Retrieval-Augmented Generation, or RAG, has become the backbone of most serious AI systems in the real world. The reason is simple: large language models are great at reasoning and writing, but terrible at knowing the objective truth. RAG fixes that by giving models a live connection to knowledge.
What follows are interview-ready question that could also be used as RAG questions checklist. Each answer is written to reflect how strong RAG engineers actually think about these systems.
Table of contents
Beginner RAG Interview Questions
Q1. What problem does RAG solve that standalone LLMs cannot?
A. LLMs when used alone, answer from patterns in training data and the prompt. They can’t reliably access your private or updated knowledge and are forced to guess when they don’t know the answers. RAG adds an explicit knowledge lookup step so answers can be checked for authenticity using real documents, not memory.
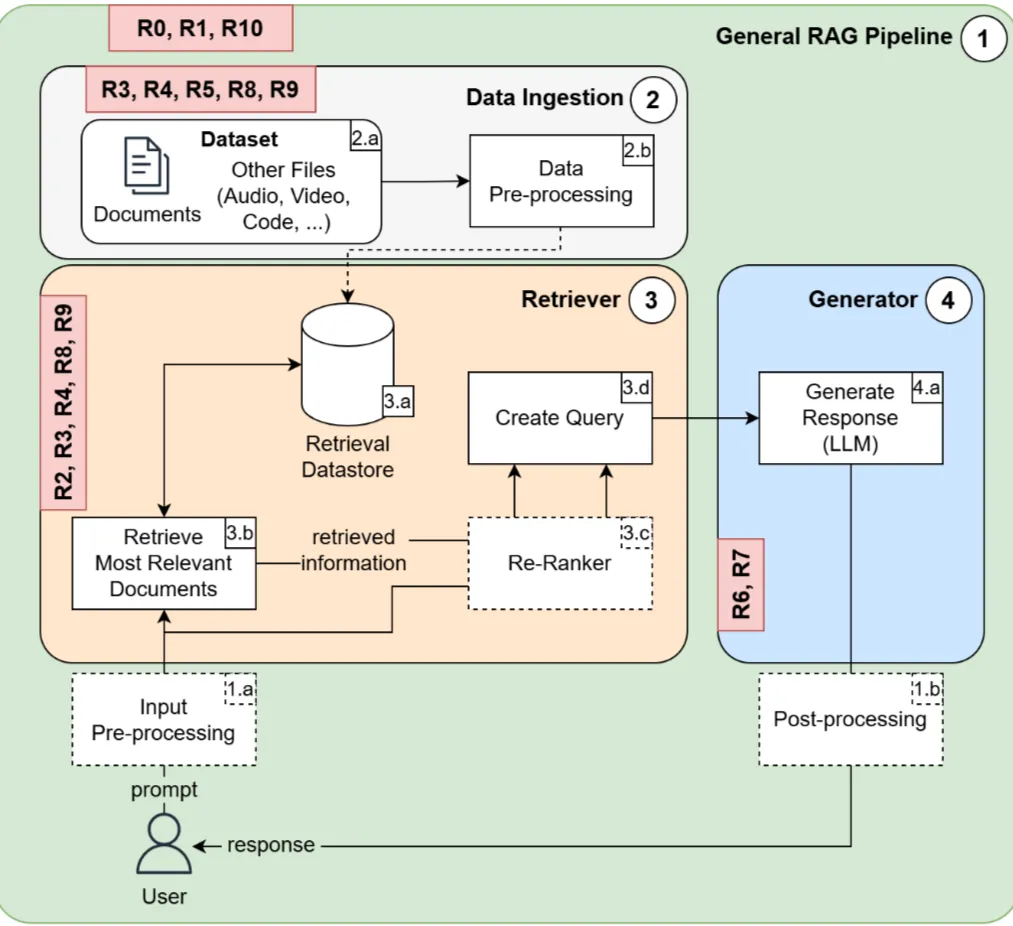
Q2. Walk through a basic RAG pipeline end to end.
