This article was published as a part of the Data Science Blogathon.
Introduction

Web Scraping is a method or art to get or scrap data from the internet or websites and storing it locally on your system. Web Scripting is a programmed strategy to acquire a lot of information from sites.
The vast majority of this information is unstructured information in an HTML design which is then changed over into organized information in an accounting page or a data set so it tends to be utilized in different applications. There is a wide range of approaches to perform web scraping to get information from sites. These incorporate utilizing on the web administrations, specific API’s or in any event, making your code for web scraping without any preparation.
Numerous enormous sites like Google, Twitter, Facebook, StackOverflow, and so on have API’s that permit you to get to their information in an organized organization. This is the most ideal choice yet different locales don’t permit clients to get to a lot of information in an organized structure or they are essentially not so mechanically progressed. Around there, it’s ideal to utilize Web Scraping to scratch the site for information.

Web Scrapers can extract all the information on specific destinations or the particular information that a client needs. Preferably, it’s ideal if you indicate the information you need so the web scraper just concentrates that information rapidly. For instance, You should scratch an Amazon page for the sorts of juicers accessible, however, you may just need the information about the models of various juicers and not the client audits.
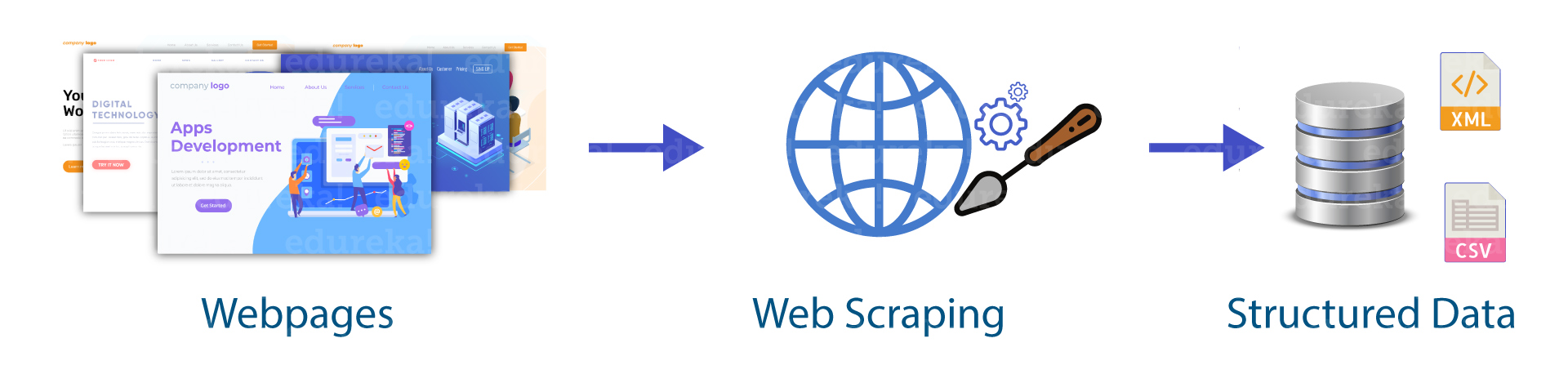
So when a web scrubber necessities to scratch a website, first it is given the URLs of the necessary locales. At that point, it stacks all the HTML code for those destinations and a further developed scraper may even concentrate all the CSS and Javascript components also. At that point, the scraper acquires the necessary information from this HTML code and yields this information in the organization indicated by the client.
Generally, this is as an Excel bookkeeping page or a CSV record however the information can likewise be saved in different organizations, for example, a JSON document.

Popular Python Libraries for Web Scraping
- Requests
- Beautiful Soup 4
- lxml
- Selenium
- Scrapy
AutoScraper
It is a python web scraping library to make web scraping smart, automatic fast, and easy. It is lightweight as well it means it will not impact your PC much. A user can easily use this tool for data scraping because of its easy-to-use interface. To get started, you just need to type few lines of codes and you’ll see the magic.
You just have to provide the URL or HTML content of the web page from where you want to scrap the data furthermore, a rundown of test information that we need to scratch from that page. This information can be text, URL, or any HTML label worth of that page. It learns the scraping rules on its own and returns similar elements.
In this article, we will investigate Autoscraper and perceive how we can utilize it to scratch information from the we.

