Recommendation Systems is an important topic in machine learning. There are two different techniques used in recommendation systems to filter options: collaborative filtering and content-based filtering. In this article, we will cover the topic of collaborative filtering. We will learn to create a similarity matrix and compute the cosine similarity. I will try explaining this to you using an example of filtering movies. We will use a user and movie rating matrix to find common movies that have the same interest as other movies. So let’s begin.
This article was published as a part of the Data Science Blogathon!
Recommendation systems predict the user preferences or ratings that users would give to items. The recommendation system is very highly used in movies, news, advisement, music, etc.
The best examples of recommendation systems are YouTube, IMDb, Amazon, Flipkart, etc.
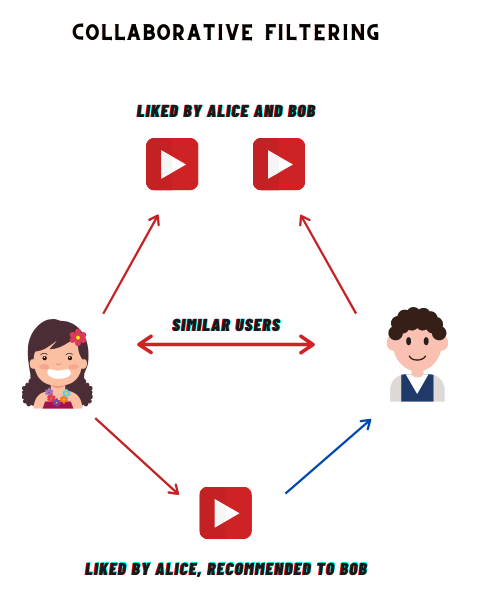
Most recommendation systems use collaborative filtering to find similar patterns or information about the users. This technique can filter out items that users like on the basis of the ratings or reactions by similar users.
An example of collaborative filtering can be to predict the rating of a particular user based on user ratings for other movies and others’ ratings for all movies. This concept is widely used in recommending movies, news, applications, and so many other items.
Let’s take an example to understand more about Collaborative Filtering.
Let’s assume I have user U1, who likes movies m1, m2, and m4, another user U2 who likes movies m1, m3, and m4, and a third user U3 who likes movie m1.
Our job here is to recommend which are the new movies for the user U3 to watch next.
So here we can see users U1, U2, U3 watch/like movie m1. So three have the same taste. Now in user U1, U2 has like/watch movies m4, so user U3 could like movie m4 so I recommend movie m4, this is the flow of logic.
The key idea of Collaborative Filtering is that users who agreed in the past tend to also agree in the future.
There are two types of Collaborative Filtering available:
The most popular Collaborative Filtering is item-item-based Collaborative Filtering. Let’s explore this deeper.
User-user collaborative filtering is one kind of recommendation method that looks for similar users based on the items users have already liked or positively interacted with. Let’s take an eg. to understand user-user collaborative filtering.
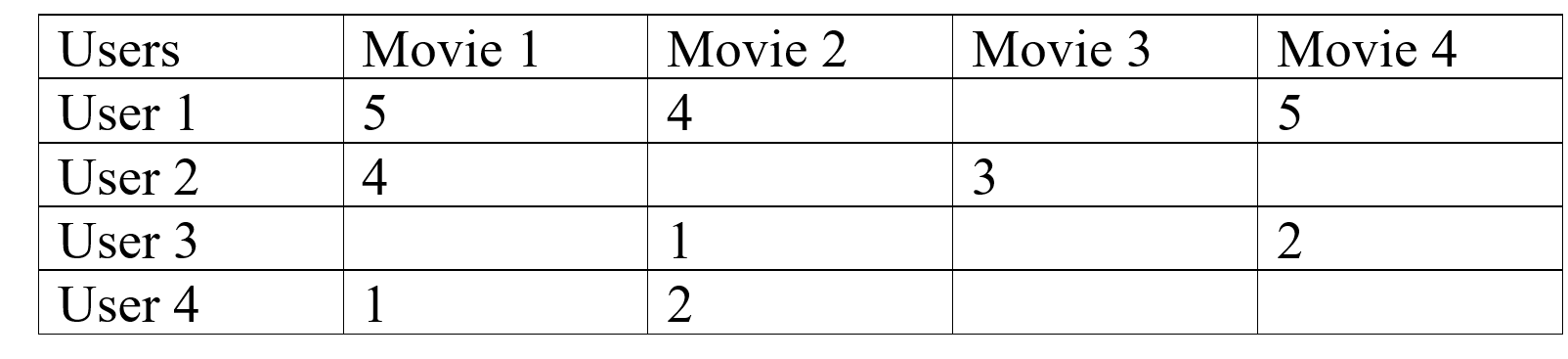
Let’s assume the given matrix A which contains User ID and Item ID and rating or movies.
Source Wikipedia
From this, we can compute a user-user similarity between two users using the cosine similarity formula.
Cosine similarity means the similarity between two vectors of inner product space. It is measured by the cosine of the angle between two vectors.