A. A traditional RAG pipelines is as follows:
- Offline (building the knowledge base)
Documents
→ Clean & normalize
→ Chunk
→ Embed
→ Store in vector database - Online (answer a question)
User query
→ Embed query
→ Retrieve top-k chunks
→ (Optional) Re-rank
→ Build prompt with retrieved context
→ LLM generates answer
→ Final response (with citations)
Q3. What roles do the retriever and generator play, and how are they coupled?
A. The retriever and generator work as follows:
- Retriever: fetches candidate context likely to contain the answer.
- Generator: synthesizes a response using that context plus the question.
- They’re coupled through the prompt: retriever decides what the generator sees. If retrieval is weak, generation can’t save you. If the generation is weak, good retrieval still produces a bad final answer.
Q4. How does RAG reduce hallucinations compared to pure generation?
A. It gives the model “evidence” to quote or summarize. Instead of inventing details, the model can anchor to retrieved text. It doesn’t eliminate hallucinations, but it shifts the default from guessing to citing what’s present.
AI scratch engines like Perplexity are primarily powered by RAG, as they ground/verify the authenticity of the produced information by providing sources for it.
Q5. What types of data sources are commonly used in RAG systems?
A. Here are some of the commonly used data sources in a RAG system:
- Internal documents
Wikis, policies, PRDs - Files and manuals
PDFs, product guides, reports - Operational data
Support tickets, CRM notes, knowledge bases - Engineering content
Code, READMEs, technical docs - Structured and web data
SQL tables, JSON, APIs, web pages
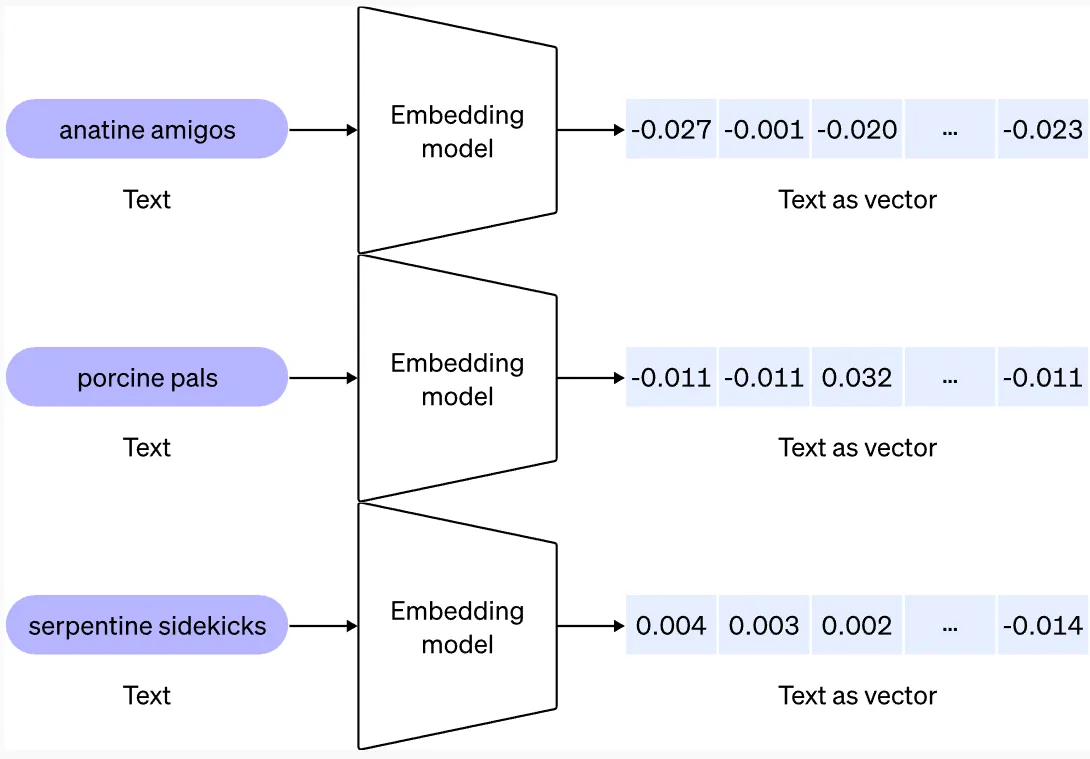
Q6. What is a vector embedding, and why is it essential for dense retrieval?
