This article was published as a part of the Data Science Blogathon
Introduction
In the past few years, Natural language processing has evolved a lot using deep neural networks. Many state-of-the-art models are built on deep neural networks.
BERT (Bidirectional Encoder Representations from Transformers) is a very recent work published by Google AI Language researchers. It was a milestone in the field of NLP, where pre-trained deep neural networks were being used in the field of NLP.
BERT uses Transformers (attention layers technique) that learns contextual relations and meaning between words in a text. the basic transformer contains two separate mechanisms, one is an encoder that reads the text input and a decoder that creates output(prediction). The detailed work of Transformers is given in a paper by Google Team.
directional models read the text in a specific direction, (left to right or right to left). Transformers encoder reads all the text at once, so we can say transformers are nondirectional. this property allows transformers to learn the context of words by taking surrounding words in any direction.
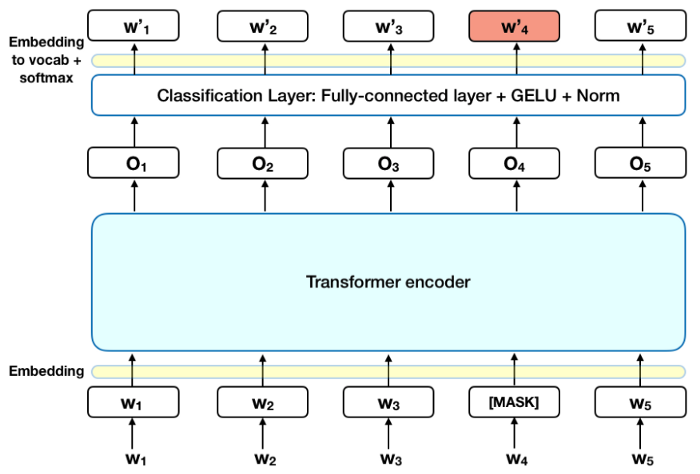
In this article, we will mainly focus on the implementation of Bert in Tensorflow.
what we are going to do?
- Getting Bert downloaded and set up. We will be using the Tensorflow hub.
- Setting up the Bert pre-trained model for fine-tuning.
- Setting the tokenizer.
- The dataset is being loaded and prepared for training.
- Evaluating the performance of the model and testing.
Google’s BERT Model
There are various ways to load Bert models. We can either use the Tensorflow hub or we can use hugging-face.
Here we are going to load it from the TensorFlow hub.
Installing and importing TensorFlow hub:
!pip install --upgrade tensorflow_hub import tensorflow_hub as hub import numpy as np
Loading the BERT model:
## loading bert from tensorhub module_url = "https://tfhub.dev/tensorflow/bert_en_uncased_L-24_H-1024_A-16/1" bert_layer = hub.KerasLayer(module_url, trainable=False)
trainable = False we want to use a pre-trained model, so we are freezing BERT-trained layers.
Here we are loading bert_en_uncased_L-24_H-1024_A-16 model.
It contains L=24 hidden layers (Transformer blocks), a hidden size of H=1024, and A=16 attention heads.
The weights of this model were originally released by the BERT authors.
For the English language, this model was pre-trained using Wikipedia and BooksCorpus. en_uncased
meaning that the model is pre-trained in the English language and its
normalized case insensitive. Random input masking has been applied to word fragments independently for training (as in the original BERT paper).
At this point, we have loaded our BERT with pre-trained layers. Using these pre-trained layers we will design our model for fine-tuning in step 3.
Loading the Tokenizer
For training, we need to pass tokenized words to our BERT model. In order to perform tokenization, tokenization is basically splitting a sentence into its unit words.
!wget --quiet https://raw.githubusercontent.com/tensorflow/models/master/official/nlp/bert/tokenization.pyimport tokenization
Import tokenizer, this is required to pre-process our textual data in the form of BERT. It’s time to design our tokenizer.
vocab_file = bert_layer.resolved_object.vocab_file.asset_path.numpy() do_lower_case = bert_layer.resolved_object.do_lower_case.numpy() tokenizer = tokenization.FullTokenizer(vocab_file, do_lower_case)
vocab_file is the vocabulary file on which the Bert model is trained. do_lower_case will lower case all the tokens generated. The class FullTokenizer takes vocab_file and other parameters.
calling tokenizer:
tokenizer.tokenize('Where are you going?')

