Introduction
This article concerns one of the supervised ML classification algorithms – KNN (k-nearest neighbours) algorithm. The KNN classifier in Python is one of the simplest and widely used classification algorithms, where a new data point is classified based on its similarity to a specific group of neighboring data points. This tutorial provides an overview of the KNN algorithm, its implementation in Python, and its applications.
Table of contents
This article was published as a part of the Data Science Blogathon.
What is KNN Algorithm?
kNN (k-Nearest Neighbors) is a supervised machine learning algorithm. In supervised learning, the algorithm learns from labeled training data, where each data point is associated with a known label or outcome. kNN specifically requires labeled training data to classify new data points based on their similarity to existing data points with known class labels. Therefore, it falls under the category of supervised learning algorithms.
Distinguishing Features of KNN
kNN (k-Nearest Neighbors) algorithm is a simple yet powerful technique in supervised machine learning, applicable not only to classification but also regression tasks. Its distinguishing feature lies in its instance-based learning approach, where it memorizes the entire training dataset rather than constructing a model. When tasked with predicting the class or value of a new data point, kNN identifies its k nearest neighbors based on a chosen distance metric, such as Euclidean or Manhattan distance. The predicted class in classification tasks or the average value in regression tasks is then determined by majority voting among these neighbors.
This algorithm’s simplicity and intuitiveness make it an attractive choice, especially for beginners in machine learning. However, kNN’s performance hinges on several key factors. Parameter selection, particularly the choice of k, significantly impacts its effectiveness. A smaller k value yields more flexible decision boundaries but risks overfitting, while a larger k value may lead to oversmoothing. Additionally, feature scaling and the selection of an appropriate distance metric are crucial for accurate predictions on test data.
While kNN excels in its ability to handle multiclass classification tasks and regression problems, its computational complexity during prediction can be a drawback, especially for large datasets. Nonetheless, with proper parameter tuning and preprocessing steps, kNN remains a versatile and effective algorithm for various classification and regression problems, relying on the concept of majority voting for decision-making.
Also Read: A Complete Beginner’s Guide to Data Visualization
Working of KNN Classifier in Python
For a given data point in the set, the algorithms find the distances between this and all other K numbers of datapoint in the dataset close to the initial point and votes for that category that has the most frequency. Usually, Euclidean distance is taking as a measure of distance. Thus the end resultant model is just the labeled data placed in a space. This algorithm is popularly known for various applications like genetics, forecasting, etc. The algorithm is best when more features are present and out shows SVM in this case.
KNN reducing overfitting is a fact. On the other hand, there is a need to choose the best value for K. So now how do we choose K? Generally we use the Square root of the number of samples in the dataset as value for K. An optimal value has to be found out since lower value may lead to overfitting and higher value may require high computational complication in distance. So using an error plot may help. Another method is the elbow method. You can prefer to take root else can also follow the elbow method.
Let’s dive deep into the different steps of K-NN for classifying a new data point:
Step 1: Select the value of K neighbors(say k=5)
Step 2: Find the K (5) nearest data point for our new data point based on euclidean distance(which we discuss later)
Step 3: Among these K data points count the data points in each category
Step 4: Assign the new data point to the category that has the most neighbors of the new datapoint
Also Read: 15 Most Important Features of Scikit-Learn!
