This article was published as a part of the Data Science Blogathon.
Don’t look for the needle in the haystack. Just buy the haystack!
I hope you all are well. Hurray!! finally today our theme is similar to our beautiful quote😅. I always look for new ideas to share my knowledge, because I heard that “Knowledge shared is knowledge squared😊”. Most of you already know something about Share Market. In this article, we will explore something new and interesting. So let’s dig deeper into our today’s theme.
This article is actually based on Natural Language Processing(NLP), here we will create a model which will actually analyze stock price using News Headline. There are various kinds of news articles and based on that the stock price fluctuates. We will analyze the news heading using sentiment analysis using NLP and then we will predict the stock will increase or decrease. It is all about stock sentiment analysis.
Dataset Description
Here I have used the Kaggle dataset. You can directly download it from here. This dataset is a combination of world news and stock price available on Kaggle. There are 25 columns of top news headlines for each day in the data frame, Date, and Label(dependent feature). Data range from 2008 to 2016 and the data frame 2000 to 2008 was scrapped from yahoo finance. Labels are based on the Dow Jones Industrial Average stock index.
- Class 1 – The stock price increased.
- Class 0 – The stock price stayed the same or decreased.
Let’s do it!
Let’s first import required libraries.
import pandas as pd from sklearn.feature_extraction.text import CountVectorizer from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import classification_report,confusion_matrix,accuracy_score
Let’s read the dataset.
df = pd.read_csv('F:Stock-Sentiment-Analysis-master/Stock News Dataset.csv', encoding = "ISO-8859-1")
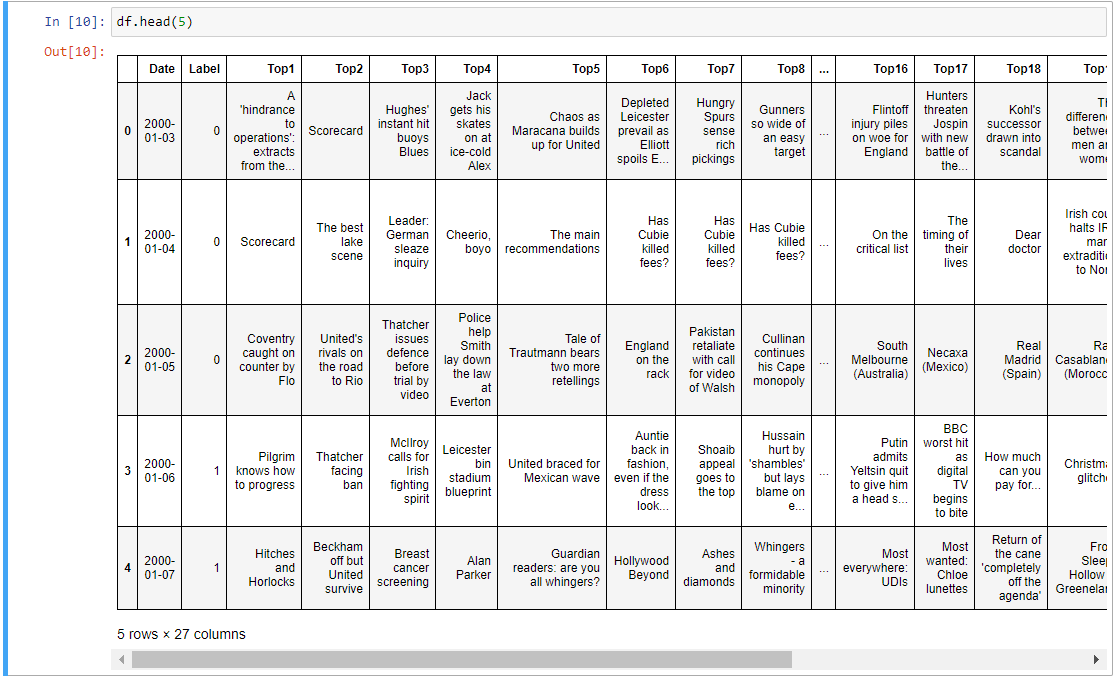
Let’s look at our dataset, here Label is our dependent feature(target value), and the remaining 26 features are independent. Whenever our label is 1, our stock price gets increased when we get these 25 news headlines. This is a kind of dataset we have, and we are going to use NLP in this problem statement and apply sentiment analysis and then we will predicting whether the stock price will increase or decrease.
