Introduction
Bayesian Statistics (bayesian probability) continues to remain one of the most powerful things in the ignited minds of many statisticians. In several situations, it does help us solve business problems, even when there is data involved in these problems. To say the least, knowledge of statistics will allow you to work on complex data analysis problems in machine learning and data science, irrespective of the size of the data.
In the 1770s, Thomas Bayes introduced the ‘Bayes Theorem.’ Even centuries later, the importance of ‘Bayesian Statistics’ hasn’t faded away. In this beginner’s guide on Bayesian Statistics, I’ve tried to explain the concepts in a simplistic manner with examples. Prior knowledge of basic probability & statistics is desirable. You should check out this course to get a comprehensive low down on statistics and probability. By the end of this article, you will have a concrete understanding of Bayesian Statistics and its associated concepts.
In this article, you will explore the role of Bayesian statistics in AI, delving into its applications and advantages. We will discuss a Bayesian statistics example to illustrate its practical use and highlight how Bayesian statistics in machine learning can improve predictive performance. Finally, we will provide a glimpse into implementing Bayesian machine learning in Python, showcasing its potential to streamline complex data analysis tasks.
Learning Objectives
- Discover Bayesian Statistics and Bayesian Inference; Bayesian Statistics Example.
- Learn the drawbacks of frequentist statistics and how it leads to the need for Bayesian Statistics.
- Understand the methods to test the significance of the model, like p-value, confidence interval, etc.

Table of contents
What Is Frequentist Statistics?
The debate between frequentist and bayesian have haunted beginners for centuries. Therefore, it is important to understand the difference between the two and how there exists a thin line of demarcation!
It is the most widely used statistical inference technique in the statistical world. In fact, generally, it is the first school of thought that a person entering the world of statistics comes across.
Frequentist Statistics tests whether an event (hypothesis) occurs or not. It calculates the probability of an event in the long run of the experiment (i.e., the experiment is repeated under the same conditions to obtain the outcome).
Here, the sampling distributions of fixed size are taken. Then, the experiment is theoretically repeated an infinite number of times but practically done with a stopping intention. For example, I perform an experiment with a stopping intention in mind that I will stop the experiment when it is repeated 1000 times, or I see a minimum of 300 heads in a coin toss.
Let’s go deeper now.
Now, we’ll understand frequentist statistics using an example of a coin toss. The objective is to estimate the fairness of the coin. Below is a table representing the frequency of heads:

We know that the probability of getting a head, on tossing a fair coin is 0.5. No. of heads represents the actual number of heads obtained. Difference is the difference between 0.5*(No. of tosses) - no. of heads.
The important thing to note is that, though the difference between the actual number of heads and the expected number of heads( 50% of the number of tosses) increases as the number of tosses are increased, the proportion of the number of heads to the total number of tosses approaches 0.5 (for a fair coin).
This experiment presents us with a very common flaw found in the frequentist approach, i.e., Dependence of the result of an experiment on the number of times the experiment is repeated. To know more about frequentist statistical methods, you can head to this excellent course on inferential statistics.
Inherent Flaws in Frequentist Statistics
Till here, we’ve seen just one flaw in frequentist statistics. Well, it’s just the beginning.
The 20th century saw a massive upsurge in the frequentist statistics being applied to numerical models to check whether one sample is different from the other, whether a parameter is important enough to be kept in the model, and various other manifestations of hypothesis testing. But frequentist statistics suffered some great flaws in its design and interpretation, which posed a serious concern in all real-life problems. For example:
1. p-values measured against a sample (fixed size) statistic with some stopping intention changes with change in intention and sample size. i.e., If two persons work on the same dataset and have different stopping intentions, they may get two different p- values for the same dataset, which is undesirable.
For example, Person A may choose to stop tossing a coin when the total count reaches 100, while B stops at 1000. For different sample sizes, we get different t-scores and different p-values. Similarly, the intention to stop may change from a fixed number of flips to the total duration of flipping. In this case, too, we are bound to get different p-values.
