This article was published as a part of the Data Science Blogathon
Introduction
Apache Spark is a framework used in cluster computing environments for analyzing big data. Apache Spark is able to work in a distributed environment across a group of computers in a cluster to more effectively process big sets of data. This Spark open-source engine supports a wide array of programming languages including Scala, Java, R, and Python.
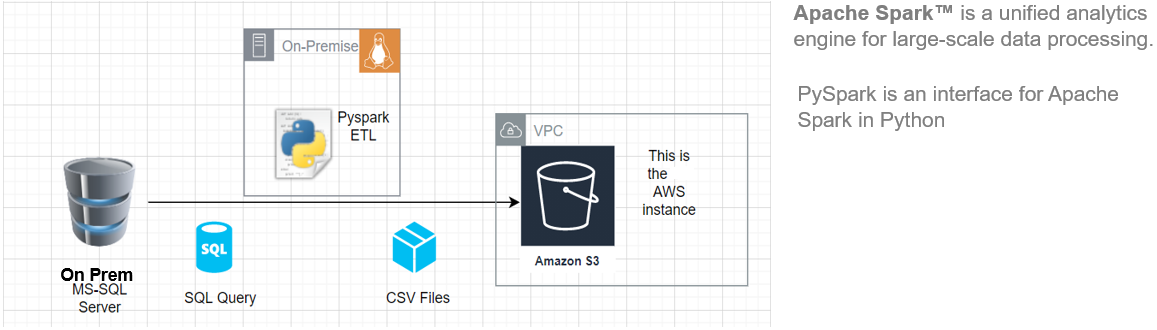
In this article, I’ll show you how to get started with installing Pyspark on your Ubuntu machine and then build a basic ETL pipeline to extract transfer-load data from a remote RDBMS system to an AWS S3 bucket.
This ETL architecture can be used to transfer 100s of Gigabytes of data from any RDBMS database server (in this article we have used MS SQL Server) to an Amazon S3 bucket.
Key advantages of using Apache Spark:
- Run workloads 100x faster than Hadoop
- Supported by Java, Scala, Python, R, and SQL
Source: This is an original image
Requirements
To get started we need to have the following pre-requisites:
- A system running Ubuntu 18.04 or Ubuntu 20.04
- A user account with sudo privileges
- An AWS account with upload access to S3 bucket
Before downloading and setting up Spark, you need to install the necessary package dependencies. Make sure the following packages are already set up in your system.
- Python
- JDK
- Git
To confirm the installed dependencies by running these commands:
java -version; git --version; python --version

Install PySpark
Download the version of Spark you want from Apache’s official website. We will download Spark 3.0.3 with Hadoop 2.7 as it is the current version. Next, use the wget command and the direct URL to download the Spark package.
Change your working directory to /opt/spark.
cd /opt/spark
sudo wget https://downloads.apache.org/spark/spark-3.0.3/spark-3.0.3-bin-hadoop2.7.tgz

Extract the saved package using tar command. Once the untar process completes, the output shows the files that have been unpacked from the archive.
tar xvf spark-*
ls -lrt spark-*

Configure Spark Environment
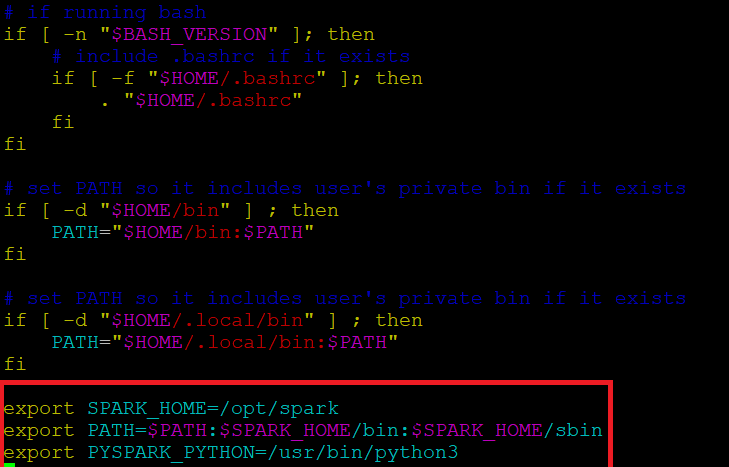
Before starting a spark server, we need to configure some environment variables. There are a few Spark directories we need to add to the default profile. Use the vi editor or any other editor to add these three lines to .profile:
vi ~/.profile
Insert these 3 lines at the end of the .profile file.
