Introduction
In 2018, Jacob Devlin and his colleagues from Google developed a powerful Transformer-based machine learning model, BERT, for NLP applications. BERT is a perfect pre-trained language model that helps machines learn excellent representations of text with context in many natural language tasks and thus outperforms the state-of-the-art.
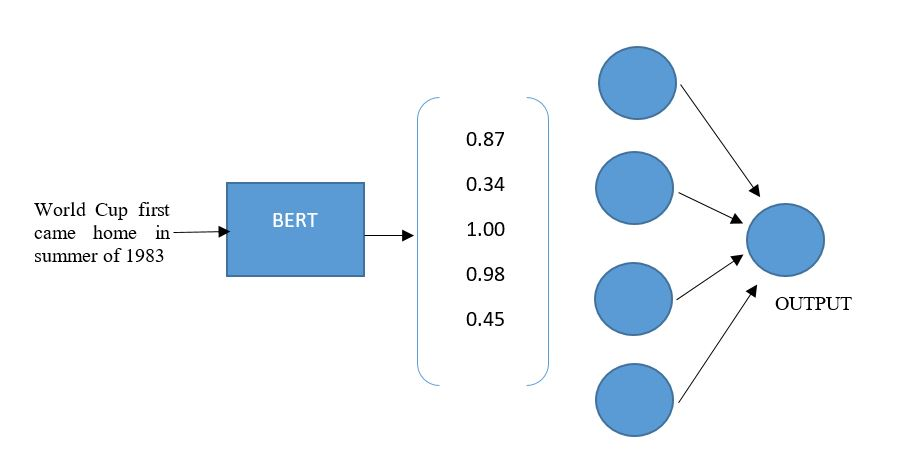
This article will use a pre-trained BERT model for a binary text classification problem, one of the many NLP tasks. In text classification, the main aim of the model is to categorize a text into one of the predefined categories or labels.
Illustration of usage of BERT model
In the above image, the output will be one of the categories, i.e., 1 or 0, in the case of binary classification. Soon, we will use the pre-trained BERT model to classify the email text as ham or spam category.
But before moving to the implementation, let’s briefly discuss the concept of BERT and its usage.
This article was published as a part of the Data Science Blogathon.
What is BERT?
BERT is an acronym for Bidirectional Encoder Representations from Transformers, a model architecture that has revolutionized natural language processing tasks through transfer learning. The BERT architecture is composed of several Transformer encoders stacked together. Further, each Transformer encoder comprises two sub-layers: a feed-forward layer and a self-attention layer.
BERT uses a Transformer that learns contextual relations between words in a sentence/text. The transformer includes two mechanisms: an encoder that reads the text input and a decoder that generates a prediction for any given task. BERT uses only the encoder, as its goal is to generate a language model.
If you want to read more about transformers, please refer to the paper by Google.
In contrast to state-of-the-art models, the Transformer encoder, a key component of deep learning architectures, reads the entire sentence simultaneously as it is bidirectional and thus more accurate. The bidirectional characteristic allows the model to learn all surroundings (right and left of the word) of words to understand the context better
Text Classification with BERT
Now, we will jump to the implementation part, where we will perform text classification using a BERT-based classifier for sentiment analysis. In this post, we will use the SMS Spam Collection dataset. You can download the dataset from here if you want to follow along.
This dataset is already in CSV format, and it has 5169 SMS, each labeled under one of 2 categories: ham or spam.
Let’s look at the first 5 rows of the text data to understand the dataset and its appearance. The name of the dataset is “SMSSpamCollection”.
# python
import pandas as pd
df= pd.read_csv('SMSSpamCollection', sep='t', names=["label", "message"])
df.head()
As can be seen from the above image, the data frame only has two columns: a label that defines whether SMS is ham or spam and a message that consists of SMS, which will be our input data to the BERT model.
For clarity, we rename the columns as Category and Message.
df.rename(columns = {'label':'Category', 'message':'Message'}, inplace = True)
df.head()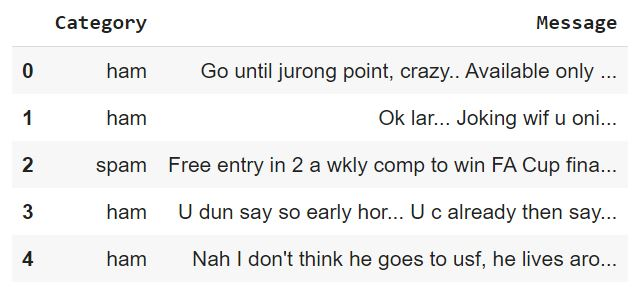
In the above image, the column names have been changed from label to Category and message to Message.
