This article was published as a part of the Data Science Blogathon.
Overview
- This article focuses on exploring Machine Learning using Pyspark
- We would be using google colab for building Machine learning pipelines by integrating Pyspark in google colab.
- Our focus remains to choose the best model using cross-validation and hyperparameter tuning followed by making predictions on Pyspark.
Introduction
With the exponential increase of Big Data, there’s a demand for distributed and parallel processing to perform near real-time large-scale complex operations. This is where Apache spark plays its role!!
Nowadays industries require distributed and parallel processing frameworks for BigData analytics, gone are the days of using traditional tools for machine learning. Apache spark is one such tool that is far better and one of the most advanced tools available today.
Apache Spark is a unified in-memory computing platform with a ton of libraries supporting parallel processing on distributed nodes. The improved computational speed provides immediate analysis of Big Data which leads to better decision making, quicker operations, and hence greater profits. These astounding features make Apache spark every data scientist’s go-to platform and have become a staple for Big Data Analytics in Industries.
What is PySpark?
Apache Spark offers APIs in multiple languages like Scala, Python, Java, and SQL. PySpark is the spark API that provides support for the Python programming interface.
We would be going through the step-by-step process of creating a Random Forest pipeline by using the PySpark machine learning library Mllib.
Learning Objectives
- PySpark set up in google colab
- Starting with google colab
- Installation of Apache spark along with the required dependencies
- Data loading and cleaning
- Load the dataset from the local file system to goggle colab
- Learn to describe and clean the data set
-
Remove columns with a high number of missing values.
-
Remove rows with missing values.
- Creating a Random Forest pipeline to predict prices
-
Build a random forest pipeline to predict car prices
-
Save the pipeline to disk
-
- Hyperparameter tuning for selecting the best model
-
Load the pipeline
-
Create a cross validator for hyperparameter tuning
-
- Training the model and predicting prices
- Pass the data through the pipeline
- Train the model
- Predict car prices of the test set
- Evaluating performance by using several metrics.
- Finding the MSE, RMSE, MAE, and R squared metrics
- Evaluating the model
PySpark set up in google colab
The prerequisite for setting up PySpark in google colab is to download Java as Spark requires JVM to run. We need to install the latest version of OpenJDK by the following command.
!apt-get install openjdk-11-jdk-headless -qq > /dev/null
Now we can download the latest spark version from the official spark website. Here we would be installing spark- 3.1.1. followed by unpacking the repositories
!wget -q https://downloads.apache.org/spark/spark-3.1.1/spark-3.1.1-bin-hadoop2.7.tgz !tar -xvf spark-3.1.1-bin-hadoop2.7.tgz
Import the findspark library which will assist in locating and importing Spark on the system. Findspark adds PySpark to the system path at run time as it is not present by default.
!pip install -q findspark
Specify two environment variables for Java_Home and Spark_Home.
import os os.environ[“JAVA_HOME”] = “/usr/lib/jvm/java-11-openjdk-amd64” os.environ[“SPARK_HOME”] = “/content/spark-3.1.1-bin-hadoop2.7”
Initiate findspark and loads the necessary libraries.
import findspark findspark.init() from google.colab import files from pyspark.sql import SparkSession from pyspark.ml.feature import VectorAssembler from pyspark.sql.functions import isnan, when, count, col, lit from pyspark.ml.regression import RandomForestRegressor from pyspark.ml.evaluation import RegressionEvaluator from pyspark.ml import Pipeline from pyspark.ml.tuning import CrossValidator from pyspark.ml.evaluation import RegressionEvaluator from pyspark.ml.tuning import ParamGridBuilder
Now we’re all set to start a Spark session
sc = SparkSession.builder.master(“local[*]”).getOrCreate()
Data Loading
We can load data to google colab by various methods, here we would be uploading our data files directly from the local system.
Exploring the dataset
The first and foremost step is to understand the data at hand. We are using the Cars dataset for this project.
We should try and understand the variables in-depth for creating an optimum model, this information helps to elevate our analysis. We notice that there are 16 columns and 11,914 records in the dataset.
Loading the dataset
We can start upload data files from the local system to the google colab virtual machine by using files.upload() function and then choose the respective CSV file. We can verify the files by using the ls command.
files.upload() !ls
With spark, we can load files of diverse formats and stores them as a spark dataframe. sc is the Spark connection variable and it will infer the scheme of the table automatically. Inspect the scheme details by printSchema() function.
data= sc.read.csv(“data.csv”, inferSchema=True, header=True) data.printSchema()
Data cleaning
We can describe the dataset to get the basic statistics of each column. Like the mean engine, horsepower is 249 while the standard deviation in highway mpg is 8.86.
data.describe().toPandas().transpose()
The main aspects of data cleaning require counting the total number of null values and removing columns with a high count of null values. The rows with high null values should also be removed.
