This article was published as a part of the Data Science Blogathon.
Introduction
Relational databases are here to stay, regardless of the hype and the rise of newer ones called NoSQL databases. The simple reason is that relational databases enforce basic structure and constraints and provide a friendly, declarative language for querying data (that we love): SQL!
.jpg)
However, the scale has always been an issue with relational databases. Most businesses in the 21st century are loaded with rich data stores and repositories and want to make the most of their big data for actionable insights. Relational databases may be popular, but they don’t scale very well if we don’t invest in the right big data management strategy. This includes thinking about potential data sources, data volumes, constraints, schemas, extract-transform-load (ETL), query approaches and patterns, and much more!
This article will look at some of the significant advances made in harnessing the power of relational databases, but “at scale,” using some of the newer components from Apache Spark – Spark SQL and DataFrames. First of all, we will deal with the following topics.
-
Motivations and challenges with scaling relational databases
- Understanding of Spark SQL & DataFrames
- Objectives
- Architecture and features
- Performance
We’ll look at the main challenges and motivations for those who work so hard and invest time in building new components in Apache Spark to do SQL at scale. We will also explore the leading architecture, interfaces, features and performance benchmarks for Spark SQL and DataFrames. Finally, but most importantly, we will cover a real-world case study of KDD 99 Cup Data-based breach attack analysis using Spark SQL and DataFrames using the Databricks Cloud Platform for Spark.
Motivations and Challenges to Scale Relational Databases for big data
Relational data stores are easy to create and query. Users and developers also often prefer to write quickly interpretable declarative queries in a human-readable language such as SQL. However, as the volume and variety of data increases, the relational approach is not scalable enough to build big data applications and analytics systems. These are some challenges.
Work with different types and sources of data, which can be structured, semi-structured and unstructured
- Building ETL pipelines to and from various data sources can lead to the development of a large amount of specific custom code, increasing technical debt over time
- Ability to perform both traditional business intelligence (BI)-based analytics and advanced analytics (machine learning, statistical modelling, etc.), challenging to achieve in relational systems.
Extensive data analysis is not something that was invented yesterday! We have had success in this area with Hadoop and the MapReduce paradigm. This was powerful but often slow and provided users with a low-level, procedural programming interface that required people to write a lot of code for even elementary data transformations. However, once Spark was released, it truly revolutionised the way extensive data analysis was done, focusing on in-memory computing, fault tolerance, high-level abstraction, and ease of use.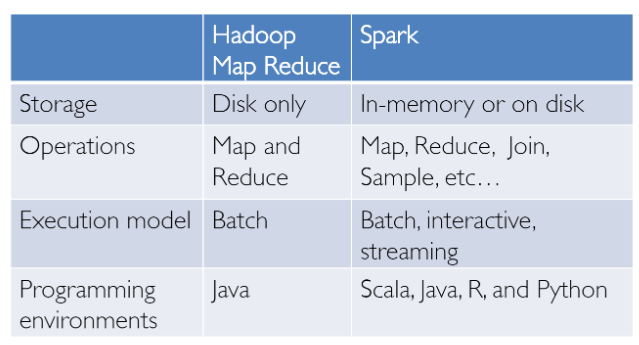
Since then, several frameworks and systems such as Hive, Pig, and Shark (which evolved into Spark SQL) have provided rich relational interfaces and declarative query mechanisms to big data stores. However, the challenge remained that these tools were either relational or procedural, and we couldn’t have the best of both worlds.
However, in the real world, most data and analytics pipelines may involve a mix of relational and procedural code. Forcing users to choose between them leads to complications and increases the effort of users in developing, building and maintaining different applications and systems. Rather than forcing users to choose between a relational or procedural API, Spark SQL aims to enable users to mix them seamlessly to perform data querying, retrieval, and analysis at scale on big data.
Understanding Spark SQL and DataFrames
Spark SQL tries to bridge the gap between the two models we mentioned earlier – the relational and the procedural model – with two main components.
- It provides a DataFrame API that allows you to perform large-scale relational operations on external data sources and Spark’s built-in distributed collections.
- To support a wide variety of different data sources and algorithms in Big Data, Spark SQL introduces a new extensible optimizer called Catalyst, which makes it easy to add data sources, optimization rules, and data types for advanced analytics like machine learning.
Essentially, Spark SQL leverages the power of Spark to perform distributed, robust, in-memory computing at a massive scale on Big Data. Spark SQL provides superior performance while maintaining compatibility with all existing frameworks and components supported by Apache Hive (an extensive popular data warehouse framework), including data formats, user-defined functions (UDFs), and megastores. In addition, it also helps in accepting a wide variety of data formats from significant data sources and enterprise data warehouses such as JSON, Hive, Parquet, and so on, and performing a combination of relational and procedural operations for more complex and advanced analytics.