Let’s divide our dataset into the training and testing parts.
train = df[df['Date'] < '20150101'] test = df[df['Date'] > '20141231']
we are dividing our dataset based on date. The dataset having Date < 20150101, I am taking that as training dataset and the dataset having Date > 20141231, I am taking it as testing dataset.
Let’s do some feature engineering on our dataset.
Now let’s remove all these columns, full stops, or exclamation marks from the text dataset because these all are not required for doing sentiment analysis. I have taken all the 25 news columns then I have just applied regular expressions, where I said that apart from a-z and A-Z replace everything with blank. If any special character will come it will automatically remove them and replace them with blank space.
# Removing special characters
data=train.iloc[:,2:27]
data.replace("[^a-zA-Z]"," ",regex=True, inplace=True)
# Renaming column names for better understanding and ease of access
list1= [i for i in range(25)]
new_Index=[str(i) for i in list1]
data.columns= new_Index
data.head(5)
The updated dataset looks like this:
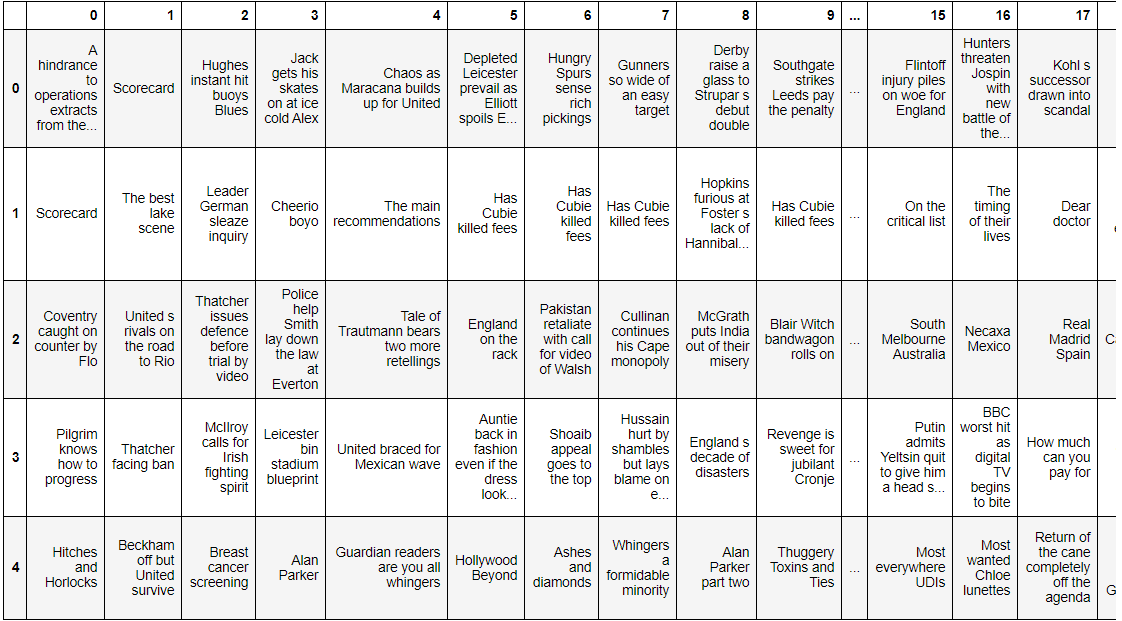
Let’s convert all these characters into smaller characters.
# Convertng headlines to lower case
for index in new_Index:
data[index] = data[index].str.lower()
data.head(1)
It is a very important step because whenever we are trying to create a count bag of words or a TFIDF model at that time always remember those models if that word starts from the capital letter and the same word present in another sentence with small letters then this model will consider two different words. It means the same word but due to only upper and lower case, it considered them as different words.
