technology.
A dedicated ML Engineer and Tech enthusiast, proficient in training ML models. My current interests are advancing machine learning techniques, particularly in natural language processing, LLMs, and multimodal AI.