Understanding the Data Format BERT takes for Training
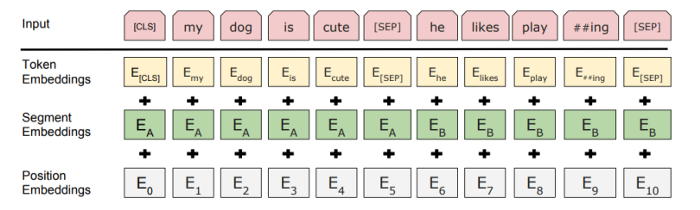
BERT data-input is a combination of 3 embeddings depending on the task we are performing :
Position Embeddings: BERT learns the position/location of words in a sentence via positional embeddings. This embedding helps BERT to capture the ‘order’ or ‘sequence’ information of a given sentence.
Segment Embeddings: (Optional Embedding) BERT takes sentence pairs as inputs for (Question-Answering) tasks. BERT learns a unique embedding for the first and the second sentences to help the model differentiate between them.
Token Embeddings: Token embedding basically contains all the information of input text. it is an integer number specified for each unique word token.
A [CLS] token is added to the beginning of the first sentence to indicate the beginning of a sentence, and a [SEP] token is added to the end of each sentence to mark the end of a sentence.
I would highly encourage you to read a very detailed explained article on BERT written by jay alammar.
so far we have loaded BERT layers and have prepared our tokenizer.
It’s time to load the dataset and convert data into BERT input format.
Loading the Dataset
We are going to use the Disaster Tweets dataset, which can be downloaded from this link.
This dataset contains training and testing files.
train = pd.read_csv("../input/nlp-with-disaster-tweets-cleaning-data/train_data_cleaning.csv", usecols=['text','target'])
test = pd.read_csv("../input/nlp-with-disaster-tweets-cleaning-data/test_data_cleaning.csv", usecols = ['text'])

If the target is 1 means that the tweet is particularly talking about a disaster, if the target is 0 means a normal tweet.
Preparing the Dataset into Google’s BERT input format
As we have discussed for the training of BERT we need to convert our textual data into tokens with some specific format.
required imports:
from tensorflow.keras.layers import Dense, Input from tensorflow.keras.optimizers import Adam from tensorflow.keras.models import Model
Creating a function that converts our textual data into BERT input format using tokenizer and some preprocessing.
def bert_encode(texts, tokenizer, max_len=512):
# bert can support max length of 512 only
# here we need 3 data inputs for bert training and fine tuning
all_tokens = []
all_masks = []
all_segments = []
for text in texts:
text = tokenizer.tokenize(text)
text = text[:max_len-2] # here we are trimming 2 words if they getting bigger than 512
input_sequence = ["[CLS]"] + text + ["[SEP]"]
pad_len = max_len - len(input_sequence)
tokens = tokenizer.convert_tokens_to_ids(input_sequence)
tokens += [0] * pad_len
pad_masks = [1] * len(input_sequence) + [0] * pad_len
segment_ids = [0] * max_len
all_tokens.append(tokens)
all_masks.append(pad_masks)
all_segments.append(segment_ids)
return np.array(all_tokens), np.array(all_masks), np.array(all_segments)
The function bert_encode takes tokenizer and text data and returns token embedding, mask/position embedding, and segment embedding.
convert_tokens_to_ids converts word tokens into some specific integer encodings which BERT is already familiar with.
max_length = 512, you can set max_length according to the model and your data.
Note: not all 3 encodings are necessary for training,Token embedding must be included for training.
Calling bert_encode:
train_input = bert_encode(train.text.values, tokenizer, max_len=160)
We are giving max_len = 160 since tweets are within 150 words.