A. An embedding is a numeric representation of text where semantic similarity becomes geometric closeness. Dense retrieval uses embeddings to find passages that “mean the same thing” even if they don’t share keywords.
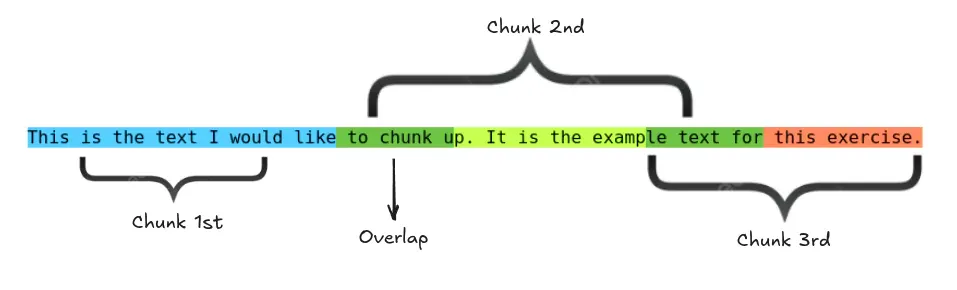
Q7. What is chunking, and why does chunk size matter?
A. Chunking splits documents into smaller passages for indexing and retrieval.
- Too large: retrieval returns bloated context, misses the exact relevant part, and wastes context window.
- Too small: chunks lose meaning, and retrieval may return fragments without enough information to answer.
Q8. What is the difference between retrieval and search in RAG contexts?
A. In RAG, search usually means keyword matching like BM25, where results depend on exact words. It is great when users know what to look for. Retrieval is broader. It includes keyword search, semantic vector search, hybrid methods, metadata filters, and even multi-step selection.
Search finds documents, but retrieval decides which pieces of information are trusted and passed to the model. In RAG, retrieval is the gatekeeper that controls what the LLM is allowed to reason over.
Q9. What is a vector database, and what problem does it solve?
A. A vector DB (short for vector database) stores embeddings and supports fast nearest-neighbor lookup to retrieve similar chunks at scale. Without it, similarity search becomes slow and painful as data grows, and you lose indexing and filtering capabilities.
Q10. Why is prompt design still critical even when retrieval is involved?
A. Because the model still decides how to use the retrieved text. The prompt must: set rules (use only provided sources), define output format, handle conflicts, request citations, and prevent the model from treating context as optional.
This provides a structure in which the response should be placed. It is critical because even though the retrieved information is the crux, the way it is represented matters just as much. Copy-pasting the retrieved information would be plagiarism, and in most cases a verbatim copy isn’t required. Therefore, this information is represented in a prompt template, to assure correct information representation.
Q11. What are common real-world use cases for RAG today?
A. AI powered search engines, codebase assistants, customer support copilots, troubleshooting assistants, legal/policy lookup, sales enablement, report drafting grounded in company data, and “ask my knowledge base” tools are some of the real-world applications of RAG.
Q12. In simple terms, why is RAG preferred over frequent model retraining?
A. Updating documents is cheaper and faster than retraining a model. Plug in a new information source and you’re done. Highly scalable. RAG lets you refresh knowledge by updating the index, not the weights. It also reduces risk: you can audit sources and roll back bad docs. Retraining requires a lot of effort.