export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin export PYSPARK_PYTHON=/usr/bin/python3
Save changes and exit from the editor. When you finish editing the file, load the .profile file in the command line by typing. Alternatively, we can exit from the server and re-login for the changes to take effect.
source ~/.profile
Start/Stop Spark Master & Worker
Go to the Spark installation directory /opt/spark/spark*. It has all the scripts required to start/stop spark services.
Run this command to start spark master.
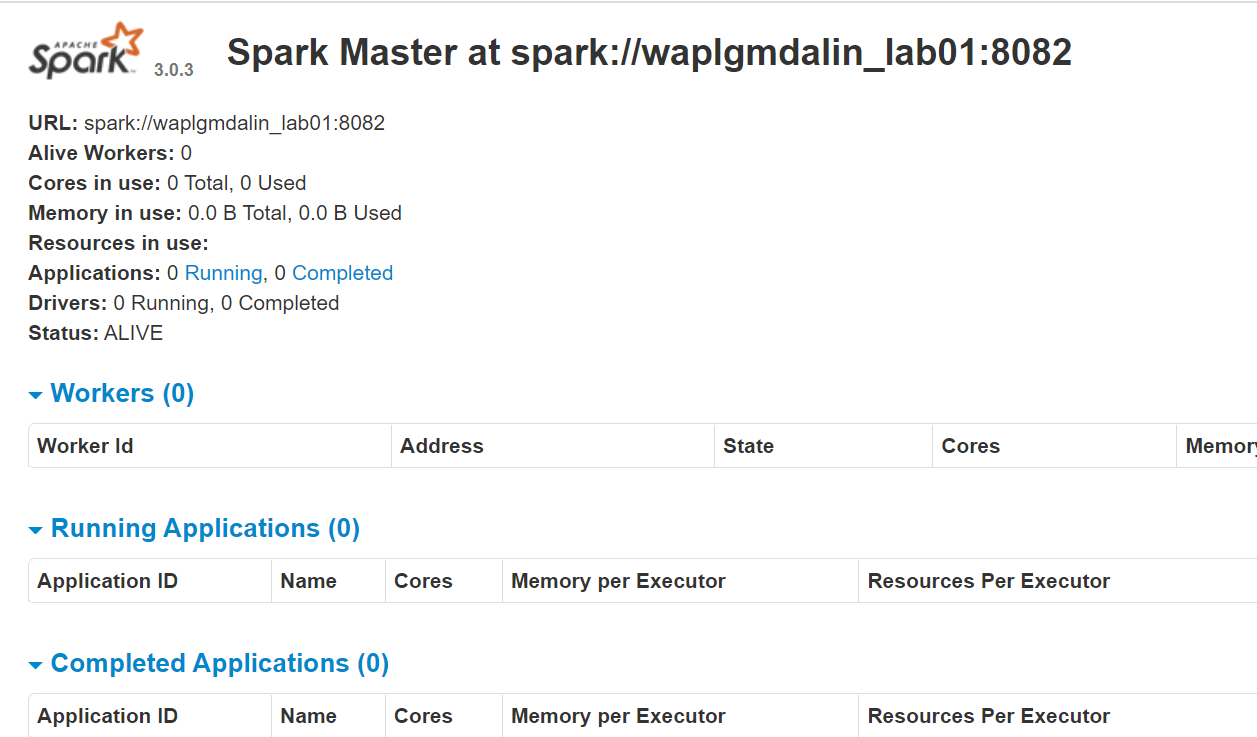
start-master.shTo view the Spark web interface, open a web browser and enter the localhost IP address on port 8080.(This is the default port that Spark uses if you need to change it, do it in the start-master.sh script). Alternatively, you can replace 127.0.0.1 with the actual network IP address of your host machine.
http://127.0.0.1:8080/The webpage shows your Spark master URL, worker nodes, CPU resource utilization, memory, running applications etc.
