Overview
- Relational databases are ubiquitous, but what happens when you need to scale your infrastructure?
- We will discuss the role Spark SQL plays in this situation and understand why it’s such a useful tool to learn
- This tutorial also showcases how Spark SQL works using a case study in Python
Introduction
Relational databases are used by almost all organizations for various tasks – from managing and tracking a huge amount of information to organizing and processing transactions. It’s one of the first concepts we are taught in coding school.
And let’s be grateful for that because this is a crucial cog in a data scientist’s skillset! You simply cannot get by without knowing how databases work. It’s a key aspect of any machine learning project.
Structured Query Language (SQL) is easily the most popular language when it comes to databases. Unlike other programming languages, it is easy to learn and helps us start with our data extraction process. For most of the data science jobs, proficiency in SQL ranks higher than most other programming languages.

But there’s a significant challenge with SQL – you’ll struggle to make it work when you’re dealing with humongous datasets. This is where Spark SQL takes a front seat and bridges the gap. I’ll take more about this in the next section.
This hands-on tutorial will introduce you to the world of Spark SQL, how it works, what are the different features it offers, and how you can implement it using Python. We’ll also talk about an important concept you’ll often encounter in interviews – catalyst optimizer.
Let’s get started!
Note: If you’re completely new to the world of SQL, I highly recommend the below course:
Table of Contents
- Challenges with Scaling Relational Databases
- Overview of Spark SQL
- Features of Spark SQL
- How Does Spark SQL Execute a Query?
- What is a Catalyst Optimizer?
- Executing SQL Commands with Spark
- Use of Apache Spark at Scale
Challenges with Scaling Relational Databases
The question is why should you learn Spark SQL at all? I mentioned this briefly earlier, but let’s look at it in a bit more detail now.
Relational databases for a big (machine learning) project contain hundreds or maybe thousands of tables and most of the features in one table are mapped to some other features in some other tables. These databases are designed to run only on a single machine in order to maintain the rules of the table mappings and avoid the problems of distributed computing.
This often becomes a problem for organizations when they want to scale with this design. It would require more complex and expensive hardware with significantly higher processing power and storage. As you can imagine, upgrading from simpler hardware to complex ones can be extremely challenging.
An organization might have to take its website offline for some time to make any required changes. During this period, they would be losing business from the new customers they could have potentially acquired.
Additionally, as the volume of data is increasing, organizations struggle to handle this huge amount of data using traditional relational databases. This is where Spark SQL comes into the picture.
Overview of Spark SQL
“”
~
Hadoop and the MapReduce frameworks have been around for a long time now in big data analytics. But these frameworks require a lot of read-write operations on a hard disk which makes it very expensive in terms of time and speed.
Apache Spark is the most effective data processing framework in enterprises today. It’s true that the cost of Spark is high as it requires a lot of RAM for in-memory computation but it’s still a hot favorite among Data Scientists and Big Data Engineers.
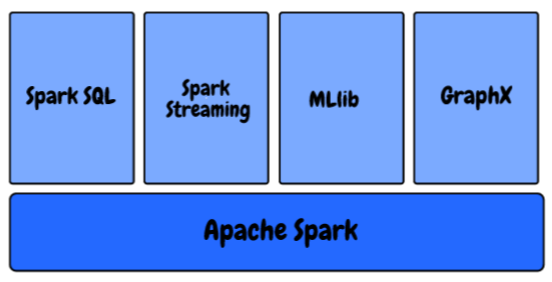
In the Spark Ecosystem, we have the following components:
- MLlib: This is Spark’s scalable machine learning library that provides high-quality algorithms for regression, clustering, classification, etc. You can start building machine learning pipelines using Spark’s MLlib using this article: How to Build Machine Learning Pipelines using PySpark?
- Spark Streaming: We are generating data at an unprecedented pace and scale right now. How do we ensure that our machine learning pipeline continues to churn out the results as soon as the data is generated and collected? Learn how to use a Machine Learning Model to Make Predictions on Streaming Data using PySpark?
- GraphX: It is a Spark API for graphs, a network graph engine that supports parallel graph computation
- Spark SQL: This is a distributed framework for structured data processing provided by Spark
We know that in relational databases, the relationship between the different variables as well as different tables are also stored and are designed in such a manner that it can handle complex queries.
Spark SQL is an amazing blend of relational processing and Spark’s functional programming. It provides support for various data sources and makes it possible to make SQL queries, resulting in a very powerful tool for analyzing structured data at scale.
Features of Spark SQL
Spark SQL has a ton of awesome features but I wanted to highlight a few key ones that you’ll be using a lot in your role:
- Query Structure Data within Spark Programs: Most of you might already be familiar with SQL. Hence, you are not required to learn how to define a complex function in Python or Scala to use Spark. You can use the exact same query to get the results for your bigger datasets!
- Compatible with Hive: Not only SQL, but you can also run the same Hive queries using the Spark SQL Engine. It allows full compatibility with current Hive queries
- One Way to Access Data: In typical enterprise-level projects, you do not have a common source of data. Instead, you need to handle multiple types of files and databases. Spark SQL supports almost every type of file and gives you a common way to access a variety of data sources, like Hive, Avro, Parquet, JSON, and JDBC
- Performance and Scalability: While working with large datasets, there are chances that faults might occur between the time while the query is running. Spark SQL supports full mid-query Fault Tolerance so we can work with even a thousand nodes simultaneously
- User-Defined Functions: UDF is a feature of Spark SQL that defines new column-based functions that extend the vocabulary of Spark SQL for transforming datasets
How Does Spark SQL Execute a Query?
How does Spark SQL work, essentially? Let’s understand the process in this section.
- Analysis: First, when you query something, Spark SQL finds the relationship that needs to be computed. It is computed using an abstract syntax tree (AST) where it checks for the correct usage of the elements used to define the query and then creates a logical plan to execute the query

