This article was published as a part of the Data Science Blogathon.
Introduction
In this article, we will learn about machine learning using Spark. Our previous articles discussed Spark databases, installation, and working of Spark in Python. If you haven’t read it yet, here is the link.
In this article, we will mainly talk about implementing the machine learning model using Pyspark. We will also build a regressor model and bind it with cross-validation and parameter tuning.

As we already know that Spark is an in-memory data processing tool that can handle petabytes of data in a distributed manner. Implementing a machine learning model on such a big amount of data is possible using the Spark Ml-lib package that works in a distributed manner.
The conventional way of implementing a machine learning model was with the help of Apache Mahout, which was eventually slow and not flexible.
Spark Machine learning pipeline binds with real-time data as well as streaming data and it uses in-memory computation to fasten the process.
The best part of Spark is that it offers various built-in packages for machine learning, making it more versatile.
These Inbuilt machine learning packages are known as ML-lib in Apache Spark.
Features of MLlib
Spark offers a completely different package for handling all machine learning-related tasks. Other third parties libraries also can be coupled in Spark.
These are some important features of Spark:
- MLlib is a very similar API to the
scikitlearn API. We don’t need to learn it separately. - MLlib offers various types of Machine learning rebuild models.
- Spark’s MLlib supports computer vision as well as Natural Language Processing.
- It can be implemented on Realtime Data as well as distributed data systems.
Implementation Steps of Machine Learning
Implementation of the Machine Learning pipeline in Spark requires several stages. Spark Supports data in the form of feature vectors only.
For Illustration, we will build a Regressor model in Python Using Spark.
- Spark Installation
- Data Loading
- Data Cleaning
- Features Vectors
- Model training and testing
- Model evaluation
Installation
Spark can be easily installed using pip package manage python. Setting up spark on cloud-based notebooks is recommended as Installing Spark on a Local Computer might take some time.
!pip install pyspark !pip install findspark #-------------- import findspark findspark.init()
Required Libraries
These basic libraries need to be imported to start the Spark Cluster.
import pandas as pd import matplotlib.pyplot as plt from pyspark import SparkContext, SparkConf from pyspark.sql import SparkSession
Spark Context and Session
After successful installation, we need to create a spark context and session. Making Spark context can be understood as creating a cluster for a specific project. It is an entry point to our Spark Cluster, and it saves the configuration of our Spark clusters, like the number of cores that need to be used and the location of the data stream, etc.
from pyspark import SparkConf, SparkContext
# Creating a spark context class
scou = SparkSession.builder.master("local[*]").getOrCreate()
local[*]→ It defines the number of available CPU cores to be used.getOrCreate→ It creates a new session if the defined session is already not created.
Loading the Data
In this article, we will use the US car price dataset publicly available on Kaggle. If you make a cloud notebook, you don’t need to download the dataset.
data = sc.read.csv('../input/cars/data_car.csv', inferSchema = True, header = True)
data.show(5)
inferSchema = True : It preserves the schema of the dataset.
read.csv It reads the CSV files into the spark.
Loaded CSV file
data.printSchema()
Schema
printSchema() Prints the Schema with structured columns and rows.
Statistical Analysis in Spark
Spark provides some basic methods to see basic statistics for our loaded data.
data.describe().toPandas().transpose()
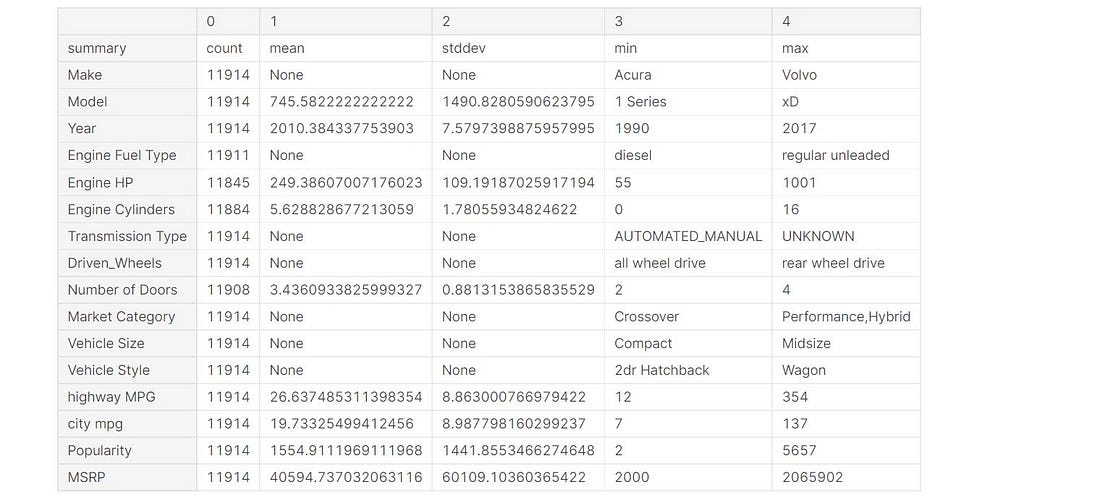
Statistics
Data Cleaning
Data Cleaning is the most important step for machine learning lifecycles. We remove unwanted rows and unwanted columns.
At this Step, we drop all the useless, resentment information from our dataset. Removing redundant data improves the overall model performance and accuracy.
In our case, the dataset has some NA values. And we aim to drop the nan values.
def replace(column, value):
return when(column!=value,column).otherwise(lit(None))
We made a function to replace a column value and replace with the None.
data = data.withColumn("Market Categories ", replace(col("Market Category"),"N/A"))
Count all the null values
Before removing anything, let’s look at how many redundant values are available for different columns.
from pyspark.sql.functions import when,lit,count,isnan,col data.select([count(when(isnan(c)|col(c).isNull(),c)).alias(c) for c in data.columns]).show()

