Introduction
The article introduces the concept of probability and the three main approaches used to determine the probability of an event: classical, frequentist, and Bayesian. It then delves into a detailed exploration of the Bayesian approach. In this article we are covering about the Bayesian inference, so mostly we will cover about topics related bayesian inference in artificial intelligence, what is bayes theorm, How bayesian inference works and it is used in real life.
Statistics is the study to help us quantify the way to measure uncertainty and hence, the concept of ‘Probability’ was introduced.
There are 3 different approaches available to determine the probability of an event.
- Classical
- Frequentist
- Bayesian
3 Approaches With the Help of a Simple Example
Suppose we’re rolling a fair six-sided die and we want to ask what is the probability that the die shows a four? Under the Classical framework, all the possible outcomes are equally likely i.e., they have equal probabilities or chances. Hence, answering the above question, there are six possible outcomes and they are all equally likely. So, the probability of a four on a fair six-sided die is just 1/6. This Classical approach works well when we have well-defined equally likely outcomes. But when things get a little subjective then it may become a little complex.
On the other hand, Frequentist definition requires us to have a hypothetical infinite sequence of a particular event and then to look at the relevant frequency in that hypothetical infinite sequence. In the case of rolling a fair six-sided die, if we roll it for the infinite number of times then 1/6th of the time, we will get a four and hence, the probability of rolling four in a six-sided die will be 1/6 under frequentist definition as well.
Now if we proceed a little further and ask if our die is fair or not. Under the frequentist paradigm, the probability is either zero when it’s not a fair die and one if it is a fair die because, under the frequentist approach, everything is measured from a physical perspective, and hence, the die can be either fair or not. We cannot assign a probability to the fairness of the die. Frequentists are very objective in how they define probabilities but their approach cannot give intuitive answers for some of the deeper subjective issues.
Advantage of The Bayesian Approach.
Bayesian perspective allows us to incorporate personal belief/opinion into the decision-making process. It takes into account what we already know about a particular problem even before any empirical evidence. Here we also have to acknowledge the fact my personal belief about a certain event may be different than others and hence, the outcome that we will get using the Bayesian approach may also be different.
For example, I may say that there is a 90% probability that it will rain tomorrow whereas my friend may say I think there is a 60% chance that it will rain tomorrow. So inherently Bayesian perspective is a subjective approach to probability, but it gives more intuitive results in a mathematically rigorous framework than the Frequentist approach. Let’s discuss this in detail in the following sections.
This article was published as a part of the Data Science Blogathon.
Table of contents
What is Bayes’ Theorem?
Simplistically, Bayes’ theorem can be expressed through the following mathematical equation
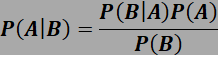
where A is an event and B is evidence. So, P(A) is the prior probability of event A and P(B) is evidence of event B. Hence, P(B|A) is the likelihood. The denominator is a normalizing constant. So, Bayes’ Theorem gives us the probability of an event based on our prior knowledge of the conditions that might be related to the event and updates that conditional probability when some new information or evidence comes up.
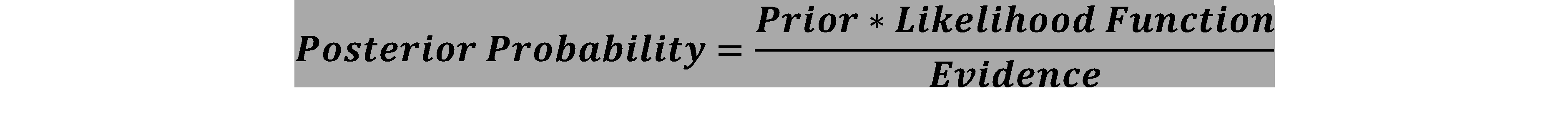
Now let’s focus on the 3 components of the Bayes’ theorem
- Prior
- Likelihood
- Posterior
Prior Distribution
This is the key factor in bayesian inference machine learning which allows us to incorporate our personal beliefs or own judgements into the decision-making process through a mathematical representation. Mathematically speaking, to express our beliefs about an unknown parameter θ we choose a distribution function called the prior distribution. This distribution is chosen before we see any data or run any experiment.
How do we choose a prior?
Theoretically, we define a cumulative distribution function for the unknown parameter θ. In basic context, events with the prior probability of zero will have the posterior probability of zero and events with the prior probability of one, will have the posterior probability of one. Hence, a good Bayesian framework will not assign a point estimate like 0 or 1 to any event that has already occurred or already known not to occur. A very handy widely used technique of choosing priors is using a family of distribution functions that is sufficiently flexible such that a member of the family will represent our beliefs. Now let’s understand this concept a little better.
- Conjugate Priors – Conjugacy happens when the final posterior distribution belongs to the family of similar probability density functions as the prior belief but with new parameter values updated to reflect new evidence/information. Examples Beta-Binomial, Gamma -Poisson or Normal-Normal.