2. Confidence Interval (C.I) like p-value depends heavily on the sample size. This makes the stopping potential absolutely absurd since no matter how many persons perform the tests on the same data, the results should be consistent.
3. Confidence Intervals (C.I) are not probability distributions; therefore, they do not provide the most probable value for a parameter and the most probable values.
These three reasons are enough to get you going into thinking about the drawbacks of the frequentist approach and why there is a need for the bayesian approach. Let’s find it out.
From here, we’ll first understand the basics of Bayesian Statistics.
What Is Bayesian Statistics?
Bayesian statistics is a statistical approach that utilizes Bayes’ theorem for data analysis and parameter estimation. What sets Bayesian statistics apart is that all observed and unobserved parameters in a statistical model are assigned a joint probability distribution, known as the prior and data distributions. Bayesian inference is a statistical inference method that uses Bayes’ theorem to revise the probability of a hypothesis as new evidence or information is obtained. Bayesian inference is a crucial statistical technique, particularly in mathematical statistics.
“Bayesian statistics is a mathematical procedure that applies probabilities to statistical problems. It provides people with the tools to update their beliefs in the evidence of new data.”
Did you get that? Let me explain it with an example:
Suppose, out of all the 4 championship races (F1) between Niki Lauda and James Hunt, Niki won 3 times while James managed only 1.
So, if you were to bet on the winner of the next race, who would he be?
I bet you would say Niki Lauda.
Here’s the twist. What if you are told that it rained once when James won and once when Niki won, and it is definite that it will rain on the next date? So, who would you bet your money on now?
By intuition, it is easy to see that the chances of winning for James have increased drastically. But the question is: by how much?
To understand this problem, we need to become familiar with some concepts, the first of which is the conditional probability (explained below).
In addition, there are certain pre-requisites:
Pre-Requisites:
- Linear Algebra: To refresh your basics, you can check out Khan’s Academy Algebra.
- Probability and Basic Statistics: To refresh your basics, you can check out another course by Khan Academy.
Conditional Probability
It is defined as the: Probability of an event A given B equals the probability of B and A happening together divided by the probability of B.”
For example: assume two partially intersecting sets, A and B, as shown below.
Set A represents one set of events, and Set B represents another. We wish to calculate the probability of A given B has already happened. Let’s represent the happening of event B by shading it with red.

Now since B has happened, the part which now matters for A is the part shaded in blue which is interestingly  . So, the probability of A given B turns out to be:
. So, the probability of A given B turns out to be:
Therefore, we can write the formula for event B given A has already occurred by:
or
Now, the second equation can be rewritten as:
This is known as Conditional Probability.
Let’s try to answer a betting problem with this technique.
Suppose B is the event of James Hunt winning and A is the event of rain. Therefore,
- P(A) = 1/2, since it rained twice out of four days.
- P(B) is 1/4, since James won only one race out of four.
- P(A|B) = 1, since it rained every time when James won.
Substituting the values in the conditional probability formula, we get the probability to be around 50%, which is almost the double of 25% when rain was not taken into account (Solve it at your end).
This further strengthened our belief that James would win in the light of new evidence, i.e., rain. You must be wondering that this formula closely resembles something you might have heard a lot about. Think!
Probably, you guessed it right. It looks like Bayes’ Theorem.
Bayes theorem is built on top of conditional probability and lies at the heart of Bayesian Inference. Let’s understand it in detail now.
Bayes Theorem
Bayes Theorem comes into effect when multiple events form an exhaustive set with another event B. This could be understood with the help of the below diagram.

Now, B can be written as
So, the probability of B can be written as,
But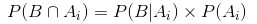
So, by replacing P(B) in the equation of conditional probability, we get

This is the equation of Bayes Theorem.
What Is Bayesian Inference?
