This article was published as a part of the Data Science Blogathon

No matter how long-running a love-hate relationship you have with maths, understanding its core concepts is essential for designing Machine Learning Models and making strategic decisions. Mathematics for Machine Learning is a prerequisite for building a career in Data Science and AI, so embracing its concepts and implementing them in your future work is crucial.
Machine learning is all about mathematics, which successively helps in creating an ML algorithm that will learn from data provided to form an accurate prediction. The prediction might be as simple as classifying cats or dogs from a given set of images or what quite products to recommend to a customer supported past purchases. Having a proper understanding of the mathematics behind the ML algorithms will help you choose all the proper algorithms for your project in data science and machine learning.
As long as you’ll understand why maths is employed, you’ll find it more interesting. With this, you’ll understand why we pick one machine learning algorithm over the opposite and the way it affects the performance of the machine learning model.
We will try to cover the following points in this blog post:
- Vectors and Vector Spaces
- Linear Transformations and matrices
Vectors and Vector Spaces
The ability to visualize data is one of the most useful skills to possess as a data science professional, and a solid foundation in linear algebra enables one to do that. Some concepts and algorithms are quite easy to understand if one can visualize them as vectors and matrices, rather than looking at the data as lists and arrays of numbers.
Linear Algebra is the workhorse of Data Science and ML. While training a machine learning model using a library (such as in R or Python), much of what happens behind the scenes is a bunch of matrix operations. The most popular deep learning library today, Tensorflow, is essentially an optimized (i.e. fast and reliable) matrix manipulation library. So is scikit-learn, the Python library for machine learning.
Vectors
A vector is an object having both magnitudes as well as direction. Vectors are usually represented in two ways – as ordered lists, such as x = [x1, X2 . . . xn] or using the ‘hat’ notation, such as x = x1ˆi + x2ˆj + x3ˆk where ˆi, ˆj, ˆk represent the three perpendicular directions (or axes).
The number of elements in a vector is the dimensionality of the vector. For e.g. x = [ x1 , x2 ] is two dimensional (2-D) vector , x = [ x1 , x2 , x3 ] is a 3-D vector and so on.
The magnitude of a vector is the distance of its tip from the origin. For an n-dimensional vector x = [x1,x2 , . . . xn ] , the magnitude is given by,
A unit vector is one whose distance from the origin is exactly 1 unit. E.g the vectors are unit vectors.
Vector Operations
1. Vector Addition/Subtraction: It is the element-wise sum/difference of two vectors.
Mathematically,
2. Scalar Multiplication/Division: It is the element-wise multiplication/division of the scalar value.
Mathematically,
3. Vector Multiplication or Dot Product: It is the element-wise product of the two vectors. It is also known as the dot product of two vectors. The dot product of two vectors returns a scalar quantity. Mathematically,
Geometrically,
where is the angle between two vectors?
The dot product of two perpendicular vectors (also called orthogonal vectors) is 0. The dot product can be used to compute the angle between two vectors using the formula,
This simple property of the dot product is extensively used in data science applications.
Vector Spaces
- Basis Vector: A basis vector of a vector space V is defined as a subset (v 1, v2,. . . vn ) of vectors in vector space V, that are linearly independent and span vector space V. Consequently, if (v1, v2, . . . vn) is a list of vectors in vector space V, then these vectors form a vector basis if and only if every v in vector space V can be uniquely written as,
- Span: The span of two or more vectors is the set of all possible vectors that one can get by changing the scalars and adding them.
- Linear Combination: The linear combination of two vectors is the sum of the scaled vectors.
- Linearly Dependent: A set of vectors is called linearly dependent if any one or more of the vectors can be expressed as a linear combination of the other vectors.
- Linearly Independent: If none of the vectors in a set can be expressed as a linear combination of the other vectors, the vectors are called linearly independent.
LINEAR TRANSFORMATIONS AND MATRICES:
Matrices are a time-tested and powerful data structure used to perform numerical computations. Briefly, a matrix is a collection of values stored as rows and columns, i.e.
Matrices:
- Rows: Rows are horizontal. The matrix A has m rows. Each row itself is a vector, so they are also called row vectors.
- Columns: Columns are vertical. The matrix A has n columns. Each column itself is a vector, so they are also called column vectors.
- Entities: Entities are individual values in a matrix. For a given matrix A, value of row i and column j is represented as A ij
- Dimensions: The number of rows and columns. For m rows and n columns, the dimensions are (m × n).
- Square Matrices: These are matrices where the number of rows is equal to the number of columns, i.e m = n.