Objectives
Let’s look at some interesting facts about Spark SQL, including its uses, adoption and goals, some of which I shamelessly copy once again from an excellent and original article on “Relational Data Processing in Spark”. Spark SQL was first released in May 2014 and is now perhaps one of the most actively developed components in Spark. In addition, Apache Spark is the most active open source big data project with hundreds of contributors.’
In addition to being an open source project, Spark SQL has begun to gain mainstream industry adoption. It has already been deployed in massive environments. For example, Facebook has an excellent case study on “Apache Spark @Scale: 60 TB+ Production Use Case.” The company was preparing data for entity ranking, and its Hive jobs took days and had many problems, but Facebook was able to scale and increase performance with Spark. Check out the exciting challenges they faced along the way!
Another interesting fact is that two-thirds of Databricks Cloud customers (the hosted service running Spark) use Spark SQL in other programming languages. Therefore, in the second part of this series, we will also present a hands-on case study using Spark SQL on Databricks.
The main goals for Spark SQL, as defined by its creators, are:
Support for relational processing, both within Spark programs (on native RDDs) and on external data sources using the programmer’s API
- Deliver high performance using established DBMS techniques
- Easily support new data sources, including semi-structured data and external databases for query federation
- Enable extensions with advanced analytics algorithms such as graph processing and machine learning
Architecture and Features
We will now look at the key features and architecture around Spark SQL and DataFrames. Some key concepts to keep in mind would be related to the Spark ecosystem, which has constantly evolved.
The Spark ecosystem
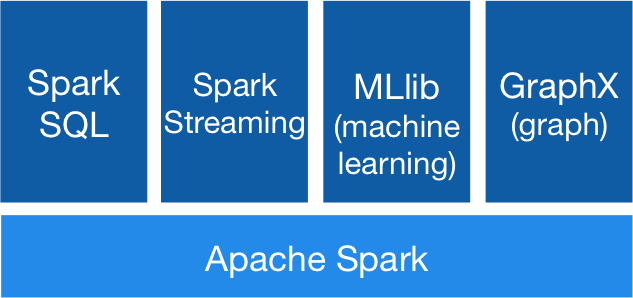
RDD (Resilient Distributed Dataset) is perhaps the most significant contributor to all Spark success stories. It is essentially a data structure, or a distributed memory abstraction, that allows programmers to perform in-memory computations on large distributed clusters while maintaining aspects such as fault tolerance. You can also parallelize many calculations and transformations and track a whole series of changes, which can help efficiently recalculate lost data. Spark enthusiasts may want to read the excellent RDD article, “Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing.” Spark also works with the concept of drivers and workers, as shown in the following image.
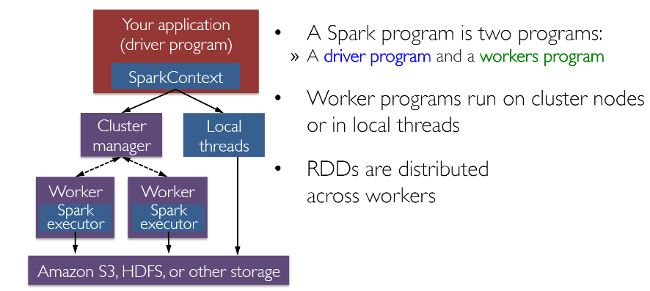
Spark works with drivers and workers. You can usually create RDDs by loading data from files, databases, existing parallelizing collections, or transformations. Transformations are generally operations that can transform data into different aspects and dimensions depending on how we want to handle and process the data. Unfortunately, they are also lazily evaluated, meaning that even if you define a transformation, the results won’t be calculated until you use an action, which usually requires the development to be returned to the driver program (and it will then calculate any transformations applied!).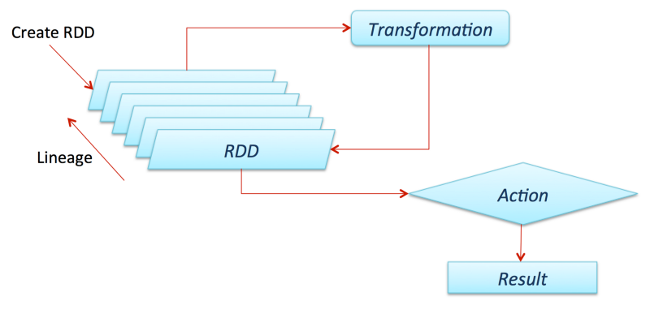
Thanks to fellow data scientist and friend Favio Vázquez and his excellent article “Deep Learning With Apache Spark, ” I got some great ideas and content, including the previous image. Look at it!
Now that we know the general architecture of Spark works, let’s take a closer look at Spark SQL. Spark SQL usually runs as a library on top of Spark, as we saw in the figure covering the Spark ecosystem. The following figure provides a more detailed look at a typical Spark SQL architecture and interface.