There is no point in diving into the theoretical aspect of it. So, we’ll learn how it works! Let’s take an example of coin tossing to understand the idea behind Bayesian inference.
An important part of bayesian inference is the establishment of parameters and models.
Models are the mathematical formulation of observed events. Parameters are the factors in the models affecting the observed data. For example, in tossing a coin, the fairness of the coin may be defined as the parameter of the coin denoted by θ. The outcome of the events may be denoted by D.
Answer this now. What is the probability of 4 heads out of 9 tosses(D), given the fairness of the coin (θ) i.e P(D|θ)?
Wait, did I ask the right question? No.
We should be more interested in knowing: Given an outcome (D), what is the probability of the coin being fair (θ=0.5)
Let’s represent it using the Bayes rule:
P(θ|D)=(P(D|θ) X P(θ))/P(D)
Here, P(θ)is the prior, i.e., the strength of our belief in the fairness of the coin before the toss. It is perfectly okay to believe that coin can have any degree of fairness between 0 and 1.
P(D|θ) is the likelihood of observing our result given our distribution for θ. If we knew that coin was fair, this gives the probability of observing the number of heads in a particular number of flips.
P(D) is the evidence. This is the probability of data as determined by summing (or integrating) across all possible values of θ, weighted by how strongly we believe in those particular values of θ.
If we had multiple views of what the fairness of the coin is (but didn’t know for sure), then this tells us the probability of seeing a certain sequence of flips for all possibilities of our belief in the coin’s fairness.P(θ|D) is the posterior belief of our parameters after observing the evidence i.e. the number of heads.
From here, we’ll dive deeper into the mathematical implications of this concept. Don’t worry. Once you understand them, getting to their mathematics is pretty easy.
To define our model correctly, we need two mathematical models beforehand. One represents the likelihood function P(D|θ), and the other for representing the distribution of prior beliefs. The product of these two gives the posterior belief P(θ|D) distribution.
Since prior and posterior are both beliefs about the distribution of fairness of coin, intuition tells us that both should have the same mathematical form. Keep this in mind. We will come back to it again.
So, there are several functions that support the existence of bayes theorem. Knowing them is important in bayesian data analysis; hence I have explained them in detail.
Bernoulli Likelihood Function
Let’s recap what we learned about the likelihood function. So, we learned that:
It is the probability of observing a particular number of heads in a particular number of flips for a given fairness of coin. This means our probability of observing heads/tails depends upon the fairness of the coin (θ).P(y=1|θ)= [If coin is fair θ=0.5, probability of observing heads (y=1) is 0.5]
P(y=0|θ)= [If coin is fair θ=0.5, probability of observing tails(y=0) is 0.5]
It is worth noticing that representing 1 as heads and 0 as tails is just a mathematical notation to formulate a model. We can combine the above mathematical definitions into a single definition to represent the probability of both outcomes.
P(y|θ) =
This is called the Bernoulli Likelihood Function, and the task of coin flipping is called Bernoulli’s trials.
y={0,1},θ=(0,1)
And, when we want to see a series of heads or flips, its probability is given by:
Furthermore, if we are interested in the probability of the number of heads z turning up in N number of flips, then the probability is given by:
Prior Belief Distribution
This distribution is used to represent our strengths in beliefs about the parameters based on previous experiences. But what if one has no previous experience?
Don’t worry. Mathematicians have devised methods to mitigate this problem too. It is known as uninformative priors. I would like to inform you beforehand that it is just a misnomer. Every uninformative prior always provides some information event the constant distribution prior.
Well, the mathematical function used to represent the prior beliefs is known as beta distribution. It has some very nice mathematical properties which enable us to model our beliefs about a binomial distribution.
The probability density function of the beta distribution is of the form:
where our focus stays on the numerator. The denominator is there just to ensure that the total probability density function upon integration evaluates to 1.

