This article was published as a part of the Data Science Blogathon.
Introduction
BERT is a really powerful language representation model that has been a big milestone in the field of NLP. It has greatly increased our capacity to do transfer learning in NLP. It comes with great promise to solve a wide variety of NLP tasks. Definitely you will gain great knowledge by the end of this article, keep reading. I am sure you will get good hands-on experience with the BERT application. Before deep-diving into actual code, let’s understand BERT.
What is BERT?
BERT is a model that knows to represent text. You give it some sequence as an input, it then looks left and right several times and produces a vector representation for each word as the output. At the end of 2018 researchers at Google AI Language open-sourced a new technique for Natural Language Processing (NLP) called BERT (Bidirectional Encoder Representations from Transformers). A major breakthrough that took the Deep Learning community by storm because of its incredible performance.
Why was BERT needed?
One of the biggest challenges in NLP is the lack of enough training data. Overall there is an enormous amount of text data available, but if we want to create task-specific datasets, we need to split that pile into very many diverse fields. And when we do this, we end up with only a few thousand or a few hundred thousand human-labeled training examples. Unfortunately, in order to perform well, deep learning-based NLP models require much larger amounts of data — they see major improvements when trained on millions, or billions, of annotated training examples.
To help bridge this gap in data, researchers have developed various techniques for training general-purpose language representation models using the enormous piles of unannotated text on the web (this is known as pre-training). These general-purpose pre-trained models can then be fine-tuned on smaller task-specific datasets, e.g., when working with problems like question answering and sentiment analysis.
This approach results in great accuracy improvements compared to training on the smaller task-specific datasets from scratch. BERT is a recent addition to these techniques for NLP pre-training; it caused a stir in the deep learning community because it presented state-of-the-art results in a wide variety of NLP tasks, like question answering.
How does it work?
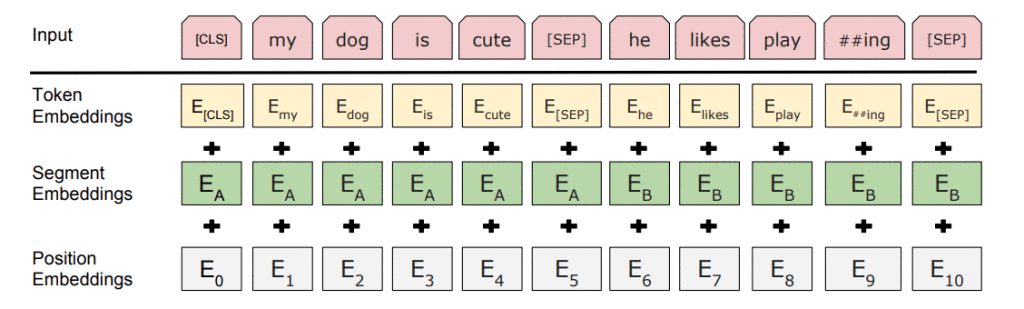
BERT relies on a Transformer (the attention mechanism that learns contextual relationships between words in a text). A basic Transformer consists of an encoder to read the text input and a decoder to produce a prediction for the task. Since BERT’s goal is to generate a language representation model, it only needs the encoder part. The input to the encoder for BERT is a sequence of tokens, which are first converted into vectors and then processed in the neural network. But before processing can start, BERT needs the input to be massaged and decorated with some extra metadata:
- Token embeddings: A [CLS] token is added to the input word tokens at the beginning of the first sentence and a [SEP] token is inserted at the end of each sentence.
- Segment embeddings: A marker indicating Sentence A or Sentence B is added to each token. This allows the encoder to distinguish between sentences.
- Positional embeddings: A positional embedding is added to each token to indicate its position in the sentence.
Let’s start the application of BERT:

Step1: Loading the Required packages
import numpy as np import pandas as pd import tensorflow as tf import tensorflow_hub as hub import logging logging.basicConfig(level=logging.INFO)