Intermediate RAG Interview Questions
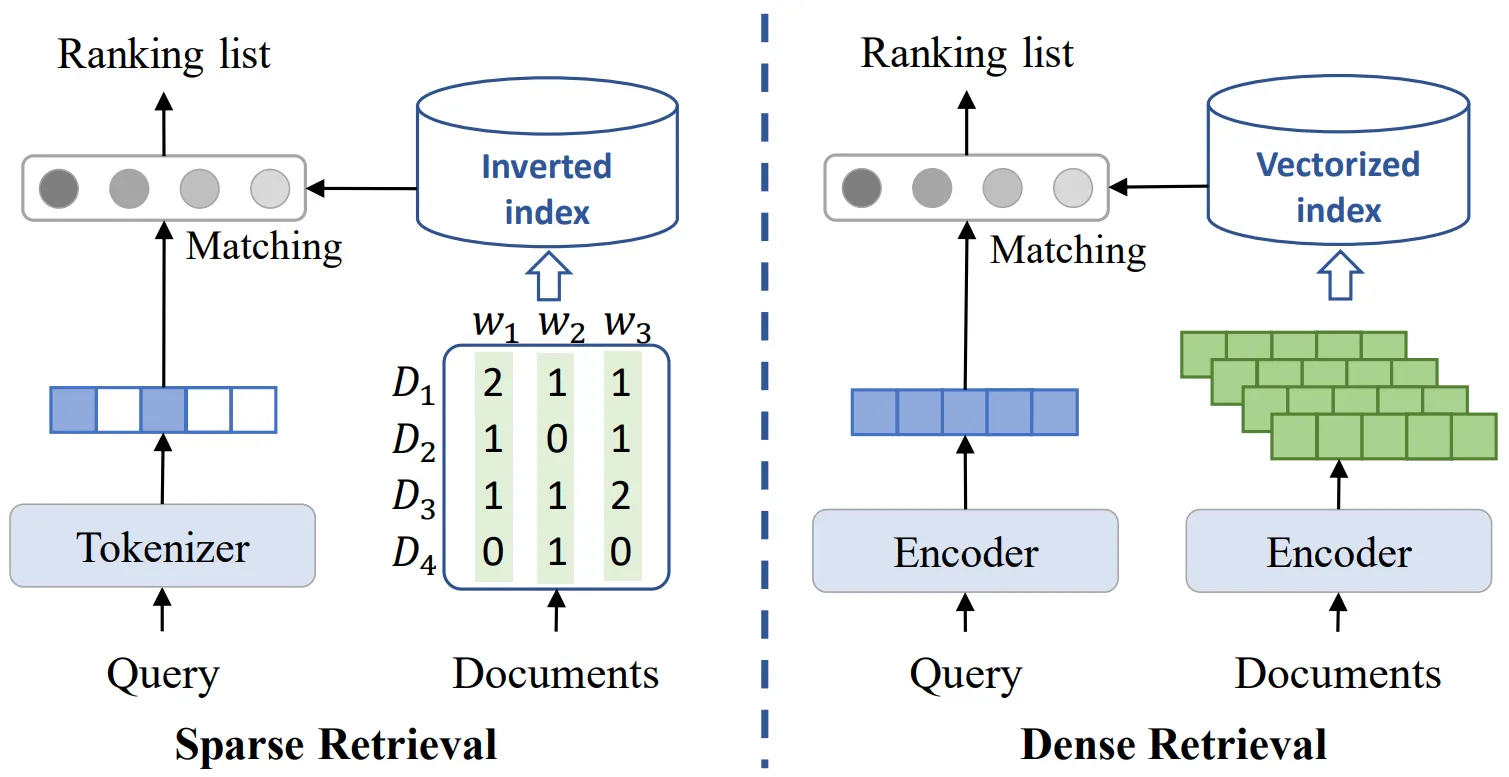
Q13. Compare sparse, dense, and hybrid retrieval methods.
A.
| Retrieval Type | What it matches | Where it works best |
| Sparse (BM25) | Exact words and tokens | Rare keywords, IDs, error codes, part numbers |
| Dense | Meaning and semantic similarity | Paraphrased queries, conceptual search |
| Hybrid | Both keywords and meaning | Real-world corpora with mixed language and terminology |
Q14. When would BM25 outperform dense retrieval in a RAG system?