Now, run this command to start a Spark worker instance.
start-slave.sh spark://0.0.0.0:8082
or
start-slave.sh spark://waplgmdalin_lab01:8082
The worker webpage itself runs on http://127.0.0.1:8084/ but it should be linked to the master. That’s why we pass the Spark master URL as a parameter to the start-slave.sh script. To confirm if the worker is properly linked to master, open the link on a browser.
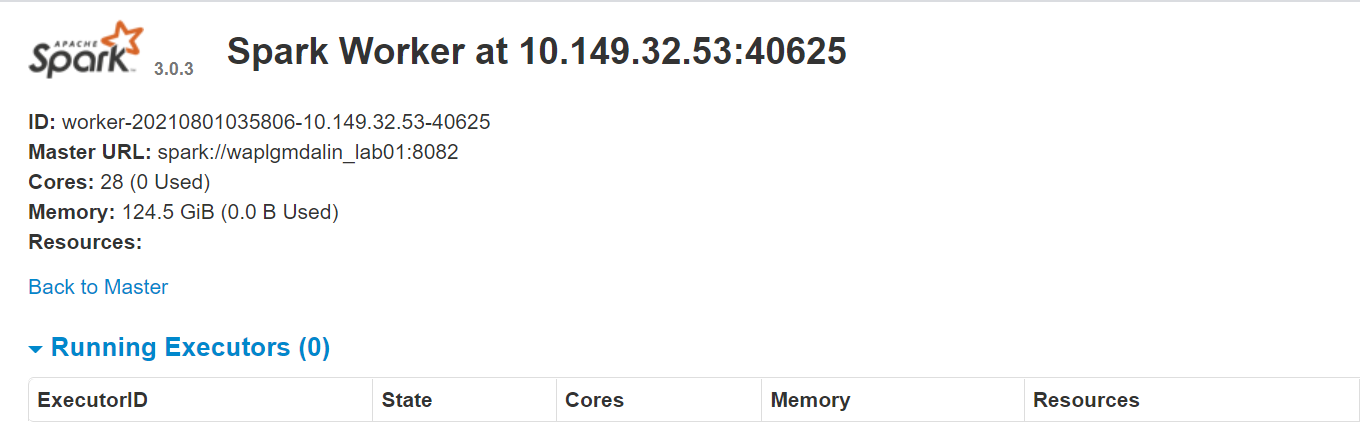
Resource Allocation to the Spark worker
By default, when you start a worker instance it uses all the cores available in the machine. However, for practical reasons, you may want to limit the number of cores and amount of RAM allocated to each worker.
start-slave.sh spark://0.0.0.0:8082 -c 4 -m 512M
Here, we have allocated 4 cores and 512 MB of RAM to the worker. Let’s confirm this by re-starting the worker instance.
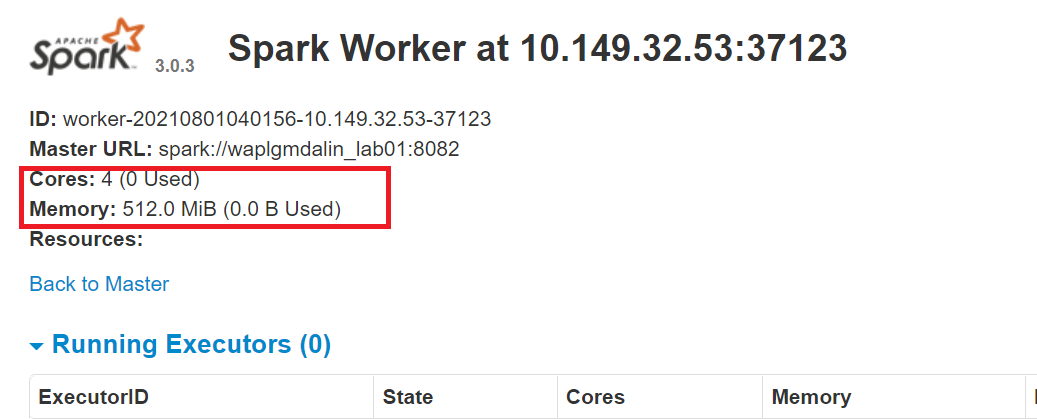
To stop the master instance started by executing the script above, run:
stop-master.shTo stop a running worker process, enter this command:
stop-slave.shSetup MS SQL Connection
In this PySpark ETL, we will connect to an MS SQL server instance as the source system and run SQL queries to fetch data. So, we have to download the necessary dependancies first.