Installation
There are 3 ways to install this library in your system.
- Install from the git repository using pip:
pip install git+https://github.com/alirezamika/autoscraper.git
- Install using PyPI:
pip install autoscraper
- Install from source:
python setup.py install
Importing Library
We will just import an auto scraper as it is adequate for web scratching alone. Below is the code for importing:
from autoscraper import AutoScraper
Defining Web Scraping Function
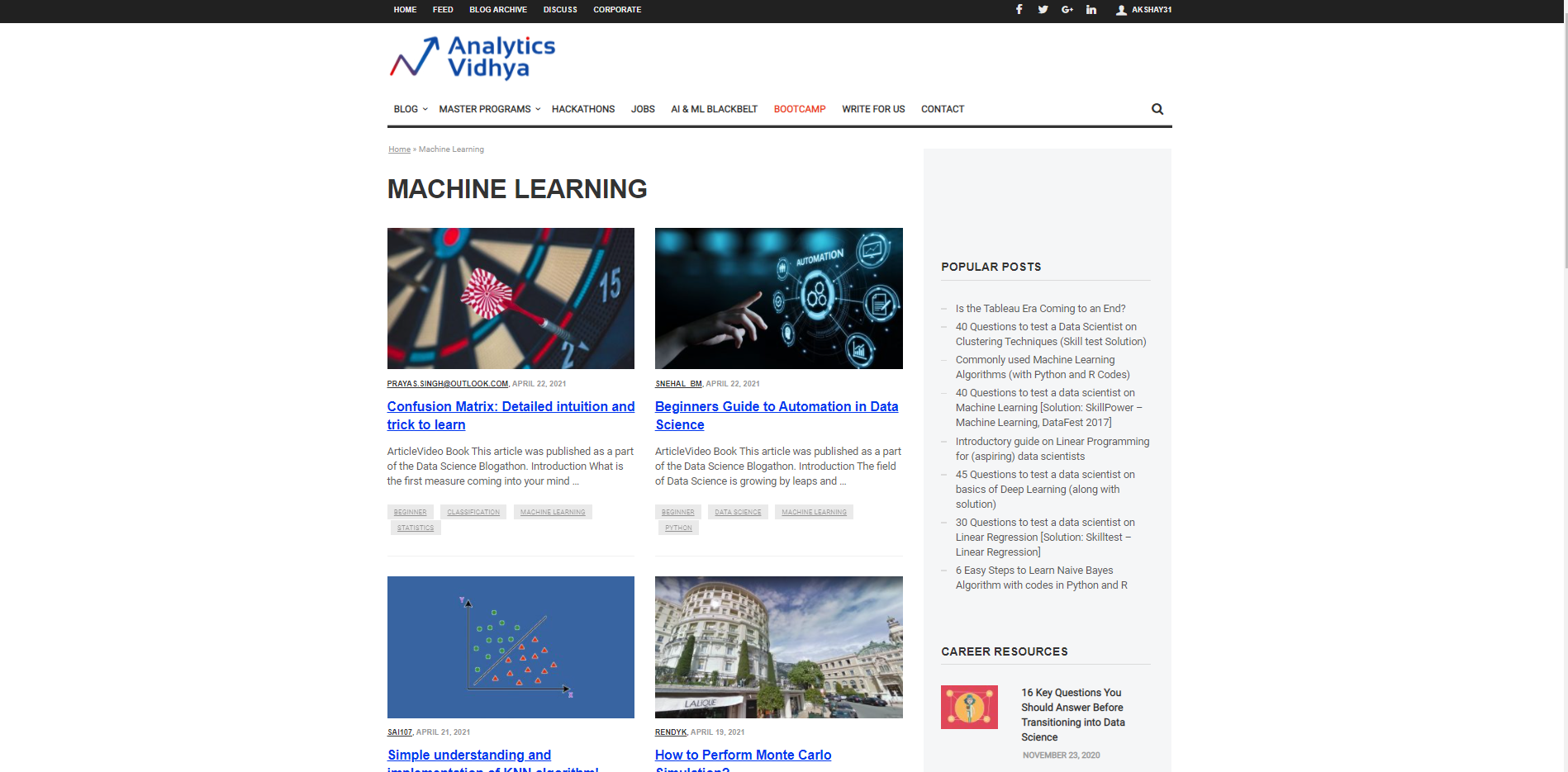
Allow us to begin by characterizing a URL from which will be utilized to bring the information and the necessary information test which is to be brought. Suppose we want to fetch the titles for different articles on Machine Learning on the Analytics Vidhya website. So, we have to pass the URL of the Analytics Vidhya machine learning blog section and the secondly wanted list. The wanted list is a list that is sample data that we want to scrape from that page. For example, here wanted list is a title of any blog on Analytics Vidhya machine learning blog section.
url = 'https://www.analyticsvidhya.com/blog/category/machine-learning/' wanted_list = ['Confusion Matrix: Detailed intuition and trick to learn']
We can add one or multiple candidates to the wanted list. You can also put URLs to the wanted list to retrieve the URLs.
Initiate the AutoScraper
The next step after initiating the URL and wanted list is to call the AutoScraper function. We aim to use this function to build the scraper model and perform web scraping on that particular page itself.
This can be initiate by using the below code:
scraper = AutoScraper()
Building the Object
This is the final step in web scraping using this particular library. Here er create the object and show the result of web scraping.
Python Code:
from autoscraper import AutoScraper
url = 'https://stackoverflow.com/questions/2081586/web-scraping-with-python'
wanted_list = ["What are metaclasses in Python?"]
scraper = AutoScraper()
result = scraper.build(url, wanted_list)
print(result)Here in the above image, you can see it returns the title of the blogs on the Analytics Vidhya website under the machine learning section, similarly, we can get the URLs of the blogs by just passing the sample URL in the wanted list we defined above.
Saving the Model
It allows us to save the model that we have to build so that we can reload it whenever required.
To save the model, use below code
scraper.save('blogs') #Give it a file path
To load the model, use the below code:
scraper.load('blogs')
Note: Other than every one of these functionalities auto scraper additionally permits you to characterize proxy IP Addresses with the goal that you can utilize it to get information. We simply need to characterize the proxies and pass it as an argument to the build function as shown below:
proxies = {
"http": 'http://127.0.0.1:8001',
"https": 'https://127.0.0.1:8001',
}
result = scraper.build(url, wanted_list, request_args=dict(proxies=proxies))
For more information, check the below link: AutoScraper
Conclusion
In this article, we perceived how we can utilize Autoscraper for web scraping by making a basic and simple to utilize the model. We saw various formats in which information can be recovered utilizing Autoscraper. We can likewise save and load the model for utilizing it later which saves time and exertion. Autoscraper is amazing, simple to utilize, and efficient.
Thanks for reading this article and for your patience. Do let me in the comment section about feedback. Share this article, it will give me the motivation to write more blogs for the data science community.
Email id: gakshay1210@gmail.com
Follow me on LinkedIn: LinkedIn
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.







Thank you. Very useful information.