Null values
As we noticed, the Market Category column has a maximum of 3742 null values, meaning this field is redundant and can be removed safely.
Drop the NaN values
#deleting the column Market Category
data = data.drop("Market Category")
# deleting the all null values
data = data.na.drop()
So far, we have cleaned our data, which is ready to pass for model training. But before, we need to convert all the data into the spark feature vector.
print((data.count(), len(data.columns)))

Feature Vectors in Spark
Spark supports only Feature Vectors data format for working on Machine learning tasks. Feature Vectors help spark inference faster.
Before proceeding, we need to convert our regular dataframe into a feature vector for fast and better inference.
Spark offers a class Vector Assembler that is used to convert our dataframe into feature vector series.
We must pass these columns as input features for our feature vector and model training.
The vector assembler will assemble all these columns’ data into a single series of Vectors that will be passed to our model for the training in Spark.
from pyspark.ml.feature import VectorAssembler
assembler = VectorAssembler(inputCols = ["Engine Cylinders",
"Year","highway MPG","Number of Doors","Engine HP","city mpg","Popularity"],
outputCol = "Input Attributes Name")
outputCol: Defines the name of the generated feature vector.
We will call our Vector Assembler in our machine learning pipeline. The real data will not be used at once. The pipeline takes data from one end and generates the data to the other end by performing all the preprocessing specified inside.
Assembling Model and Pipeline
Spark offers different inbuilt machine learning models. We need to import it and train it on our data simply.
- We will be using RandomForest Regressor for our regression model.
pyspark.ml.regressionContains all the regression models.pyspark.ml.classificationContains all the classification models.
from pyspark.ml.regression import RandomForestRegressor regressor_model = RandomForestRegressor(featuresCols = 'Input_name_of_attributes', labelCols = "MSRP")
RandomForestRegressor : It takes the featuresCol input feature vector, the combination of all the features, and labelCol the output feature vector(target feature).
Pipeline
A pipeline is a combination of multiple steps, and it works sequentially. Data goes from one end and, after performing all the sequential operations, comes to the other end.
We must create a sequence of all the transformations required in our pipeline.
After building our pipeline object, we can save our Pipeline on disk and load it anytime as required.
from pyspark.ml import Pipeline pipeline = Pipeline(stages = [assembler,regressor])
#--Saving the Pipeline
pipeline.write().overwrite().save("pipeline_saved_model")
stages: It is a sequence of transformations that must be performed on our data.
Loading the Pipeline
We can load the saved pipeline by using the method Pipeline.loadand specifying the path.
pipelineModel = Pipeline.load('./pipeline_save_model')
The Cross-validation and Model Tuning
The class pyspark.ml.tuningin spark provides all the functions that can be used in model tuning.
Before performing hyperparameter tuning, we need to define a param grid that will be used for hyperparameter tuning and cross-validation.