You, too, can draw the beta distribution for yourself using the following code in R:
> library(stats)
> par(mfrow=c(3,2))
> x=seq(0,1,by=o.1)
> alpha=c(0,2,10,20,50,500)
> beta=c(0,2,8,11,27,232)
> for(i in 1:length(alpha)){
y<-dbeta(x,shape1=alpha[i],shape2=beta[i])
plot(x,y,type="l")
}
Note: α and β are intuitive to understand since they can be calculated by knowing the mean (μ) and standard deviation (σ) of the distribution. In fact, they are related as:
If the mean and standard deviation of a distribution are known, then their shape parameters can be easily calculated.
Here are the inferences drawn from the graphs above:
- When there was no toss, we believed that every fairness of coin was possible, as depicted by the flat line.
- When there was more number of heads than tails, the graph showed a peak shifted towards the right side, indicating a higher probability of heads, and that coin is not fair.
- As more tosses are done, and heads continue to come in larger proportion, the peak narrows, increasing our confidence in the fairness of the coin value.
Posterior Belief Distribution
The reason that we chose prior belief is to obtain a beta distribution. This is because when we multiply it with a likelihood function, the posterior distribution yields a form similar to the prior distribution, which is much easier to relate to and understand. If this much information whets your appetite, I’m sure you are ready to walk the extra mile.
Let’s calculate posterior belief using bayes theorem.
Calculating posterior belief using Bayes Theorem
Now, our posterior belief becomes,
This is interesting. Just knowing the mean and standard distribution of our belief about the parameter θ and by observing the number of heads in N flips, we can update our belief about the model parameter(θ).
Let’s understand this with the help of a simple example:
Suppose you think that a coin is biased. It has a mean (μ) bias of around 0.6 with a standard deviation of 0.1.
Then,
α= 13.8 , β=9.2
i.e, our distribution will be biased on the right side. Suppose you observed 80 heads (z=80) in 100 flips(N=100). Let’s see how our prior and posterior beliefs are going to look:
prior = P(θ|α,β)=P(θ|13.8,9.2)Posterior = P(θ|z+α,N-z+β)=P(θ|93.8,29.2)
Let’s visualize both the beliefs on a graph:
The R code for the above graph is as follows:
> library(stats)
> x=seq(0,1,by=0.1)
> alpha=c(13.8,93.8)
> beta=c(9.2,29.2)
> for(i in 1:length(alpha)){
y<-dbeta(x,shape1=alpha[i],shape2=beta[i])
plot(x,y,type="l",xlab = "theta",ylab = "density")}
As more and more flips are made, and new data is observed, our beliefs get updated. This is the real power of Bayesian Inference.
Test for Significance – Frequentist vs. Bayesian
Without going into the rigorous mathematical structures, this section will provide you with a quick overview of different approaches of frequentist and bayesian methods to test for significance and difference between groups and determine which method is most reliable.
p-value
In this, the t-score for a particular sample from a sampling distribution of fixed size is calculated. Then, p-values are predicted. We can interpret p values as (taking an example of the p-value as 0.02 for a distribution of mean 100): There is a 2% probability that the sample will have a mean equal to 100.
This interpretation suffers from the flaw that for sampling distributions of different sizes, one is bound to get different t-score and hence different p-value. It is completely absurd. A p-value less than 5% does not guarantee that the null hypothesis is wrong, nor does a p-value greater than 5% ensure that the null hypothesis is right.
Confidence Intervals
Confidence Intervals also suffer from the same defect. Moreover, since C.I is not a probability distribution there is no way to know which values are most probable. So, Credible Interval is used with regard to Bayes theorem.
Bayes Factor
Bayes factor is the equivalent of the p-value in the bayesian framework. Let’s understand it in a comprehensive manner.
The null hypothesis in the bayesian framework assumes ∞ probability distribution only at a particular value of a parameter (say θ=0.5) and a zero probability elsewhere. (M1)
The alternative hypothesis is that all values of θ are possible, hence a flat curve representing the distribution. (M2)
Now, the posterior distribution of the new data looks like the one below.