Certain missing values are entered as strings as “N/A”. These “N/A” strings are not recognized as missing values by Spark. So we need to replace “N/A” strings with None values. The below code replaces “None” If the column value matches the unrequired string. This will be termed by Spark as missing values. It can be concluded that the column Market Category contains 30% of the total values as null values. Now we can drop it and delete all row-wise null values.
def replace(column, value):
return when(column != value, column).otherwise(lit(None))
data = data.withColumn(“Market Category”, replace(col(“Market Category”), “N/A”))
data.select([count(when(isnan(c) | col(c).isNull(), c)).alias(c) for c in data.columns]).show()
data = data.drop(“Market Category”)
data = data.na.drop()
print((data.count(), len(data.columns)))
Creating a Random Forest pipeline
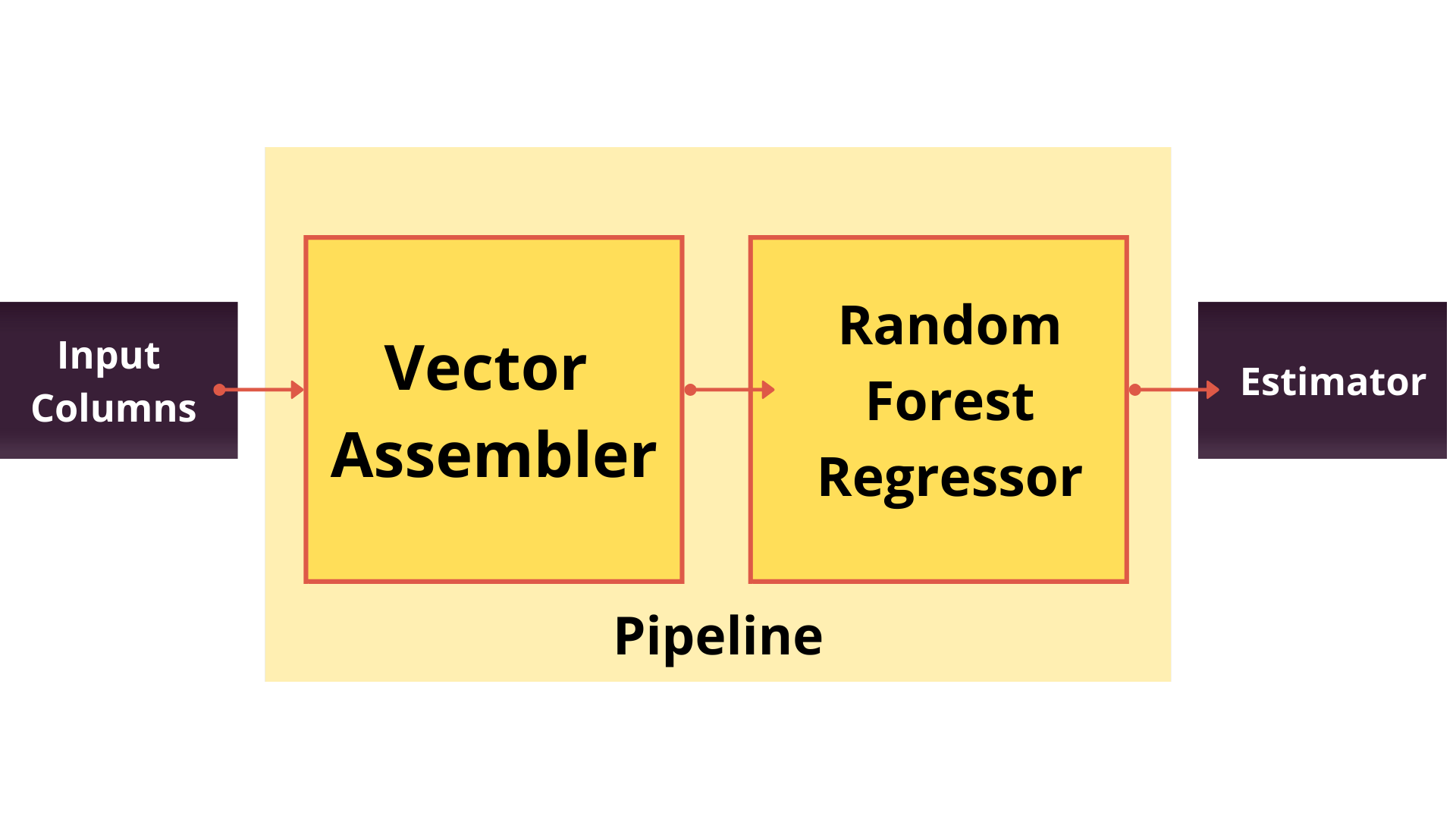
A machine learning pipeline integrates multiple sequential execution steps. It is used to streamline the machine learning process and automate the workflow. It prevents us from the task of executing each step individually. This pipeline can be saved and shared. We can load this pipeline again whenever required.