Download the MS-SQL jar file(mssql-jdbc-9.2.1.jre8) from Microsoft website and copy it to “/opt/spark/jars” directory.
https://www.microsoft.com/en-us/download/details.aspx?id=11774
Download the Spark SQL jar file(spark-sql_2.12-3.0.3.jar) from the Apache download site and copy it to ‘/opt/spark/jars” directory.
https://jar-download.com/?search_box=org.apache.spark+spark.sql
Edit the .profile, add the PySpark & Py4J classes to the Python path:
export PYTHONPATH=$SPARK_HOME/python/:$PYTHONPATH export PYTHONPATH=$SPARK_HOME/python/lib/py4j-0.10.9-src.zip:$PYTHONPATH
Setup AWS S3 connection
To connect to an AWS instance, we need to download the three jar files and copy them to the “/opt/spark/jars” directory. Check the Hadoop version that you are using currently. You can get it from any jar present on your Spark installation. If the Hadoop version is 2.7.4 then, download the jar file for the same version. For Java SDK, you have to download the same version that was used to generate the Hadoop-aws package.
Make sure the versions are the latest ones.
- hadoop-aws-2.7.4.jar
- aws-java-sdk-1.7.4.jar
- jets3t-0.9.4.jar
sudo wget https://repo1.maven.org/maven2/com/amazonaws/aws-java-sdk/1.11.30/aws-java-sdk-1.7.4.jar sudo wget https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-aws/2.7.3/hadoop-aws-2.7.4.jar sudo wget https://repo1.maven.org/maven2/net/java/dev/jets3t/jets3t/0.9.4/jets3t-0.9.4.jar
Python Development
Create a working directory called ‘scripts’ to store all the Python scripts and configuration files. Create a file called “sqlfile.py” that will contain the SQL queries we want to run on the remote DB server.
vi sqlfile.py
Insert the following SQL query in the sqlfile.py file that will extract the data. Prior to this step, its advisable to test run this SQL query on the server to get an idea of the number of records returned.
query1 = """(select * from sales-data where date >= '2021-01-01' and status ='Completed')"""
Save and exit from the file.
Create a configuration file called “config.ini” that will store the login credentials and DB parameters.
vi config.ini
Insert the following AWS and MSSQL connection parameters in the file. Note, that we have created separate sections to store AWS and MSSQL connection parameters. You can create as many DB connection instances as required provided each one is kept under its own section (mssql1, mssql2, aws1 , aws2 etc).
[aws]
ACCESS_KEY=BBIYYTU6L4U47BGGG&^CF SECRET_KEY=Uy76BBJabczF7h6vv+BFssqTVLDVkKYN/f31puYHtG BUCKET_NAME=s3-bucket-name DIRECTORY=sales-data-directory [mssql] url = jdbc:sqlserver://PPOP24888S08YTA.APAC.PAD.COMPANY-DSN.COM:1433;databaseName=Transactions database = Transactions user = MSSQL-USER password = MSSQL-Password dbtable = sales-data filename = data_extract.csv
Save and exit from the file.
Create a Python Script called “Data-Extraction.py”.
Import Libraries for Spark & Boto3
Spark is implemented in Scala, a language that runs on the JVM, but since we are working with Python we will use PySpark. The current version of PySpark is 2.4.3 and works with Python 2.7, 3.3, and above. You can think of PySpark as a Python-based wrapper on top of the Scala API.
Here, AWS SDK for Python (Boto3) to create, configure and manage AWS services, such as Amazon EC2 and Amazon S3. The SDK provides an object-oriented API as well as low-level access to AWS services.