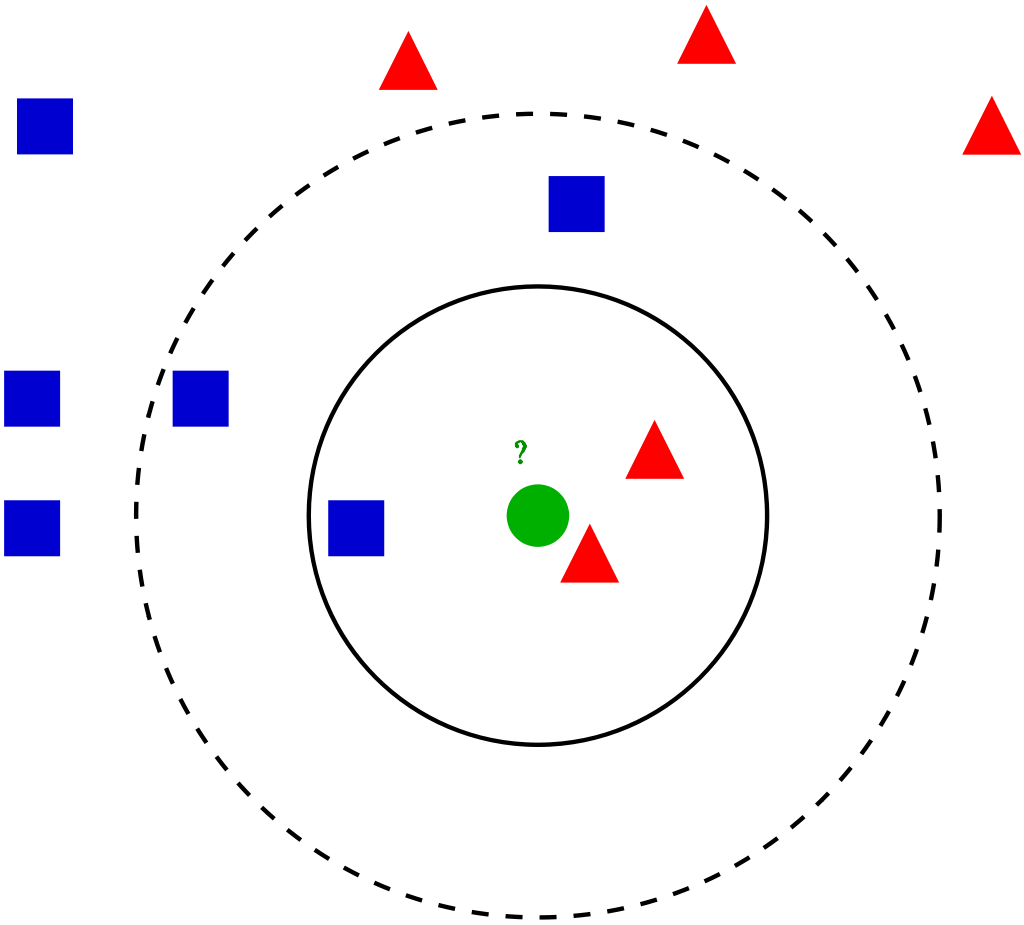
KNN Classifier in Python Tutorial
Let’s go through an example problem for getting a clear intuition on the K -Nearest Neighbor classification. We are using the Social network ad dataset (Download). The dataset contains the details of users in a social networking site to find whether a user buys a product by clicking the ad on the site based on their salary, age, and gender.
.png)
Step 1: Import Libraries
Let’s start the programming by importing essential libraries:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import sklearnStep 2: Importing a Dataset
Importing of the dataset and slicing it into independent and dependent variables:
dataset = pd.read_csv('Social_Network_Ads.csv')
X = dataset.iloc[:, [1, 2, 3]].values
y = dataset.iloc[:, -1].valuesimport numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import sklearn
dataset = pd.read_csv('Social_Network_Ads.csv')
X = dataset.iloc[:, [1, 2, 3]].values
y = dataset.iloc[:, -1].values
print(len(X))
Step 3: Encode LabelEncode
Since our dataset containing character variables we have to encode it using LabelEncoder:
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
X[:,0] = le.fit_transform(X[:,0])Step 4: Train Test and Split on Dataset
We are performing a train test split on the dataset. We are providing the test size as 0.20, that means our training sample contains 320 training set and test sample contains 80 test set.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20, random_state = 0)
Next, we are doing feature scaling to the training and test set of independent variables for reducing the size to smaller values:
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
Step 5: Training KNN Model
Now we have to create and train the K Nearest Neighbor model with the training set:
from sklearn.neighbors import KNeighborsClassifier
classifier = KNeighborsClassifier(n_neighbors = 5, metric = 'minkowski', p = 2)
classifier.fit(X_train, y_train)Also Read: A Guide on Deep Learning: From Basics to Advanced Concepts
Model Creation Parameters
Model Creation Parameters In constructing our model, we consider three crucial parameters. The first parameter, n_neighbors, is set to 5, implying that 5 neighboring points are utilized for classifying a given point. Additionally, we select the Minkowski distance metric, which allows for flexibility in distance calculations. The equation for Minkowski distance incorporates a parameter, p, which determines the type of distance metric used:

- For p = 1, Manhattan Distance
- For p = 2, Euclidean Distance
- For p = infinity, Chebyshev Distance
In our problem, we opt for p = 2, indicating the use of Euclidean Distance. This choice is pertinent to our target value and the optimal value of k. With our model thus configured, we proceed to predict the output for the test set.
