
This article was submitted as part of Analytics Vidhya’s Internship Challenge.
Introduction
I’m an avid YouTube user. The sheer amount of content I can watch on a single platform is staggering. In fact, a lot of my data science learning has happened through YouTube videos!
So, I was browsing YouTube a few weeks ago searching for a certain category to watch. That’s when my data scientist thought process kicked in. Given my love for web scraping and machine learning, could I extract data about YouTube videos and build a model to classify them into their respective categories?
I was intrigued! This sounded like the perfect opportunity to combine my existing Python and data science knowledge with my curiosity to learn something new. And Analytics Vidhya’s internship challenge offered me the chance to pen down my learning in article form.

Web scraping is a skill I feel every data science enthusiast should know. It is immensely helpful when we’re looking for data for our project or want to analyze specific data present only on a website. Keep in mind though, web scraping should not cross ethical and legal boundaries.
In this article, we’ll learn how to use web scraping to extract YouTube video data using Selenium and Python. We will then use the NLTK library to clean the data and then build a model to classify these videos based on specific categories.
You can also check out the below tutorials on web scraping using different libraries:
- Beginner’s guide to Web Scraping in Python (using BeautifulSoup)
- Web Scraping in Python using Scrapy (with multiple examples)
- Beginner’s Guide on Web Scraping in R (using rest)
Note: BeautifulSoup is another library for web scraping. You can learn about this using our free course- Introduction to Web Scraping using Python.
Table of Contents
- Overview of Selenium
- Prerequisites for our Web Scraping Project
- Setting up the Python Environment
- Scraping Data from YouTube
- Cleaning the Scraped Data using the NLTK Library
- Building our Model to Classify YouTube Videos
- Analyzing the Results
Overview of Selenium

Selenium is a popular tool for automating browsers. It’s primarily used for testing in the industry but is also very handy for web scraping. You must have come across Selenium if you’ve worked in the IT field.
We can easily program a Python script to automate a web browser using Selenium. It gives us the freedom we need to efficiently extract the data and store it in our preferred format for future use.
Selenium requires a driver to interface with our chosen browser. Chrome, for example, requires ChromeDriver, which needs to be installed before we start scraping. The Selenium web driver speaks directly to the browser using the browser’s own engine to control it. This makes it incredibly fast.
Prerequisites for our Web Scraping Project
There are a few things we must know before jumping into web scraping:
- Basic knowledge of HTML and CSS is a must. We need this to understand the structure of a webpage we’re about to scrape
- Python is required to clean the data, explore it, and build models
- Knowledge of some basic libraries like Pandas and NumPy would be the cherry on the cake
Setting up the Python Environment
Time to power up your favorite Python IDE (that’s Jupyter notebooks for me)! Let’s get our hands dirty and start coding.
Step 1: Install Python binding:
#Open terminal and type-
$ pip install selenium
Step 2: Download Chrome WebDriver:
- Visit https://sites.google.com/a/chromium.org/chromedriver/download
- Select the compatible driver for your Chrome version
- To check the Chrome version you are using, click on the three vertical dots on the top right corner
- Then go to Help -> About Google Chrome
Step 3: Move the driver file to a PATH:
Go to the downloads directory, unzip the file, and move it to usr/local/bin PATH.
$ cd Downloads $ unzip chromedriver_linux64.zip $ mv chromedriver /usr/local/bin/
We’re all set to begin web scraping now.
Scraping Data from YouTube
In this article, we’ll be scraping the video ID, video title, and video description of a particular category from YouTube. The categories we’ll be scraping are:
- Travel
- Science
- Food
- History
- Manufacturing
- Art & Dance
So let’s begin!
- First, let’s import some libraries:
- Before we do anything else, open YouTube in your browser. Type in the category you want to search videos for and set the filter to “videos”. This will display only the videos related to your search. Copy the URL after doing this.