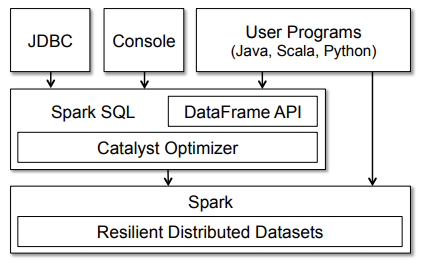
The figure clearly shows the various SQL interfaces that can be accessed via JDBC/ODBC or the command-line console and the DataFrame API integrated into Spark’s supported programming languages (we’ll be using Python). The DataFrame API is robust and allows users to mix procedural and relational code! Advanced functions such as UDFs (User Defined Functions) can also be exposed in SQL that BI tools can use.
A Spark DataFrame is a distributed collection of rows (row types) with the same schema. It’s a Spark dataset organised into named columns. It should be noted here that datasets are an extension of the DataFrame API that provides a type-safe, object-oriented programming interface. So they’re only available in Java and Scala, so we’ll focus on DataFrames.
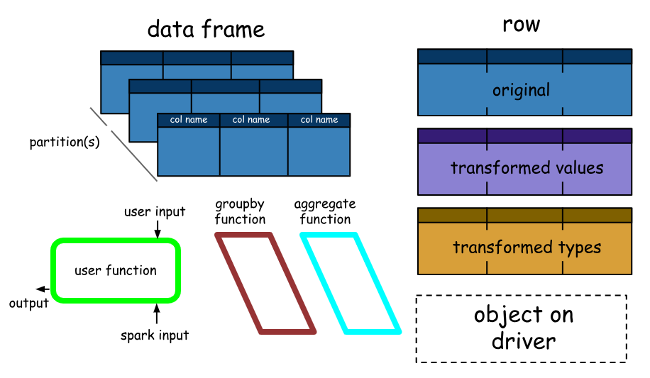
DataFrames architecture DataFrame is equivalent to a table in a relational database (but with more optimizations under the hood) and can also be manipulated in a similar way to Spark’s “native” distributed collections (RDDs).
Unlike RDDs, data frames typically follow their schema and support various relational operations, leading to more optimized execution.
- DataFrames can be constructed from tables, like existing Hive tables in your Big Data infrastructure, or even from existing RDDs.
- DataFrames can be manipulated using direct SQL queries and DataFrame DSL (domain-specific language), where we can use various relational operators and transformers like where and groupBy.
- Each DataFrame can also represent an RDD of row objects, allowing users to call procedural Spark APIs such as maps.
- Finally, given, but always remember, unlike traditional data frame APIs (Pandas), Spark’s data frames are lazy because each DataFrame object represents a logical plan for computing a dataset. Still, no execution occurs until the user calls a special “output operation” such as saving.
This should give you enough insight into Spark SQL, DataFrames, core features, concepts, architecture, and interfaces. Finally, we’ll close this section with a look at performance benchmarks.
Performance
Releasing a new feature without proper optimizations can be deadly, and the people who built Spark did a lot of performance testing and benchmarking! So let’s take a look at the exciting results. The first image showing some of the results is shown below.
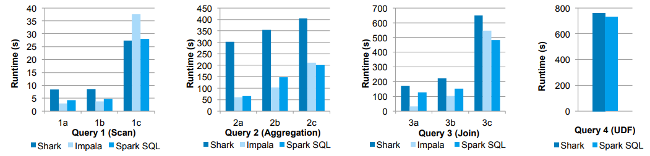
Performance comparisons in these experiments, they compared the performance of Spark SQL against Shark and Impala using the AMPLab Big Data benchmark, which uses a web analytics workload developed by Pavle et al. The model includes four query types with different parameters performing a scan, aggregation, join, and UDF-based MapReduce job. The dataset contained 110 GB of data after compression using the Parquet columnar format. We see that in all queries, Spark SQL is significantly faster than Shark and generally competitive with Impala. The most significant gap from Impala is in Query 3a, where Impala chooses a better join plan because query selectivity makes one of the tables very small.
Conclusion
Apache Spark is the most active open source big data project with hundreds of contributors.
In addition to being an open source project, Spark SQL has begun to gain mainstream industry adoption. It has already been deployed in massive environments. Facebook has an excellent case study on “Apache Spark @Scale: 60 TB+ Production Use Case.”
-
Relational data stores are easy to create and query. However, users and developers often prefer to write quickly interpretable declarative queries in a human-readable language such as SQL.
- RDD is perhaps the most significant contributor to all Spark success stories. It is essentially a data structure or a distributed memory abstraction.
- A Spark Data Frame is a distributed collection of rows (row types) with the same schema. It’s a Spark dataset organized into named columns.
Reference:
Image Source:
- https://en.wikipedia.org/wiki/Apache_Spark
- https://spark.apache.org/docs/2.1.2/streaming-programming-guide.html
I am a Machine Learning Enthusiast. Done some Industry level projects on Data Science and Machine Learning. Have Certifications in Python and ML from trusted sources like data camp and Skills vertex. My Goal in life is to perceive a career in Data Industry.