y_pred = classifier.predict(X_test)
Comparing true and predicted value in the dataframe:
ylabel
This is the output of the test data, denoting the true class labels or target values. It represents the ground truth against which the predictions made by the kNN classifier are compared for evaluation purposes. Each value in the array corresponds to the actual class label or target value of the respective data point in the test dataset.
array([0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1,
0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0,
1, 0, 0, 1, 0, 1, 1, 0, 0, 0, 1, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1,
0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 1, 1, 0, 1,
1, 0, 0, 1, 0, 0, 0, 1, 0, 1, 1, 1], dtype=int64)y_pred
array([0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1,
0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0,
1, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1,
0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 1, 0, 0, 1,
1, 0, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1], dtype=int64)We can evaluate our model using the confusion matrix and accuracy score by comparing the predicted and actual test values:
from sklearn.metrics import confusion_matrix,accuracy_score
cm = confusion_matrix(y_test, y_pred)
ac = accuracy_score(y_test,y_pred)
Confusion Matrix
[[64 4]
[ 3 29]]Accuracy is 0.95
The accuracy of our model is 95%, indicating its strong performance in making correct predictions. Below is the full code used for this problem:
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Importing the dataset
dataset = pd.read_csv('Social_Network_Ads.csv')
X = dataset.iloc[:, [2, 3]].values
y = dataset.iloc[:, -1].values
# Splitting the dataset into the Training set and Test set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20, random_state = 0)
# Feature Scaling
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
# Training the K-NN model on the Training set
from sklearn.neighbors import KNeighborsClassifier
classifier = KNeighborsClassifier(n_neighbors = 5, metric = 'minkowski', p = 2)
classifier.fit(X_train, y_train)
# Predicting the Test set results
y_pred = classifier.predict(X_test)
# Making the Confusion Matrix
from sklearn.metrics import confusion_matrix, accuracy_score
cm = confusion_matrix(y_test, y_pred)
ac = accuracy_score(y_test, y_pred) This code snippet demonstrates the entire workflow, including data preprocessing, model training, prediction, and evaluation using a confusion matrix and accuracy score. Additionally, it introduces the concepts of estimator and hyperparameters, specifying the parameters for the kNN classifier.
Also Read: Popular Classification Models for Machine Learning
Conclusion
In conclusion, we have looked into the intricacies of the K Nearest Neighbor (KNN) algorithm and its implementation in Python. We can explore its potential in various classification problems by understanding its functionality and application. Through the steps outlined, including preparing the training dataset, cross-validation, and model evaluation, we’ve provided a comprehensive guide to building and utilizing a KNN classifier in supervised machine learning tasks. The KNN classifier is valuable for tackling classification challenges, particularly in scenarios with non-linear or complex decision boundaries. As we continue exploring different machine learning algorithms, the understanding gained from KNN is a foundational pillar in our data science journey.
Frequently Asked Questions
Q1. What is KNN classifier in Python?
A. The KNN classifier in Python is a machine learning model that assigns a class label to a data point based on the majority class of its k nearest neighbors.
Q2. How to build a KNN classifier?
A. To build a KNN classifier, one needs to choose the value of k, calculate the distances between the new data point and all existing data points, and then classify the new point based on the most common class among its k nearest neighbors.
Q3. What is KNN classifier good for?
A. KNN classifier is good for classification tasks where the decision boundary is non-linear or complex, and the data is not very large. It’s particularly useful for pattern recognition and anomaly detection.
Q4. Is KNN supervised or unsupervised?
A. KNN is a supervised learning algorithm, as it requires labeled training data to classify new data points based on their similarity to existing data points with known class labels.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.
Python Developer, ML Enthusiast, Blogger and an Electronics and Communication Engineering aspirant determined and motivated to finish tasks with atmost sincerity and dedication.I'am a good learner who ready to accept challenges to bring up my best even in the worst. Wish for a world with enough advancements and opportunities for the people.







Excellentttttttt! thank you a lot
Love it! I would love to have as well how to interpret the accuracy and confusion matrix here too!