- Next, we need to set up the driver to fetch the content of the URL from YouTube:
- Paste the link into to driver.get(“ Your Link Here ”) function and run the cell. This will open a new browser window for that link. We will do all the following tasks in this browser window
- Fetch all the video links present on that particular page. We will create a “list” to store those links
- Now, go to the browser window, right-click on the page, and select ‘inspect element’
- Search for the anchor tag with id = ”video-title” and then right-click on it -> Copy -> XPath. The XPath should look something like : //*[@id=”video-title”]

With me so far? Now, write the below code to start fetching the links from the page and run the cell. This should fetch all the links present on the web page and store it in a list.
Note: Traverse all the way down to load all the videos on that page.
The above code will fetch the “href” attribute of the anchor tag we searched for.
Now, we need to create a dataframe with 4 columns – “link”, “title”, “description”, and “category”. We will store the details of videos for different categories in these columns:
We are all set to scrape the video details from YouTube. Here’s the Python code to do it:
Let’s breakdown this code block to understand what we just did:
- “wait” will ignore instances of NotFoundException that are encountered (thrown) by default in the ‘until’ condition. It will immediately propagate all others
- Parameters:
- driver: The WebDriver instance to pass to the expected conditions
- timeOutInSeconds: The timeout in seconds when an expectation is called
- v_category stores the video category name we searched for earlier
- The “for” loop is applied on the list of links we created above
- driver.get(x) traverses through all the links one-by-one and opens them in the browser to fetch the details
- v_id stores the stripped video ID from the link
- v_title stores the video title fetched by using the CSS path
- Similarly, v_description stores the video description by using the CSS path
During each iteration, our code saves the extracted data inside the dataframe we created earlier.
We have to follow the aforementioned steps for the remaining five categories. We should have six different dataframes once we are done with this. Now, it’s time to merge them together into a single dataframe:
Voila! We have our final dataframe containing all the desired details of a video from all the categories mentioned above.
Cleaning the Scraped Data using the NLTK Library
In this section, we’ll use the popular NLTK library to clean the data present in the “title” and “description” columns. NLP enthusiasts will love this section!
Before we start cleaning the data, we need to store all the columns separately so that we can perform different operations quickly and easily:
Import the required libraries first:
Now, create a list in which we can store our cleaned data. We will store this data in a dataframe later. Write the following code to create a list and do some data cleaning on the “title” column from df_title:
Did you see what we did here? We removed all the punctuation from the titles and only kept the English root words. After all these iterations, we are ready with our list full of data.
We need to follow the same steps to clean the “description” column from df_description:
Note: The range is selected as per the rows in our dataset.
Now, convert these lists into dataframes:
Next, we need to label encode the categories. The “LabelEncoder()” function encodes labels with a value between 0 and n_classes – 1 where n is the number of distinct labels.
Here, we have applied label encoding on df_category and stored the result into dfcategory. We can store our cleaned and encoded data in into a new dataframe:
We’re not quite all the way done with our cleaning and transformation part.
We should create a bag-of-words so that our model can understand the keywords from that bag to classify videos accordingly. Here’s the code to do create a bag-of-words:
Note: Here, we created 1500 features from data stored in the lists – corpus and corpus1. “X” stores all the features and “y” stores our encoded data.
We are all set for the most anticipated part of a data scientist’s role – model building!
Building our Model to Classify YouTube Videos
Before we build our model, we need to divide the data into training set and test set:
- Training set: A subset of the data to train our model
- Test set: Contains the remaining data to test the trained model
Make sure that your test set meets the following two conditions:
- Large enough to yield statistically meaningful results
- Representative of the dataset as a whole. In other words, don’t pick a test set with different characteristics than the training set
We can use the following code to split the data:
Time to train the model! We will use the random forest algorithm here. So let’s go ahead and train the model using the RandomForestClassifier() function:
Parameters:
- n_estimators: The number of trees in the forest
- criterion: The function to measure the quality of a split. Supported criteria are “gini” for Gini impurity and “entropy” for information gain
Note: These parameters are tree-specific.