- Non-conjugate Priors –Now, it is also quite possible that expressing personal belief in terms of a suitable conjugate prior may not be feasible. In such cases, simulation tools are applied to approximate the posterior distribution. An example can be Gibbs sampler.
- Un-informative prior – Another approach is to minimize the amount of information that goes into the prior function to reduce the bias. This is an attempt to have the data have maximum influence on the posterior. For these cases, we refer to these priors as uninformative priors, but the results might be pretty similar to the frequentist approach.
Likelihood
Suppose θ is the unknown parameter that we are trying to estimate. Let’s represent fairness of a coin with θ. Now to check the fairness, we are flipping a coin infinitely and each time it is either appearing as ‘head’ or ‘tail’ and we are assigning a 1 or 0 value accordingly. This is known as the Bernoulli Trials. Probability of all the outcomes or ‘X’s taking some value of x given a value of theta. We’re viewing each of these outcomes as independent and hence, we can write this in product notation.We express this as the probability of observing the actual data that we collected (head or tail), conditioned on a value of the parameter theta (fairness of coin).
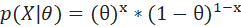
This is the concept of likelihood which is the density function thought of as a function of theta. To maximize the likelihood i.e., to make the event most likely to occur for the data we have, we will choose the theta that will give us the largest value of the likelihood. This is referred to as the maximum likelihood estimate or MLE. Additionally, a quick reminder is that the generalization of the Bernoulli when we have N repeated and independent trials is a binomial. We will see the application later in the article.
Posterior Distribution
This is the result or output of the Bayes’ Theorem. A posterior probability is the revised or updated probability of an event occurring after taking into consideration new information. We calculate the posterior probability ( p(\theta|X) ), meaning how probable our hypothesis about ( \theta ) is given the observed evidence.
Mechanism of Bayesian Inference:
The Bayesian approach treats probability as a degree of beliefs about certain event given the available evidence. In Bayesian Learning, Theta is assumed to be a random variable. Let’s understand the Bayesian inference mechanism a little better with an example.
Inference example using Frequentist vs Bayesian approach: Suppose my friend challenged me to take part in a bet where I need to predict if a particular coin is fair or not. She told me “Well; this coin turned up ‘Head’ 70% of the time when I flipped it several times. Now I am giving you a chance to flip the coin 5 times and then you have to place your bet.” Now I flipped the coin 5 times and Head came up twice and tail came up thrice. At first, I thought like a frequentist.
So, θ is an unknown parameter which is a representation of fairness of the coin and can be defined as
θ = {fair, loaded}
Additionally, I assumed that the outcome variable X (whether head or tail) follows Binomial distribution with the following functional representation
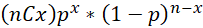
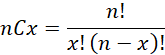
our case n=5.
Now my likelihood function will be
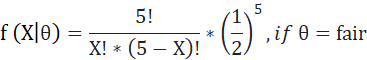
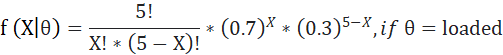
I saw that head came up twice, so my X =2.
When X=2, f (θ|X=2) = 0.31 if θ =fair
= 0.13 if θ =loaded
Therefore, using the frequentist approach I can conclude that maximum likelihood i.e., MLE (theta hat) = fair.

Now comes the tricky part. If the question comes how sure am I about my prediction? I will not be able to answer that question perfectly or correctly as in a frequentist world, a coin is a physical object and hence, my probability can be either 0 or 1 i.e., the coin is either fair or not.
Here comes the role of Bayesian inference which will tell us the uncertainty in my prediction i.e., P(θ|X=2). The Bayesian inference allows us to incorporate our knowledge/information about the unknown parameter θ even before looking at any data. Here, suppose I know my friend pretty well and I can say with 90 % probability that she has given me a loaded coin.
Therefore, my prior P(loaded)=0.9. I can now update my prior belief with data and get the posterior probability using Bayes’ Theorem.
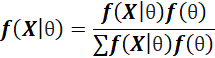
My numerator calculation will be as follows-
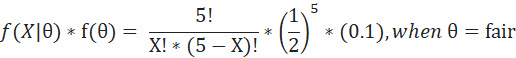
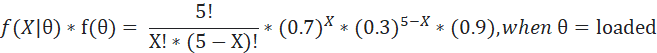
The denominator is a constant and can be calculated as the expression below. Please note that we are here basically summing up the expression over all possible values of θ which is only 2 in this case i.e., fair or loaded.