Import the Python libraries for initiating a Spark session, query1 from the sqlfile.py and boto3.
from pyspark.sql import SparkSession import shutil import os import glob import boto3 from sqlfile import query1 from configparser import ConfigParser
Create a SparkSession
SparkSession provides a single point of entry to interact with the underlying Spark engine and allows programming Spark with DataFrame and Dataset APIs. Most importantly, it restricts the number of concepts and constructs a developer has to work with while interacting with Spark. At this point, you can use the ‘spark’ variable as your instance object to access its public methods and instances for the duration of your Spark job. Give a name to the application.
appName = "PySpark ETL Example - via MS-SQL JDBC"
master = "local"
spark = SparkSession
.builder
.master(master)
.appName(appName)
.config("spark.driver.extraClassPath","/opt/spark/jars/mssql-jdbc-9.2.1.jre8.jar")
.getOrCreate()
Read the Configuration File
We have stored the parameters in a “config.ini” file to separate out the static parameters from the Python code. This helps in writing cleaner code without any hard coding. This module implements a basic configuration language that provides a structure similar to what we see in Microsoft Windows .ini files.
url = config.get('mssql-onprem', 'url')
user = config.get('mssql-onprem', 'user')
password = config.get('mssql-onprem', 'password')
dbtable = config.get('mssql-onprem', 'dbtable')
filename = config.get('mssql-onprem', 'filename')
ACCESS_KEY=config.get('aws', 'ACCESS_KEY')
SECRET_KEY=config.get('aws', 'SECRET_KEY')
BUCKET_NAME=config.get('aws', 'BUCKET_NAME')
DIRECTORY=config.get('aws', 'DIRECTORY')
Execute the Data Extraction
Spark includes a data source that can read data from other databases using JDBC. Run the SQL on the remote database by connecting using the connection parameters and the Microsoft SQL Server JDBC driver. In the “query” option if you want to read a full table then provide the table name, otherwise, if you want to run the select query, specify the same. The data returned by the SQL is stored in a Spark dataframe.
jdbcDF = spark.read.format("jdbc")
.option("url", url)
.option("query", query2)
.option("user", user)
.option("password", password)
.option("driver", "com.microsoft.sqlserver.jdbc.SQLServerDriver")
.load()
jdbcDF.show(5)
Save Dataframe as CSV File
The dataframe can be stored on the server as a . CSV file. Noe this step is optional in case you want to write the dataframe directly into an S3 bucket this step can be skipped. PySpark, by default, creates multiple partitions, to avoid it we can save it as a single file by using the coalesce(1) function. Next, we move the file to the designated output folder. Optionally, delete the output directory created if you only want to save the dataframe on the S3 bucket.
path = 'output'
jdbcDF.coalesce(1).write.option("header","true").option("sep",",").mode("overwrite").csv(path)
shutil.move(glob.glob(os.getcwd() + '/' + path + '/' + r'*.csv')[0], os.getcwd()+ '/' + filename )
shutil.rmtree(os.getcwd() + '/' + path)
Copy Dataframe to S3 Bucket
First, create a ‘boto3’ session using the AWS access and secret key values. Retrieve the S3 bucket and subdirectory values where you want to upload the file. The upload_file() method accepts a file name, a bucket name, and an object name. The method handles large files by splitting them into smaller chunks and uploading each chunk in parallel.
session = boto3.Session(
aws_access_key_id=ACCESS_KEY,
aws_secret_access_key=SECRET_KEY,
)
bucket_name=BUCKET_NAME
s3_output_key=DIRECTORY + filename
s3 = session.resource('s3')
# Filename - File to upload
# Bucket - Bucket to upload to (the top level directory under AWS S3)
# Key - S3 object name (can contain subdirectories). If not specified then file_name is used
s3.meta.client.upload_file(Filename=filename, Bucket=bucket_name, Key=s3_output_key)
Cleanup Files
After uploading the file to the S3 bucket, delete any files remaining on the server, else throw an error.
if os.path.isfile(filename):
os.remove(filename)
else:
print("Error: %s file not found" % filename)
Conclusion
Apache Spark is an open-source, cluster computing framework with in-memory processing ability. It was developed in the Scala programming language. Spark offers many features and capabilities that make it an efficient Big Data framework. Performance and speed are the key advantages of Spark. You can load the terabytes of data and can process it without any hassle by setting up a cluster of multiple nodes. This article gives an idea of writing a Python-based ETL.







New comment