- Logical Optimization: In this next step, rule-based optimization is applied to the logical plan. It uses techniques such as:
- Filtering data early if the query contains a where clause
- Utilizing available index in the tables as it can improve the performance, and
- Even ensuring different data sources are joined in the most efficient order
- Physical Planning: In this step, one or more physical plans are formed using the logical plan. Spark SQL then selects the plan that will be able to execute the query in the most efficient manner, i.e using less computational resources
- Code Generation: In the final step, Spark SQL generates code. It involves generating a Java byte code to run on each machine. Catalyst uses a special feature of Scala language called “Quasiquotes” to make code generation easier

What is a Catalyst Optimizer?
Optimization means upgrading the existing system or workflow in such a way that it works in a more efficient way, while also using fewer resources. An optimizer known as a Catalyst Optimizer is implemented in Spark SQL which supports rule-based and cost-based optimization techniques.
In rule-based optimization, we have defined a set of rules that will determine how the query will be executed. It will rewrite the existing query in a better way to improve the performance.
For example, let’s say an index is available on the table. Then, the index will be used for the execution of the query according to the rules and WHERE filters will be applied first on initial data if possible (instead of applying them at the end).
Also, there are some cases where the use of an index slows down a query. We know that it is not always possible that a set of defined rules will always make great decisions, right?
Here’s the issue – Rule-Based Optimization does not take data distribution into account. This is where we turn to a Cost-Based Optimizer. It uses statistics about the table, its indexes, and the distribution of the data to make better decisions.
Executing SQL Commands with Spark
Time to code!
I have created a random dataset of 25 million rows. You can download the entire dataset here. We have a text file with comma-separated values. So, first, we will import the required libraries, read the dataset, and see how Spark will divide the data into partitions:
![]()
Here,
- The first value in each row is the age of the person (which needs to be an integer)
- The second value is the Blood Group of the person (which needs to be a string)
- The third and fourth values are city and gender (both are strings), and
- The final value is an id (which is of integer type)
We will map the data of each row to a specific data type and name using the Spark rows:
![]()

Next, we will create a dataframe using the parsed rows. Our aim is to find the value counts of the gender variable by using a simple groupby function on the dataframe:

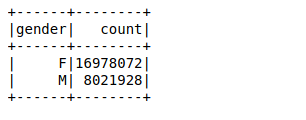

It took around 26 ms to calculate the value counts of 25 million rows using a groupby function on the dataframe. You can calculate the time using %%time in the particular cell of your Jupyter notebook.
Now, we will perform the same query using Spark SQL and see if it improves the performance or not.
First, you need to register the dataframe as a temporary table using the function registerTempTable. This creates an in-memory table that is only scoped to the cluster in which it was created. The lifetime of this temp table is limited to just a session. It is stored using Hive’s in-memory columnar format which is highly optimized for relational data.
Also, you don’t even need to write complex functions to get results if you are comfortable with SQL! Here, you just need to pass the same SQL query to get the desired results on bigger data:
![]()
It took only around 18 ms to calculate the value counts. This is much quicker than even a Spark dataframe.
Next, we will perform another SQL query to calculate the average age in a city:
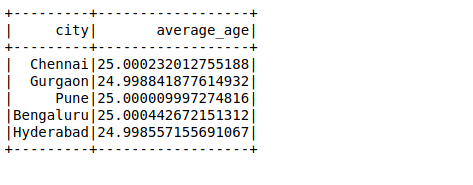
Use Case of Apache Spark at Scale
We know that Facebook has more than 2 billion monthly active users and with more data, they face equally complex challenges. For a single query, they need to analyze tens of terabytes of data in a single query. Facebook believes that Spark had matured to the point where we could compare it with Hive for a number of batch-processing use cases.
Let me illustrate this using a case study from Facebook itself. One of their tasks was to prepare the features for entity ranking which Facebook uses in its various online services. Earlier they used Hive-based infrastructure which was resource-intensive and challenging to maintain as the pipeline was sharded into hundreds of Hive jobs. They then built a faster and more manageable pipeline with Spark. You can read their complete journey here.
They have compared the results of Spark vs Hive Pipeline. Here is a comparison plot in terms of latency (end-to-end elapsed time of the job) which clearly shows that Spark is much faster than Hive.

End Notes
We’ve covered the core idea behind Spark SQL in this article and also learned how to use it to our advantage. We also took up a big dataset and applied our learning in Python.
Spark SQL is a relative unknown for a lot of data science aspirants but it’ll come in handy in your industry role or even in interviews. It’s quite a major addition in the eyes of the hiring manager.
Please share your thoughts and suggestions in the comments section below.
Ideas have always excited me. The fact that we could dream of something and bring it to reality fascinates me. Computer Science provides me a window to do exactly that. I love programming and use it to solve problems and a beginner in the field of Data Science.