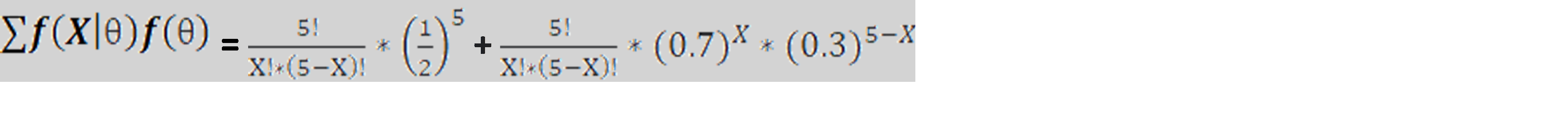
Therefore, after replacing X with 2, we can calculate the Bayesian probability of the coin being loaded or fair. Do it yourself and let me know your answer! However, you will realize that this conclusion contains more information to make a bet than the frequentist approach.
How is Bayesian inference used in real life?
Bayesian inference, a reliable statistical method, has been applied in different fields. Adapting your beliefs based on new information is necessary. Here are some actual situations:
Healthcare services or medical treatment
Doctors often use Bayesian inference to assess the probability of a patient having a particular condition based on symptoms, test results, and medical history.
During drug development, pharmaceutical companies use Bayesian methods to analyze clinical trial data and assess the effectiveness and safety of drugs.
Financial management
Financial institutions use Bayesian models to evaluate the chance of loans defaulting or investments not meeting expectations.
Credit card firms use Bayesian networks to identify abnormal spending patterns that may indicate possible fraud.
Promoting and marketing goods or services.
Customer segmentation is the practice of grouping customers based on their behavior, preferences, and demographics using Bayesian methods.
Netflix and Amazon make use of Bayesian inference to suggest products or content by analyzing users’ past interactions and likes.
Artificial intelligence allows machines to enhance their abilities by analyzing data and evolving gradually.
Email services utilize Bayesian classifiers to distinguish between spam and genuine emails when categorizing spam.
Bayesian techniques are utilized by facial recognition systems for image identification and classification.
Various applications
Weather forecasters use Bayesian models to predict weather patterns by analyzing historical data and current conditions.
Bayesian methods are utilized in language models for examining and generating human language within natural language processing.
Bayesian analysis is used in legal studies and forensic science to assess the probability of a particular event taking place based on the evidence at hand.
Application of Bayesian Inference in financial risk modeling:
Bayesian inference has found its application in various widely used algorithms e.g., regression, Random Forest, neural networks, etc. Apart from that, it also gained popularity in several Bank’s Operational Risk Modelling. Bank’s operation loss data typically shows some loss events with low frequency but high severity. For these typical low-frequency cases, Bayesian inference turns out to be useful as it does not require a lot of data.
Previously, operational risk models relied on Frequentist methods. However, due to their inability to infer parameter uncertainty, Bayesian inference became considered more informative. It has the capacity to combine expert opinion with actual data to derive posterior distributions of severity and frequency distribution parameters. Generally, in this type of statistical modeling, banks divide their internal loss data into several buckets. They determine the frequencies of losses in each bucket through expert judgment and then fit them into probability distributions.
Conclusion
This article thoroughly covers the three approaches of probability—classical, frequentist, and Bayesian. It emphasizes that the Bayesian approach is a more subjective and intuitive technique that enables updating of probability in light of fresh evidence and integration of previous views. Along with discussing the posterior, likelihood, and prior—three essential elements of Bayes’ Theorem—the article provides an example of the Bayesian inference process. The paper also presents the use of Bayesian inference in financial risk modeling, emphasizing its benefits over frequentist methodology. All things considered, the paper does a good job of illuminating the flexibility and real-world uses of the Bayesian framework in statistical analysis and decision-making. Hope you like the article and get understanding about the bayesian inference, bayesian probabilistic inference nad about the how bayesian inference works.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.
Frequently Asked Questions?
Q1. What is an example of a Bayes inference?
A. Example of a Bayes inference: Predicting the probability of rain tomorrow based on historical weather data and current atmospheric conditions.
Q2. What is Bayesian inference for dummies?
A. Bayesian inference for dummies: It’s a statistical method for updating beliefs or predictions based on new evidence. Imagine you have an initial belief (prior), then you gather new data (likelihood), and finally, you update your belief (posterior) taking into account both the prior and the new evidence.
Q3. What is Bayesian theory in artificial intelligence?
A. AI uses Bayes’ theorem to update beliefs based on new info. Starts with a guess (prior), gets new data (evidence), improves guess (posterior). Helps AI learn and make decisions in uncertain situations.
Q4. What are the two basic types of inferences in AI?
A. Deductive: General to specific, certain.Inductive: Specific to general, probable.







Thank you Ananya, I enjoyed your article. Perhaps you could supply a worked example of financial risks methods.
Thank you Ananya. I enjoyed your article. Perhaps you could give a worked example for financial risk management?
VERY COMPREHENSIVE AND EASY TO LEARN . I THEREFORE RECOMMEND IT TO STUDENTS AROUND THE GLOBE TO USE SO THAT THEY WILL ALSO BENEFIT FROM IT LIKE ME SO I URGE THAT STUDENTS SHOULD USE TO BENEFIT