A. BM25 works best when the user’s query contains exact tokens that must be matched. Things like part numbers, file paths, function names, error codes, or legal clause IDs don’t have “semantic meaning” in the way natural language does. They either match or they don’t.
Dense embeddings often blur or distort these tokens, especially in technical or legal corpora with heavy jargon. In those cases, keyword search is more reliable because it preserves exact string matching, which is what actually matters for correctness.
Q15. How do you decide optimal chunk size and overlap for a given corpus?
A. Here are some of the pointers to decide the optimal chunk size:
- Start with: The natural structure of your data. Use medium chunks for policies and manuals so rules and exceptions stay together, smaller chunks for FAQs, and logical blocks for code.
- End with: Retrieval-driven tuning. If answers miss key conditions, increase chunk size or overlap. If the model gets distracted by too much context, reduce chunk size and tighten top-k.
Q16. What retrieval metrics would you use to measure relevance quality?
A.
| Metric | What it measures | What it really tells you | Why it matters for retrieval |
| Recall@k | Whether at least one relevant document appears in the top k results | Did we manage to retrieve something that actually contains the answer? | If recall is low, the model never even sees the right information, so generation will fail no matter how good the LLM is |
| Precision@k | Fraction of the top k results that are relevant | How much of what we retrieved is actually useful | High precision means less noise and fewer distractions for the LLM |
| MRR (Mean Reciprocal Rank) | Inverse rank of the first relevant result | How high the first useful document appears | If the best result is ranked higher, the model is more likely to use it |
| nDCG (Normalized Discounted Cumulative Gain) | Relevance of all retrieved documents weighted by their rank | How good the entire ranking is, not just the first hit | Rewards putting highly relevant documents earlier and mildly relevant ones later |
Q17. How do you evaluate the final answer quality of a RAG system?
A. You start with a labeled evaluation set: questions paired with gold answers and, when possible, gold reference passages. Then you score the model across multiple dimensions, not just whether it sounds right.
Here are the main evaluation metrics:
- Correctness: Does the answer match the ground truth? This can be an exact match, F1, or LLM based grading against reference answers.
- Completeness: Did the answer cover all required parts of the question, or did it give a partial response?