In order to solve these problems, we are performing this step. Therefore always make sure that you have converted all the characters into small characters you can also convert them into the upper case but remember if you have decided to convert all characters into the upper case then each and every character should be in an upper case similar to the lower case as well.
Let’s combine all news headlines based on the index :
Here if we considered all news headlines on a particular date as a one-paragraph that time only we can apply CountVectorizer which is the BagofWords model or TFIDF. So I will go on each and every index and I will combine them into one paragraph.
headlines = []
for row in range(0,len(data.index)):
headlines.append(' '.join(str(x) for x in data.iloc[row,0:25]))
Now our headline looks like this:

Let’s apply CountVectorizer and RandomForestClassifier
Here count vectorizer will basically convert these sentences into vectors. That is what bag of words means.
## implement BAG OF WORDS countvector=CountVectorizer(ngram_range=(2,2)) traindataset=countvector.fit_transform(headlines)
## implement RandomForest Classifier randomclassifier=RandomForestClassifier(n_estimators=200,criterion='entropy') randomclassifier.fit(traindataset,train['Label'])
Let’s predict for the testing dataset
Now for the testing dataset, we will do the same feature transformation that I did for the training dataset.
## Predict for the Test Dataset
test_transform= []
for row in range(0,len(test.index)):
test_transform.append(' '.join(str(x) for x in test.iloc[row,2:27]))
test_dataset = countvector.transform(test_transform)
predictions = randomclassifier.predict(test_dataset)
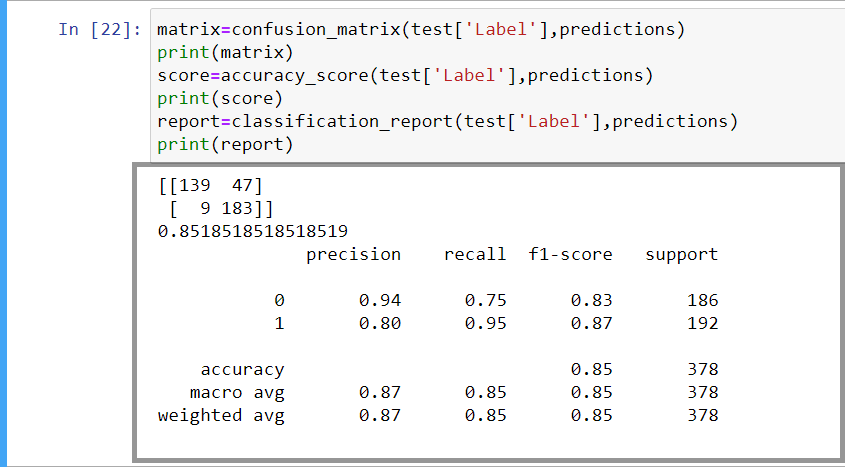
Finally, let’s check the accuracy
Here we are applying the classification report, confusion matrix, and accuracy score to check the accuracy of our model.
matrix = confusion_matrix(test['Label'],predictions) print(matrix) score = accuracy_score(test['Label'],predictions) print(score) report = classification_report(test['Label'],predictions) print(report)
Finally, we end up with all the steps. Now suppose you have to predict it for tomorrow, take the top 25 news headlines apply all the transformation methods, and finally give it to your model, your model will basically say whether your 0 or 1 means stock price will increase or not. This is how you can do stock sentiment analysis using news headlines.
EndNote
I hope you enjoyed this article. If you’ve got something on your mind you think this article is missing, don’t hesitate to leave a response below.
Who I am?
I am Ronil Patil😎, A lifelong learner. Passionate about Deep Learning, NLP, Machine Learning, and IoT. If you have any query, you can connect me on LinkedIn. And finally, … it doesn’t go without saying😊,
Thank you for reading!!
See ya!
ronyl
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.





Why didn't you use train test split or cross validation or Radom search cv to split dataset. please clarify this