- Diagonal Matrices: These are square matrices where all the off-diagonal elements are zero,i.e,
- Identity Matrices: These are diagonal matrices where all the diagonal elements are 1, i.e,
Matrix Operations
- Matrix Addition/Subtraction: It is the element-wise sum/difference of two matrices. Mathematically,
- Matrix Multiplication/Division: It is the element-wise multiplication/division of the scalar value. Mathematically,
- Matrix Multiplication or Dot Product: It is the element-wise product of the two matrices i.e the (i, j) element of the output matrix is the dot product of the ith row of the first matrix and the jth column of the second matrix. Mathematically,
Not all matrices can be multiplied with each other. For the matrix multiplication AB to be valid, the number of columns in A should be equal to the number of rows in B. i.e for two matrices A and B with dimensions (m × n) and (o × p), AB exists if and only if m = p and BA exists if and only if o = n. Matrix multiplication is not commutative i.e
AB-BA.
- Matrix Inverse: The inverse of a matrix A is a matrix such that AA -1 = I ( Identity Matrix).
- Matrix Transpose: The transpose of a matrix produces a matrix in which the rows and columns are interchanged. Mathematically,
Linear Transformations:
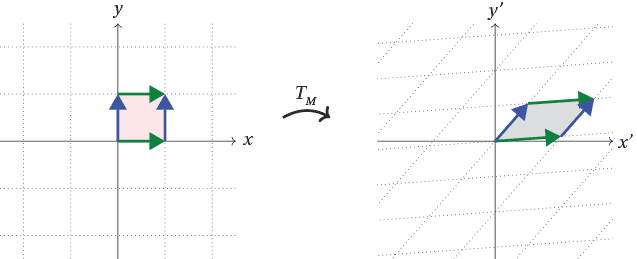
Any transformation can be geometrically visualized as the distortion of the n-dimensional space (it can be squishing, stretching, rotating, etc.). The distortion of space can be visualized as a distortion of the grid lines that make up the coordinate system. Space can be distorted in several different ways. A linear transformation, however, is a special distortion with two distinct properties,
- Straight lines remain straight and parallel to each other
- The origin remains fixed
Consider a linear transformation where the original basis vectors- move to the new points,
move to the new points, (where i and j are unit vectors along the x-direction and y-direction in the co-ordinate system respectively) This means that i moves to (1,− 2) from (1,0) and j moves to (3, 0) from (0, 1) in the linear transformation. This transformation simply stretches the space in the y-direction by three units while stretching the space in the x-direction by two units and rotating it by sixty degrees in the clockwise direction. One can combine the two vectors where i and j land and write them as a single matrix, i.e,
(where i and j are unit vectors along the x-direction and y-direction in the co-ordinate system respectively) This means that i moves to (1,− 2) from (1,0) and j moves to (3, 0) from (0, 1) in the linear transformation. This transformation simply stretches the space in the y-direction by three units while stretching the space in the x-direction by two units and rotating it by sixty degrees in the clockwise direction. One can combine the two vectors where i and j land and write them as a single matrix, i.e,
As can be seen, each of these vectors forms one column of the matrix (and hence are often called column vectors). This matrix fully represents the linear transformation. Now, if one wants to find where any given vector v would land after this transformation, one simply needs to multiply the vector v with the matrix L, i.e vnew = L.v. It is convenient to think of this matrix as a function that describes the transformation, i.e it takes the original vector v as the input and returns the new vector vnew. The following figures represent the linear transformation.
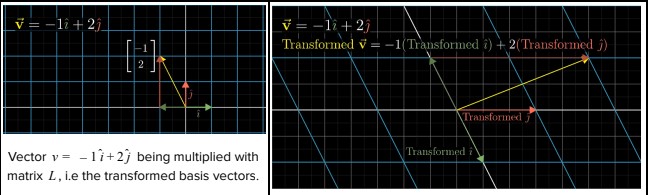
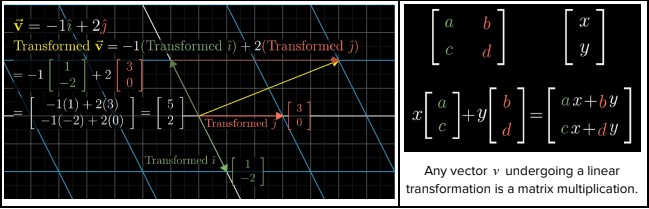
Formally, a transformation is linear if it satisfies the following two properties,
- Additivity or Distributivity, i.e L(v + w) = L(v) + L(w) .
- Associativity of Homogeneity, i.e L(cv) = cL(v) where c is a scalar.
End!!!!
I hope you enjoyed the article !!! Though there are plenty of valuable resources available on the internet which explain concepts like matrix decompositions, vector calculus, linear algebra, geometry, matrices, the mathematics behind the principal component analysis, and support vector machines, and many more. The following links may help you to understand the mathematical concepts :
-
Khan Academy’s courses – Comprehensive free course for complex mathematical concepts.
-
3Blue1Brown – Here you will understand each most of the mathematical concept in depth







{kind=link}
{kind=link}
This is great considering the changing technology and the need for Artificial Intelligence capabilities this is sure a good start where one can utilize his/her mathematical capabilities