- Faithfulness (groundedness): Is every claim supported by the retrieved documents? This is critical in RAG. The model should not invent facts that do not appear in the context.
- Citation quality: When the system provides citations, do they actually support the statements they are attached to? Are the key claims backed by the right sources?
- Helpfulness: Even if it is correct, is the answer clear, well structured, and directly useful to a user?
Q18. What is re-ranking, and where does it fit in the RAG pipeline?
A. Re-ranking is a second-stage model (often cross-encoder) that takes the query + candidate passages and reorders them by relevance. It sits after initial retrieval, before prompt assembly, to improve precision in the final context.
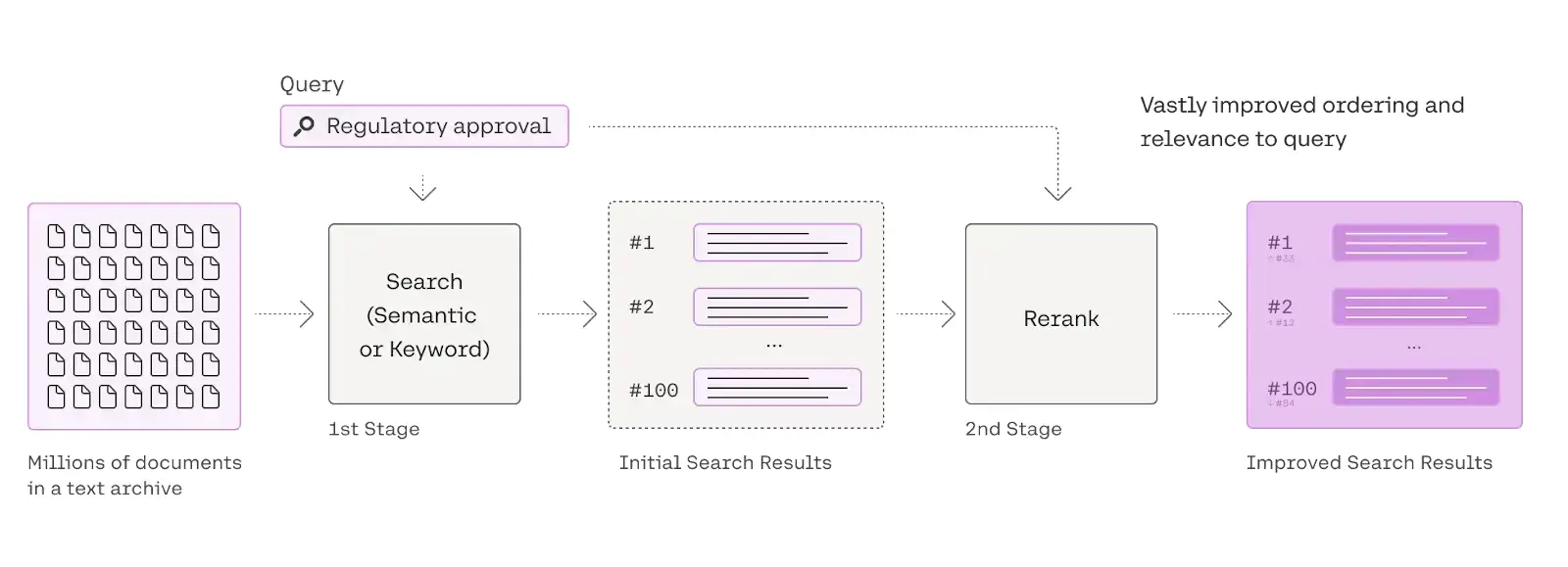
Read more: Comprehensive Guide for Re-ranking in RAG
Q19. When is Agentic RAG the wrong solution?
A. When you need low latency, strict predictability, or the questions are simple and answerable with single-pass retrieval. Also when governance is tight and you can’t tolerate a system that might explore broader documents or take variable paths, even if access controls exist.
Q20. How do embeddings influence recall and precision?
A. Embedding quality controls the geometry of the similarity space. Good embeddings pull paraphrases and semantically related content closer, which increases recall because the system is more likely to retrieve something that contains the answer. At the same time, they push unrelated passages farther away, improving precision by keeping noisy or off topic results out of the top k.
Q21. How do you handle multi-turn conversations in RAG systems?
A. You need query rewriting and memory control. Typical approach: summarize conversation state, rewrite the user’s latest message into a standalone query, retrieve using that, and only keep the minimal relevant chat history in the prompt. Also store conversation metadata (user, product, timeframe) as filters.
Q22. What are the latency bottlenecks in RAG, and how can they be reduced?
A. Bottlenecks: embedding the query, vector search, re-ranking, and LLM generation. Fixes: caching embeddings and retrieval results, approximate nearest neighbor indexes, smaller/faster embedding models, limit candidate count before re-rank, parallelize retrieval + other calls, compress context, and use streaming generation.
Q23. How do you handle ambiguous or underspecified user queries?
A. Do one of two things:
- Ask a clarifying question when the space of answers is large or risky.
- Or retrieve broadly, detect ambiguity, and present options: “If you mean X, here’s Y; if you mean A, here’s B,” with citations. In enterprise settings, ambiguity detection plus clarification is usually safer.