We will need a BERT Tokenization class

!wget --quiet https://raw.githubusercontent.com/tensorflow/models/master/official/nlp/bert/tokenization.py
Build a BERT Layer
import tensorflow_hub as hub import tokenization module_url = 'https://tfhub.dev/tensorflow/bert_en_uncased_L-12_H-768_A-12/2' bert_layer = hub.KerasLayer(module_url, trainable=True)
Step2: Understand the Problem Statement and import the Datasets
I am using Git hub bugs prediction dataset and it is available in MachineHack platform. Our aim is to predict the bugs,features and questions based on GitHub titles and the text body.
train=pd.read_json("embold_train.json").reset_index(drop=True)
test=pd.read_json("embold_test.json").reset_index(drop=True)
Dataset description:
- train.json – 150000 rows x 3 columns (Includes label Column as Target variable)
- test.json – 30000 rows x 2 columns
Glimpse of train.json
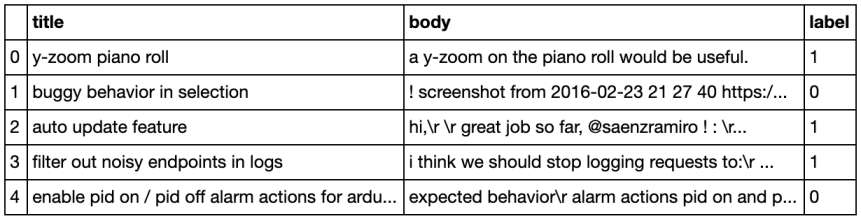
Glimpse of test.json

Attribute Description:
- Title – the title of the GitHub bug, feature, question
- Body – the body of the GitHub bug, feature, question
- Label – Represents various classes of Labels
- Bug – 0
- Feature – 1
- Question – 2
Preprocessing: Combining the title and body column
train['Review'] = (train['title'].map(str) +' '+ train['body']).apply(lambda row: row.strip())
test['Review'] = (test['title'].map(str) +' '+ test['body']).apply(lambda row: row.strip())
Step3: Encoding the raw text
Tokenization is a process to take raw texts and split into tokens, which are numeric data to represent words.
Official BERT language models are pre-trained with WordPiece vocabulary and use, not just token embeddings, but also segment embeddings distinguish between sequences, which are in pairs, e.g. question answering examples. Position embeddings are needed in order to inject positional awareness into the BERT model as the attention mechanism does not consider positions in context evaluation.
The important limitation of BERT to be aware of is that the maximum length of the sequence for BERT is 512 tokens. For shorter sequence input than the maximum allowed input size, we would need to add pad tokens [PAD]. On the other hand, if the sequence is longer, we need to cut the sequence. This BERT limitation on the maximum length of the sequence is something that you need to be aware of for longer text segments.
Very important are also the so-called special tokens, e.g. [CLS] token and [SEP] tokens. The [CLS] token will be inserted at the beginning of the sequence, the [SEP] token is at the end. If we deal with sequence pairs we will add additional [SEP] token at the end of the last.
vocab_file = bert_layer.resolved_object.vocab_file.asset_path.numpy() do_lower_case = bert_layer.resolved_object.do_ lower_case.numpy() tokenizer = tokenization.FullTokenizer(voc ab_file, do_lower_case) def bert_encode(texts, tokenizer, max_len=512): all_tokens = [] all_masks = [] all_segments = [] for text in texts: text = tokenizer.tokenize(text) text = text[:max_len-2] input_sequence = ["[CLS]"] + text + ["[SEP]"] pad_len = max_len - len(input_sequence) tokens = tokenizer.convert_tokens_to_ ids(input_sequence) + [0] * pad_len pad_masks = [1] * len(input_sequence) + [0] * pad_len segment_ids = [0] * max_len all_tokens.append(tokens) all_masks.append(pad_masks) all_segments.append(segment_ ids) return np.array(all_tokens), np.array(all_masks), np.array(all_segments)
Step 4: Build the Model
def build_model(bert_layer, max_len=512): input_word_ids = tf.keras.Input(shape=(max_len,), dtype=tf.int32, name="input_word_ids") input_mask = tf.keras.Input(shape=(max_len, ), dtype=tf.int32, name="input_mask") segment_ids = tf.keras.Input(shape=(max_len, ), dtype=tf.int32, name="segment_ids") pooled_output, sequence_output = bert_layer([input_word_ids, input_mask, segment_ids]) clf_output = sequence_output[:, 0, :] net = tf.keras.layers.Dense(64, activation='relu')(clf_output) net = tf.keras.layers.Dropout(0.2)(n et) net = tf.keras.layers.Dense(32, activation='relu')(net) net = tf.keras.layers.Dropout(0.2)(n et) out = tf.keras.layers.Dense(5, activation='softmax')(net) model = tf.keras.models.Model(inputs=[ input_word_ids, input_mask, segment_ids], outputs=out) model.compile(tf.keras.optimiz ers.Adam(lr=1e-5), loss='categorical_ crossentropy', metrics=['accuracy']) return model
ReLu: The Rectified Linear Unit is the most commonly used activation function in deep learning models. The function returns 0 if it receives any negative input, but for any positive value, it returns that value back.
Softmax: The function is great for classification problems, especially if we’re dealing with multi-class classification problems, as it will report back the “confidence score” for each class. Since we’re dealing with probabilities here, the scores returned by the softmax function will add up to 1.
We check only the first 150 characters of each review.
You can also increase this length, but the running time will increase too
number of categories=3(bug,feature,question)
max_len = 150 train_input = bert_encode(train.Review.values, tokenizer, max_len=max_len) test_input = bert_encode(test.Review.values, tokenizer, max_len=max_len) train_labels = tf.onclick="parent.postMessage({'referent':'.tensorflow.keras'}, '*')">keras.utils.to_categorical(train.label.values, num_classes=3)
model = build_model(bert_layer, max_len=max_len) model.summary()
Step 5: Run model