Now, we will define a variable called spam, a dictionary that maps the Category in the dataframe to a numeric value acceptable by the model and uniquely identifies each Category.
df['spam']=df['Category'].apply(lambda x: 1 if x=='spam' else 0)
df.head()
In the above code, ham is mapped to 0, and spam is mapped to 1.
Next, we split the dataset into train and test and used stratified sampling for partitioning.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(df['Message'],df['spam'], stratify=df['spam'])
X_train.head(4)Split the dataset into train and test and use stratified sampling for partitioning

he first four entries of X_train are shown in the above image. X_train consists of SMS while the corresponding label is in y_train for the training dataset.
Once preprocessing is done, the next step is to download the BERT preprocessor and encoder for generating the model. Our model consists of one dense layer with 1 output unit that will give the probability of SMS being spam or ham as the sigmoid function is being used. After running the code above for 2 epochs, an accuracy of 90.07% is achieved from the training dataset. The accuracy we get can slightly differ due to the randomness of the training process.
import tensorflow as tfimport tensorflow_hub as hub!pip install tensorflow-textimport tensorflow_text as text
bert_preprocess = hub.KerasLayer("https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3")
bert_encoder = hub.KerasLayer("https://tfhub.dev/tensorflow/bert_en_uncased_L-12_H-768_A-12/4")
# Bert layers
text_input = tf.keras.layers.Input(shape=(), dtype=tf.string, name='text')
preprocessed_text = bert_preprocess(text_input)
outputs = bert_encoder(preprocessed_text)
# Neural network layers
l = tf.keras.layers.Dropout(0.1, name="dropout")(outputs['pooled_output'])
l = tf.keras.layers.Dense(1, activation='sigmoid', name="output")(l)
# Use inputs and outputs to construct a final model
model = tf.keras.Model(inputs=[text_input], outputs = [l])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=2, batch_size = 32)
y_predicted = model.predict(X_test)
y_predicted = y_predicted.flatten()
print(y_predicted)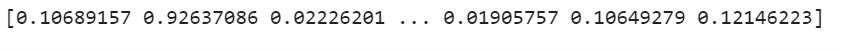
After training the model on the training dataset, we can predict the labels corresponding to the test dataset. It should be noted that in the above image, values are between (0,1). These are due to using the sigmoid function in the last layer, which outputs a tensor of probabilities. We can further classify these values into 1 or 0, i.e., spam or ham, based on some cutoff value, say 0.5.
For users interested in trying out the model themselves, platforms like Google Colab offer free access to GPU resources, facilitating efficient model training and evaluation.
Conclusion
We have tried leveraging the pre-trained BERT model to classify the text in the simplest possible way. I hope this tutorial helps any beginner to get started with the BERT model with the simplest coding.
One thing to note is that BERT, like many deep learning algorithms, has many parameters that require high computing resources. The model training takes a lot of time and cost. To accelerate the speed of model training, other existing embedding models, such as GloVe, etc., can be used at the cost of accuracy. Further, usage of BERT is not limited to text or sentence classification. Still, it can also be applied to advanced Natural Language Processing applications such as next-sentence prediction, question answering, or Named-Entity-Recognition tasks. Also, it’s crucial to emphasize the importance of validation. Validation helps ensure that the model generalizes well to unseen data and provides insights into its performance metrics.”
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.
Frequently Asked Questions
Q1. What are the best practices for fine-tuning BERT for text classification tasks?
A. Fine-tuning BERT involves adjusting hyperparameters such as the learning rate. Best practices recommend using libraries like numpy and PyTorch for efficient implementation and fine-tuning BERT for specific text classification tasks.
Q2. How does the BERT model work for text classification?
A. BERT utilizes transfer learning to understand the context of text data. In a text classification task, BERT first learns representations of text through pre-training, then fine-tuning the model with labeled data. Efficient implementations can be achieved using Numpy and PyTorch. In a binary text classification task, BERT outputs probabilities, where the probability of 0 corresponds to “true” and 1 corresponds to “false”.
Q3. What is the difference between BERT and GPT?
A. Both BERT and GPT are transformer-based models utilized in natural language processing. While BERT focuses on bidirectional context understanding for tasks like text classification, GPT utilizes unidirectional context generation for tasks like text generation.
Q4. What are the preprocessing steps required for implementing BERT for text classification?
A. Preprocessing steps for implementing BERT for text classification tasks include tokenization, truncation of input sequences to fit the model’s maximum length, and padding to ensure uniform input size.
Utility functions (utils) in libraries like Hugging Face Transformers can aid in these preprocessing tasks.








Hi awesome article, I got stuck here import tensorflow_text as text kindly guide
I would like to use BERT to classify news articles. My questions are: 1) How do I know that my text input is less than 512 tokens? 2) How I can I use BERT to classify the whole article and not just a part of it? Or should I really do an arithmetic mean of the classification result of each part of the whole article?