Building Google’s BERT Model
We can design a BERT model with custom output using BERT pre-trained layers according to our needs.
def build_model(bert_layer, max_len=512):
input_word_ids = Input(shape=(max_len,), dtype=tf.int32, name="input_word_ids")
input_mask = Input(shape=(max_len,), dtype=tf.int32, name="input_mask")
segment_ids = Input(shape=(max_len,), dtype=tf.int32, name="segment_ids")
_, sequence_output = bert_layer([input_word_ids, input_mask, segment_ids])
clf_output = sequence_output[:, 0, :]
out = Dense(1, activation='sigmoid')(clf_output)
model = Model(inputs=[input_word_ids, input_mask, segment_ids], outputs=out)
model.compile(Adam(lr=2e-6), loss='binary_crossentropy', metrics=['accuracy'])
return model
The build_model takes pre-trained BERT layers and max_len and returns our model.
- specified default max_len = 512.
- BERT layers inputs array of 3 embeddings [[input_words_tokens][input_maks][segement_ids]], hence creating 3 input layers of the size of max_len.
- sequence_output[:, 0, :] Selection of intermediate hidden states.
- binary_cross_entropy since its a binary classification.
- Dense layer with 1 output and that will be the probability of a tweet to be a disaster tweet.
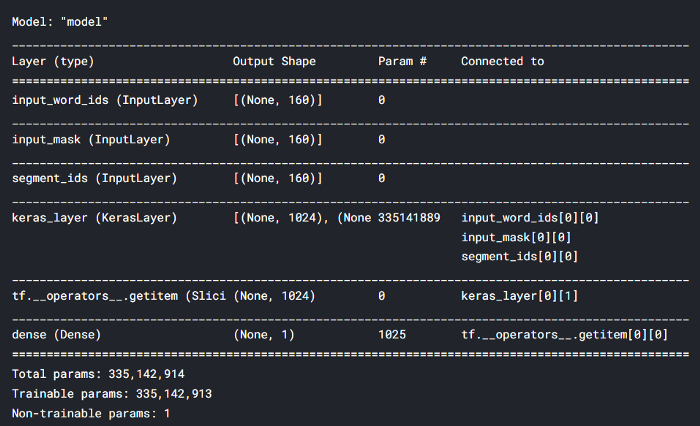
model = build_model(bert_layer, max_len=160) model.summary()
Training
We have successfully designed our model and prepared the dataset. it’s time to train our model.
As you know that we have loaded the BERT pre-trained layer with trainable = False which basically means we are fine-tuning our model according to our use case.
train_history = model.fit(
train_input, train_labels,
validation_split=0.2,
epochs=3,
batch_size=16
)
model.save('model.h5')
validation split = 0.2, 20 % of the training data will be used for validation purposes.

In just 3 epochs we are getting val_accuracy of 82%.
Testing and Validation
For the testing, our data must be in the same format as training data.
test_input = bert_encode(test.text.values, tokenizer, max_len=160) test_pred = model.predict(test_input) prediction = np.where(test_pred>.5, 1,0)
The prediction will be 1 if test_pred >.5 otherwise 0.
test['prediction'] = prediction
Comparing Results:
Filtering disaster’s tweets according to our predicted results.
test[test.prediction == 1]

Perfect!! all our predicted disaster tweets seem to be disaster’s tweets.
Evaluation
In this article, you saw how to use Google’s BERT for binary classification. we got a good result in a few epochs. this is not the end. you can further improve the results by :
- Using a deeper architecture version of BERT, i.e. bert_large has more layers and more information it can learn
- Adding multiple CNN layers after BERT intermediate state.
- using Dynamic learning rate using callbacks.
Conclusion
Google’s BERT is a very powerful language representation model that can promise great results in various NLP tasks. In this article, you saw how to implement BERT for text classification using the TensorFlow hub.
BERT can be implemented using hugging-face transformers and this implementation might look easier than implementation using TensorFlow hub.
In the next article, we will implement Google’s BERT using hugging face transformers.
Source code can be downloaded from this link.
If you liked this article and want to know more uses of BERT then, read here.
Thanks for reading the article, please share below if you liked this article.
Reach out to me on LinkedIn.
Applied Machine Learning Engineer skilled in Computer Vision/Deep Learning Pipeline Development, creating machine learning models, retraining systems and transforming data science prototypes to production-grade solutions. Consistently optimizes and improves real-time systems by evaluating strategies and testing on real world scenarios.




