This article was published as a part of the Data Science Blogathon.
Introduction
When it comes to productivity, the internet is flooded with advice and opinions from experts, specialists, data science enthusiasts, etc. but just knowing the right tool to do the work with ease is all you need.
As a Data Science Practitioner, you might have stumbled upon issues related to high RAM/CPU usages, problems loading large datasets, tracking the progress of certain functions, formatting code, and upgrading Python packages.
In this article, you will find 5 python packages to solve the aforementioned issues. Here we go!
1. Datatable
Datatable was started as a toolkit for performing big data (up to 100GB) operations on a single-node machine, at the maximum speed possible. It is closely related to R’s data.table and attempts to mimic its core algorithm and API’s. Currently, it’s in the Beta stage but can read large datasets quickly and is often faster than Pandas. Although, it lacks the flexibility that Pandas offer but you have the option to convert datatable dataframe to pandas dataframe within seconds. You can read more here.
Usage:
Let’s begin by installing datatable:
pip install datatable
In this example, we are going to import Kaggle’s Jane Street Market Prediction data which is around 5.8 GB in size and will show a side-by-side time comparison of loading datasets using pandas and datatable.
import pandas as pd import datatable as dt
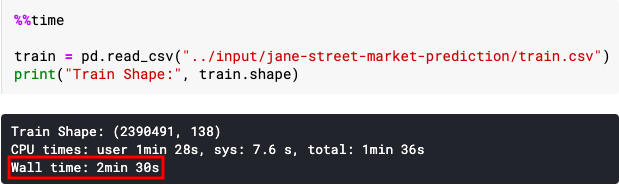
train = pd.read_csv("../input/jane-street-market-prediction/train.csv")
print("Train Shape:", train.shape)
data = dt.fread("../input/jane-street-market-prediction/train.csv")
print("Data Shape:", data.shape)
df = data.to_pandas()
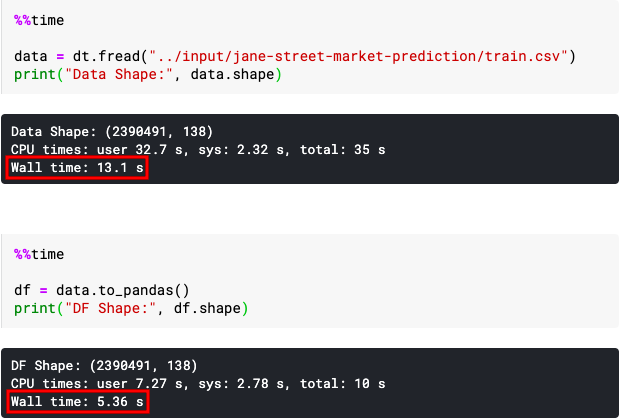
You can see that loading large datasets via datatable and converting them to pandas dataframe is much faster than loading large datasets via pandas itself.
2. Joblib
Joblib provides utilities for pipelining python jobs. It also provides utilities for saving and loading Python objects more efficiently. As an alternative to saving and loading python objects, you can use pickle too. But, why should you use joblib? Because it will help you to speed up any function using the Parallel method and is much more efficient than pickle working on Python objects containing large data ( joblib.dump & joblib.load ). Let’s see it in working using the sample code below:
Usage (Sample Code):
from joblib import Parallel, delayed import time
def sqr_fn(num):
time.sleep(1)
return num**2
Parallel(n_jobs=2)(delayed(sqr_fn)(i) for i in range(10))
First of all, we imported Parallel and delayed methods from joblib and python’s inbuilt time module (to purposely increase time in processing data so as to view the time difference). We created a function that gives the square of any number.
In the Parallel method, n_jobs is used to specify how many concurrent processes or threads should be used for routines that are parallelized with joblib. You can increase or decrease n_jobs based on the number of cores your processor has. If set to -1, all CPUs are used.
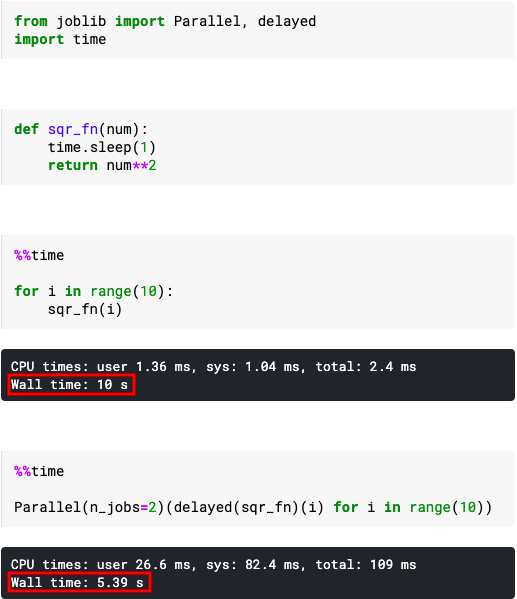
Running the for loop normally with the square function gave the results in 10 sec while using 2 concurrent processes reduce the time to approximately half.
3. Tqdm
Did you ever wish to have a progress bar while iterating so you can have an overall estimate of the time required for running your loop? Instantly make your loops show a smart progress meter – just wrap any iterable with tqdm(iterable), and you’re done!
Usage:
from tqdm import tqdm
for i in tqdm(range(100)):
sqr_fn(i)

Additionally, tqdm also provides a number of functions like set_description, update, etc. Head over to official documentation to know more.
4. Black
Are you a lazy programmer who doesn’t write well-formatted python code using PEP8 guidelines but wishes to do so? Worry not, Black comes to your rescue. Black is the uncompromising Python code formatter. Black gives you speed, determinism, and freedom from pycodestyle nagging about formatting. You will save time and mental energy on more important matters.
Installation:
pip install black
Usage:
To get started right away with sensible defaults:
black {source_file_or_directory}
You can run Black as a package if running it as a script doesn’t work:
python -m black {source_file_or_directory}
5. Pip-review
While maintaining a project environment, it becomes cumbersome to view which packages have an update or if we want to update the complete project environment or leave a few before updating. Pip-review is a new pip wrapper that lets you smoothly manage all available PyPI updates.
Installation:
pip install pip-review
Usages:
To automatically install all available updates:
pip-review --auto
To run interactively, ask to upgrade for each package:
pip-review --interactive
That’s all for this article. I hope you learned something new today. I’ll be back with another underrated topic that will help you at work or projects. Till then, HAPPY LEARNING!
My name is Siddharth Shankar. I’m an analytical professional with 2+ years of experience in managing day to day operational and technical aspects of the project along with data compiling, analysis and reporting. I’m a detail-oriented organized individual with a background in Statistics coupled with Software Engineering and PC Technician A+ certifications. To know more visit: https://www.linkedin.com/in/Sshankar7/
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.