from pyspark.ml.tuning import ParamGridBuilder paramGrid = ParamGridBuilder() .addGrid(regressor.numTrees,[100,1500]) .build()
Cross Validation
CrossValidator in Spark works similarly to sci-kit learn’s cross-validator. It expects the model pipeline and parameter grid.
here we are choosing numFolds = 3 which means 66% of the data will be used for training, and the rest 33% of the data will be used for testing purposes.
from pyspark.ml.tuning import CrossValidator
crossval = CrossValidator(estimator = pipelineModel,
estimatorParamMaps = paramGrid,
evaluator = RegressionEvaluator(labelCol = "MSRP"),
numFolds = 3)
As of now, we have made a cross-validator with a training pipeline. The next step is to train our pipeline.
Splitting the data
For training and testing, we will split our data into training data (80%) and testing data (20%) using randomSplit() which will be used by our cross-validator to find the best-fit parameters.
train_data,test_data = data.randomSplit([0.75,0.25], seed = 1335)
Model Training
Model training step is a time-consuming process, it depends on the number of cores and CPU which spark is using.
fit This method is used for fitting the model with our data.
cvModel = crossval.fit(train_data)

Cross validated scores
Selection of Fine-Tuned Model
After running the cross validator, cross-validation saves the best fit model and its score.
bestModel : This method returns the best-fitted model
bestModel = cvModel.bestModel print(bestModel.stages)

We have got the best fit model having numFeatures = 7 and numTree = 500 .
Prediction Phase
In Spark, the methodtransform() is used for the prediction after passing the test data. Test data also must be a feature vector.
prediction = cvModel.transform(test_data)
The transform method automatically adds a series of predicted values to our test data.
Predicted values
Evaluation Metrics
The class pyspark.ml.evaluation provides all the evaluation methods. It provides separate regressor and classifier metrics.
from pyspark.ml.evaluation import RegressionEvaluator
rmse_score = eval.evaluate(pred, {eval.metricName:'rmse'})
eval_score = RegressionEvaluator(labelCol = 'MSRP')
mae_score = eval.evaluate(pred, {eval.metricName:"mae"})
r2_score =eval.evaluate(pred,{eval.metricName:'r2'})
Let’s print our scores
print("RMSE_score: %.3f" %rmse)
print("R2_score: %.3f" %r2)
print("MAE_score: %.3f" %mae)

R2: Higher is better. It tells the proportion of variance that has converged by our model.
RMSE: It is a Squared mean error between real and predicted values.
Conclusion
In this article, we discussed the Spark MLlib package and learned the steps involved in building an ML pipeline in Spark. We learned data cleaning, data transformation, and pipeline in detail.
- We built a Regression model inbuilt MLlib package.
- We discussed Cross validator and Model tuning in detail using the model.
- Spark provides different classes for model tuning and evaluation.
- Spark supports our data in the form of a feature vector only. Using Vector Assembler, we can transform it into a feature vector.
ML-lib pipeline can be fitted with real-time streaming and static batched data.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
A data enthusiast exploring the leading technologies related to the data