Bayesian statistics adjusted the credibility (probability) of various values of θ. It can be easily seen that the probability distribution has shifted towards M2 with a value higher than M1, i.e., M2 is more likely to happen.
Bayes factor does not depend upon the actual distribution values of θ but the magnitude of the shift in values of M1 and M2.
In panel A (shown above): the left bar (M1) is the prior probability of the null hypothesis.
In panel B (shown), the left bar is the posterior probability of the null hypothesis.
Bayes factor is defined as the ratio of the posterior odds to the prior odds,
To reject a null hypothesis, a BF <1/10 is preferred.
We can see the immediate benefits of using the Bayes Factor instead of p-values since they are independent of intentions and sample size.
To reject a null hypothesis, a BF <1/10 is preferred.
We can see the immediate benefits of using the Bayes Factor instead of p-values since they are independent of intentions and sample size.
High-Density Interval (HDI)
HDI is formed from the posterior distribution after observing the new data. Since HDI is a probability, the 95% HDI gives the 95% most credible values. It is also guaranteed that 95 % of values will lie in this interval, unlike C.I.
Notice how the 95% HDI in the prior distribution is wider than the 95% posterior distribution. This is because our belief in HDI increases upon observation of new data.
Conclusion
The aim of this tutorial was to get you thinking about the different types of statistical philosophies out there and how just one of them cannot be used in every situation. It’s high time that both philosophies are merged to mitigate real-world problems by addressing the flaws of the other. Part II of this series will focus on the Dimensionality Reduction techniques using MCMC (Markov Chain Monte Carlo) algorithms. Part III will be based on creating a Bayesian regression model from scratch and interpreting its results in R.
Hope you like the article! Bayesian statistics in AI plays a crucial role in modeling uncertainty. A Bayesian statistics example is spam detection, while Bayesian statistics in machine learning improves predictive accuracy. Implementing Bayesian machine learning in Python simplifies complex data analysis tasks.
Key Takeaways
- The comparison between Frequentist and bayesian statistics.
- Conditional probability and Bayes theorem derivation.
- Three different Bayesian inference functions.
- Significant tests for Bayes’ theorem.
Q1. What are the differences between Bayesian statistics and Frequentist statistics?
A. Frequentist statistics don’t take the probabilities of the parameter values, while bayesian statistics take into account conditional probability.
Q2. What is Bayesian statistics in simple words?
A. Bayesian statistics is the calculation of outcomes based on the probabilities of the independent variables.
Q3. What is a simple example of Bayesian inference?
A. If a diagnosisis test has precision and recall of 99%, then the probability of having a disease after getting a positive result is not 99%. Because it also depends on the probability of having the disease in the total population.
Q4. What is Bayesian statistics in machine learning?
Bayesian statistics is a probabilistic approach to machine learning that uses Bayes’ theorem to update beliefs as new evidence becomes available. It provides a framework for modeling uncertainty, incorporating prior knowledge, and making predictions.
I am a perpetual, quick learner and keen to explore the realm of Data analytics and science. I am deeply excited about the times we live in and the rate at which data is being generated and being transformed as an asset. I am well versed with a few tools for dealing with data and also in the process of learning some other tools and knowledge required to exploit data.







Thx for this great explanation. I'm a beginner in statistics and data science and I really appreciate it. If you're interested to see another approach, how toddler's brain use Bayesian statistics in a natural way there is a few easy-to-understand neuroscience courses : http://www.college-de-france.fr/site/en-stanislas-dehaene/_course.htm
Hey one question `difference` -> 0.5*(No. of tosses) - no. of heads is it correct?
@Nikhil ...Thanks for bringing it to the notice. It should be no.of heads - 0.5(No.of tosses).
Did you miss the index i of A in the general formula of the Bayes' theorem on the left hand side of the equation (section 3.2)?
No, I didn't. :)