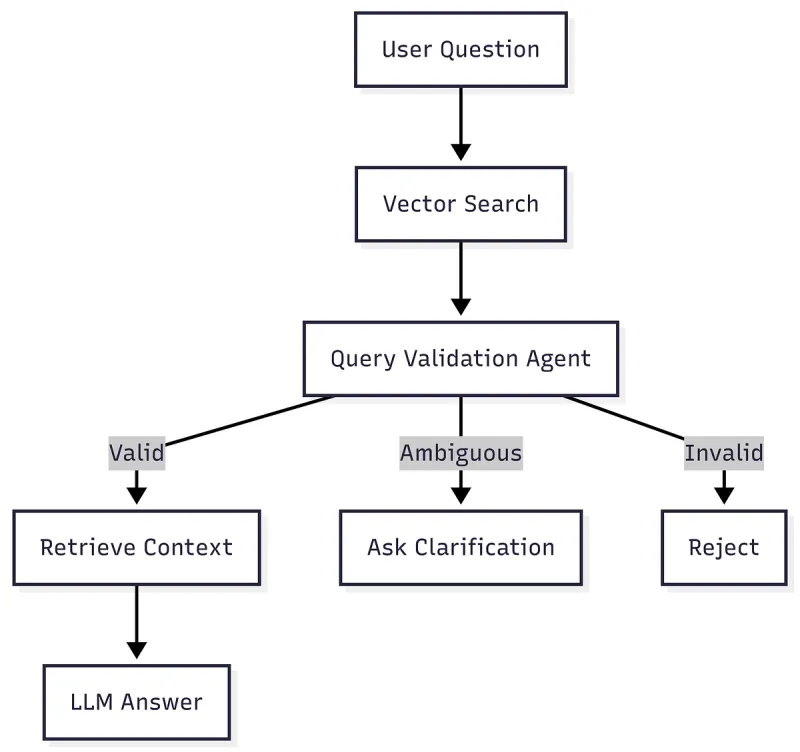
Clarifying questions are the key to handling ambiguity.
Q24. When might keyword search be sufficient instead of vector search?
A. Use it when the query is literal and the user already knows the exact terms, like a policy title, ticket ID, function name, error code, or a quoted phrase. It also makes sense when you need predictable, traceable behavior instead of fuzzy semantic matching.
Q25. How do you prevent irrelevant context from polluting the prompt?
A. The following pointers can be followed to prevent prompt pollution:
- Use a small top-k so only the most relevant chunks are retrieved
- Apply metadata filters to narrow the search space
- Re-rank results after retrieval to push the best evidence to the top
- Set a minimum similarity threshold and drop weak matches
- Deduplicate near-identical chunks so the same idea does not repeat
- Add a context quality gate that refuses to answer when evidence is thin
- Structure prompts so the model must quote or cite supporting lines, not just free-generate
Q26. What happens when retrieved documents contradict each other?
A. A well-designed system surfaces the conflict instead of averaging it away. It should: identify disagreement, prioritize newer or authoritative sources (using metadata), explain the discrepancy, and either ask for user preference or present both possibilities with citations and timestamps.
Q27. How would you version and update a knowledge base safely?
A. Treat the RAG stack like software. Version your documents, put tests on the ingestion pipeline, use staged rollouts from dev to canary to prod, tag embeddings and indexes with versions, keep chunk IDs backward compatible, and support rollbacks. Log exactly which versions powered each answer so every response is auditable.
Q28. What signals would indicate retrieval failure vs generation failure?
A. Retrieval failure: top-k passages are off-topic, low similarity scores, missing key entities, or no passage contains the answer even though the KB should.
Generation failure: retrieved passages contain the answer but the model ignores it, misinterprets it, or adds unsupported claims. You detect this by checking answer faithfulness against retrieved text.
Advanced RAG Interview Questions
Q29. Compare RAG vs fine-tuning across accuracy, cost, and maintainability.
A.
| Dimension | RAG | Fine-tuning |
| What it changes | Adds external knowledge at query time | Changes the model’s internal weights |
| Best for | Fresh, private, or frequently changing information | Tone, format, style, and domain behavior |
| Updating knowledge | Fast and cheap: re-index documents | Slow and expensive: retrain the model |
| Accuracy on facts | High if retrieval is good | Limited to what was in training data |
| Auditability | Can show sources and citations | Knowledge is hidden inside weights |
Q30. What are common failure modes of RAG systems in production?
A. Stale indexes, bad chunking, missing metadata filters, embedding drift after model updates, overly large top-k causing prompt pollution, re-ranker latency spikes, prompt injection via documents, and “citation laundering” where citations exist but don’t support claims.
Q31. How do you balance recall vs precision at scale?