VectorAssembler() function allows us to create a vector of features, by taking two parameters into consideration- Input columns and output column. The input columns form a single vector which would be stored in the output column.
assembler = VectorAssembler(inputCols=[“Year”,
‘Engine HP’,
’Engine Cylinders’,
’Number of Doors’,
’highway MPG’,
’city mpg’,
’Popularity’], outputCol = “Attributes”)
Create a RandomForestRegressor with a feature column as “Attributes” and the label column as “MSRP”.
regressor = RandomForestRegressor(featuresCol = “Attributes”, labelCol=”MSRP”) pipeline = Pipeline(stages=[assembler, regressor])
Finally, we can save this pipeline on our Google Colab machine.
pipeline.write().overwrite().save(“pipeline”)
Creating a cross validator for hyperparameter tuning
Hyperparameter tuning is an essential step for creating an optimized machine learning model as it chooses the best parameters needed for the model.
Cross-validation is a resampling procedure that is used to evaluate machine learning models. It ensures an unbiased model.
Let’s begin by loading the previously created pipeline and create a grid map of parameters that we wish to explore for the random forest model. We can specify the parameter numTrees and give it a list of two values: 100 and 500.
pipelineModel = Pipeline.load(“pipeline”) paramGrid = ParamGridBuilder().addGrid(regressor.numTrees, [100, 500]).build()
Moving on to creating a cross-validator object. Usually, the cross-validator splits the training data into 10 folds and uses nine parts for training and the remaining one part for testing. Based on that, the models are evaluated.
Then the process is continued by taking into account a different set of nine parts. It then loops over the hyperparameter and helps us to select the best parameters for the model.
Here we can specify the number of folds as three. As we are using a regression evaluator, the evaluator metric is RMSE by default.
crossval = CrossValidator(estimator=pipelineModel,
estimatorParamMaps = paramGrid,
evaluator= RegressionEvaluator(labelCol = “MSRP”),
numFolds=3)
Training and prediction
Our first requirement is to split the data set into 80 % training and 20 % test set.
train_data, test_data = data.randomSplit([0.8,0.2], seed=123)
Here, we come across one of the most important steps of —
- Passing training set to the vector assembler
- Passing its result to the Random Forest regressor.
The training set is split into three parts due to the number of folds specified, and two distinct values for the number of trees in the Random Forest model are used. Finally, two models are created and evaluated based on RMSE. They are stored in the object cvModel.
cvModel= crossval.fit(train_data)
Try and extract the best model for prediction. For further clarity, we can view all the stages of the pipeline that the data went through.
bestModel= cvModel.bestModel
for x in range(len(bestModel.stages)):
print(bestModel.stages[x])
Lastly, predict the prices of the cars in the test set. Before that transform or predict the test set by using the cvModel object as it will automatically pick the best model.
pred = cvModel.transform(test_data) pred.select(“MSRP”, “prediction”).show()
Evaluating model’s performance
We will use various metrics such as-
- Mean Squared Error (MSE)
- Root Mean Squared Error (RMSE)
- Mean Absolute Error (MAE)
- R squared (R2)
These metrics indicate the performance of the model. According to these metrics, we can choose to rebuild the model according to our requirements.
As we are aware that the regression evaluator’s default metric is RMSE so we can directly get the RMSE value of the predictions using the evaluate function, We can also evaluate using other metrics by changing the default metric bypassing the new metric to the evaluate function and interpret the output accordingly
eval = RegressionEvaluator(labelCol = “MSRP”)
rmse = eval.evaluate(pred)
mse= eval.evaluate(pred, {eval.metricName: “mse”})
mae= eval.evaluate(pred, {eval.metricName: “mae”})
r2 = eval.evaluate(pred, {eval.metricName: “r2”})
Inspect the metrics for model evaluation. The mean absolute error shows the average error, whether positive or negative. The R squared metric represents the variance in the training data captured by the model.
print(“RMSE: %.3f” %rmse) print(“MSE: %.3f” %mse) print(“MAE: %.3f” %mae) print(“r2: %.3f” %r2)
End Notes
This marks the end of our hands-on guide on creating Machine learning pipelines by PySpark MLlib with google colab!! This article presents a brief introduction to scalable analysis by building ML pipelines via PySpark MLib. PySpark is an amazing tool with enormous capabilities and a life savior for data scientists. I highly recommend being familiar with Python and Pandas as it provides an upper hand for learning Spark!
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.