We can now check the performance of our model on the test set:
We get an impressive 96.05% accuracy. Our entire process went pretty smoothly! But we’re not done yet – we need to analyze our results as well to fully understand what we achieved.
Analyzing the Results
Let’s check the classification report:
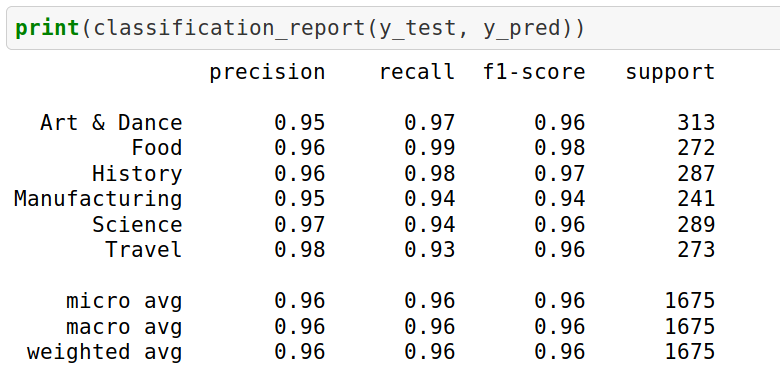
The result will give the following attributes:
- Precision is the ratio of correctly predicted positive observations to the total predicted positive observations. Precision = TP/TP+FP
- Recall is the ratio of correctly predicted positive observations to all the observations in the actual class. Recall = TP/TP+FN
- F1 Score is the weighted average of Precision and Recall. Therefore, this score takes both false positives and false negatives into account. F1 Score = 2*(Recall * Precision) / (Recall + Precision)
We can check our results by creating a confusion matrix as well:
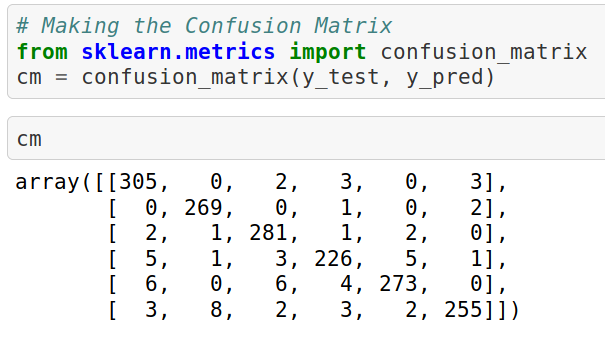
The confusion matrix will be a 6×6 matrix since we have six classes in our dataset.
End Notes
I’ve always wanted to combine my interest in scraping and extracting data with NLP and machine learning. So I loved immersing myself in this project and penning down my approach.
In this article, we just witnessed Selenium’s potential as a web scraping tool. All the code used in this article is random forest algorithm Congratulations on successfully scraping and creating a dataset to classify videos!
I look forward to hearing your thoughts and feedback on this article.
A Data Science Enthusiast who loves reading & writing about Data Science and its applications. He has done many projects in this field and his recent work include concepts like Web Scraping, NLP etc. He is a Data Science Content Strategist Intern at Analytics Vidhya. And currently pursuing BTech in Computer Science from DIT University, Dehradun.
Free Courses






Thanks Shubham. Pretty methodical approach. I wish you could have show output at each step. That way it's easier to follow along and see how the output changes in each step. Do you have the Juptyer notebook somewhere?
Hi, Thank you for your feedback and suggestion. I'll try to keep outputs hand in my future posts. You can also go through the notebook in my GitHub (https://github.com/shubham-singh-ss/Youtube-scraping-using-Selenium)
Is it legal to scrap data for analysis...academic purposes
It depends on the policy of the website you want to scrap data from. It's not clearly legal. If the policies allow you to scrap data for academic or research purpose, sure it's legal.
It is really quite difficult to find such detailed information about any new or still-going-on technology. Brilliant article for beginners like me.
Thank You, it's good to know that my content helped you somehow.