A. Start high-recall in stage 1 (broad retrieval), then increase precision with stage 2 re-ranking and stricter context selection. Use thresholds and adaptive top-k (smaller when confident). Segment indexes by domain and use metadata filters to reduce search space.

Q32. Describe a multi-stage retrieval strategy and its benefits.
A. Following is a multi-stage retrieval strategy:
1st Stage: cheap broad retrieval (BM25 + vector) to get candidates.
2nd Stage: re-rank with a cross-encoder.
3rd Stage: select diverse passages (MMR) and compress/summarize context.|
Benefits of this process strategy are better relevance, less prompt bloat, higher answer faithfulness, and lower hallucination rate.
Q33. How do you design RAG systems for real-time or frequently changing data?
A. Use connectors and incremental indexing (only changed docs), short TTL caches, event-driven updates, and metadata timestamps. For truly real-time facts, prefer tool-based retrieval (querying a live DB/API) over embedding everything.
Q34. What privacy or security risks exist in enterprise RAG systems?
A. Sensitive data leakage via retrieval (wrong user gets wrong docs), prompt injection from untrusted content, data exfiltration through model outputs, logging of private prompts/context, and embedding inversion risks. Mitigate with access control filtering at retrieval time, content sanitization, sandboxing, redaction, and strict logging policies.
Q35. How do you handle long documents that exceed model context limits?
A. Don’t shove the whole thing in. Use hierarchical retrieval (section → passage), document outlining, chunk-level retrieval with smart overlap, “map-reduce” summarization, and context compression (extract only relevant spans). Also store structural metadata (headers, section IDs) to retrieve coherent slices.
Q36. How do you monitor and debug RAG systems post-deployment?
A. Log: query, rewritten query, retrieved chunk IDs + scores, final prompt size, citations, latency by stage, and user feedback. Build dashboards for retrieval quality proxies (similarity distributions, click/citation usage), and run periodic evals on a fixed benchmark set plus real-query samples.
Q37. What techniques improve grounding and citation reliability in RAG?
A. Span highlighting (extract exact supporting sentences), forced-citation formats (each claim must cite), answer verification (LLM checks if each sentence is supported), contradiction detection, and citation-to-text alignment checks. Also: prefer chunk IDs and offsets over “document-level” citations.
Q38. How does multilingual data change retrieval and embedding strategy?
A. You need multilingual embeddings or per-language indexes. Query language detection matters. Sometimes translate queries into the corpus language (or translate retrieved passages into the user’s language) but be careful: translation can change meaning and weaken citations. Metadata like language tags becomes essential.
Q39. How does Agentic RAG differ architecturally from classical single-pass RAG?
A.
| Aspect | Classical RAG | Agentic RAG |
|---|---|---|
| Control flow | Fixed pipeline: retrieve then generate | Iterative loop that plans, retrieves, and revises |
| Retrievals | One and done | Multiple, as needed |
| Query handling | Uses the original query | Rewrites and breaks down queries dynamically |
| Model’s role | Answer writer | Planner, researcher, and answer writer |
| Reliability | Depends entirely on first retrieval | Improves by filling gaps with more evidence |
Q40. What new trade-offs does Agentic RAG introduce in cost, latency, and control?
A. More tool calls and iterations increase cost and latency. Behavior becomes less predictable. You need guardrails: max steps, tool budgets, stricter stopping criteria, and better monitoring. In return, it can solve harder queries that need decomposition or multiple sources.
Conclusion
RAG is not just a trick to bolt documents onto a language model. It is a full system with retrieval quality, data hygiene, evaluation, security, and latency trade-offs. Strong RAG engineers don’t just ask if the model is smart. They ask if the right information reached it at the right time.
If you understand these 40 questions and answers, you are not just ready for a RAG interview. You are ready to design systems that actually work in the real world.
I specialize in reviewing and refining AI-driven research, technical documentation, and content related to emerging AI technologies. My experience spans AI model training, data analysis, and information retrieval, allowing me to craft content that is both technically accurate and accessible.