Each epoch takes about 1 hour (even with GPU acceleration). After all, we have a large dataset.
checkpoint = tf.keras.callbacks.ModelCheckpoint('model.h5', monitor='val_accuracy', save_best_only=True, verbose=1)
earlystopping = tf.keras.callbacks.EarlyStopping(monitor='val_accuracy', patience=5, verbose=1)
train_history = model.fit(
train_input, train_labels,
validation_split=0.2,
epochs=3,
callbacks=[checkpoint, earlystopping],
batch_size=32,
verbose=1
Predictions for the test data:
model.load_weights('model.h5')
test_pred = model.predict(test_input)
Conclusion:
- Open kaggle Kernal and try this approach as mentioned above steps. Definitely you will get better results. I got 16 ranks in MachineHack(GitHub bugs prediction) with this approach.
- Each epoch model saves the results using checkpoint, no need to run again. Every time it saves the model.
- I hope this article helpful and very thanks to Analytics Vidhya for giving this wonderful opportunity.
Introducing myself:
My self Chandrashekhar Tandoori, I am actively participating in online DataScience competitions.
I am MachineHack GrandMaster(Global Rank 7) and Analytics Vidhya Rank 384.





There is a slight change At Dense layer.I have mentioned 5 , Please change it to 3(because we have 3 categories in our train data). out = tf.keras.layers.Dense(3, activation='softmax')(net). train_labels = tf.keras.utils.to_categorical(train.Review.values, num_classes=3).
There is a slight change at Dense Layer. I have mentioned 5 , please change it to 3(because our train data has 3 categories)[out = tf.keras.layers.Dense(3, activation='softmax')(net)]. train_labels = tf.keras.utils.to_categorical(train.Review.values, num_classes=3).
Amazing work