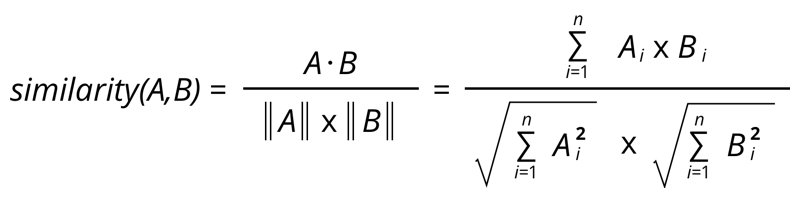
To compute a cosine similarity, let’s take an example:
doc_of_food = 'this food is good but not a highly recommended by the foodies'
doc_of_election = "prime minister ND modi says Putin had no political interference is the election outcome.
doc_of_putin = "Post elections Vladimir Putin became President of Russia President Vladimir Putin had served as the Prime Minister earlier in his political career"doc = [doc_of_food, doc__of_election, doc__ofputin]I assume you all know how to encode a text to a vector. Here we use a TfidfVectorizer() or CountVectorizer() to encode the sentences.
Here we use a CountVectorizer to encode our document/text.
# Scikit Learn
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
# Create the Document Term Matrix
count_vectorizer = CountVectorizer(stop_words='english')
count_vectorizer = CountVectorizer()
sparse_matrix = count_vectorizer.fit_transform(doc)
# not necessary: Convert Sparse Matrix to Pandas Dataframe if you want to see the word frequencies.
doc_term_matrix = sparse_matrix.todense()
df = pd.DataFrame(doc_term_matrix,
columns=count_vectorizer.get_feature_names(),
index= [doc_of_food, doc__of_election, doc__ofputin] )
df# Compute Cosine Similarity
from sklearn.metrics.pairwise import cosine_similarity
print(cosine_similarity(df, df))Output:
[[1. 0.59160798 0.34785054] [0.59160798 1. 0.37416574] [0.34785054 0.37416574 1. ]]
So, given a matrix, I can compute a cosine similarity matrix to represent the similarity between two users.
Simij= similarity(useri , userj)
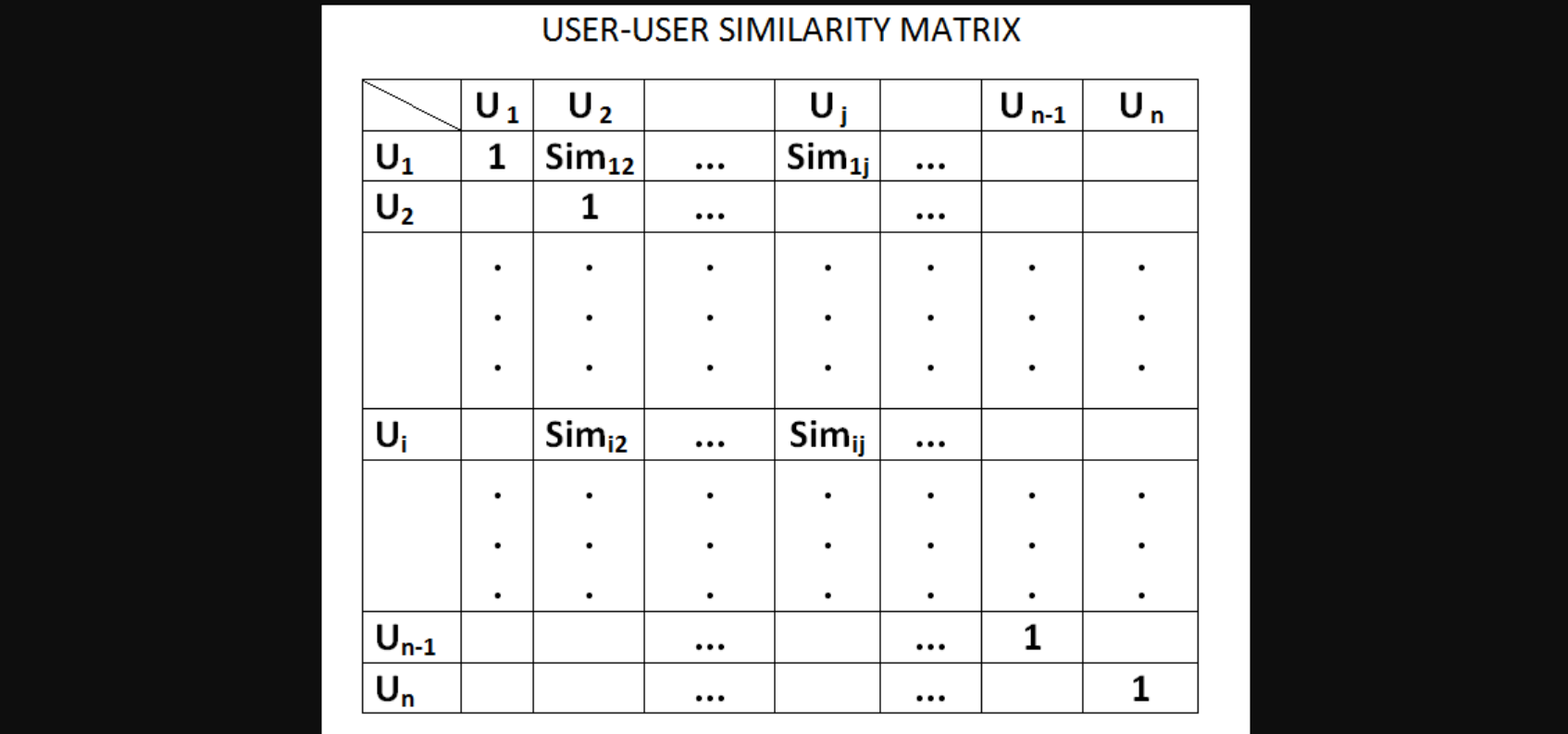
Now that we’ve found a similarity matrix, our task is to recommend a new movie/item to a user.
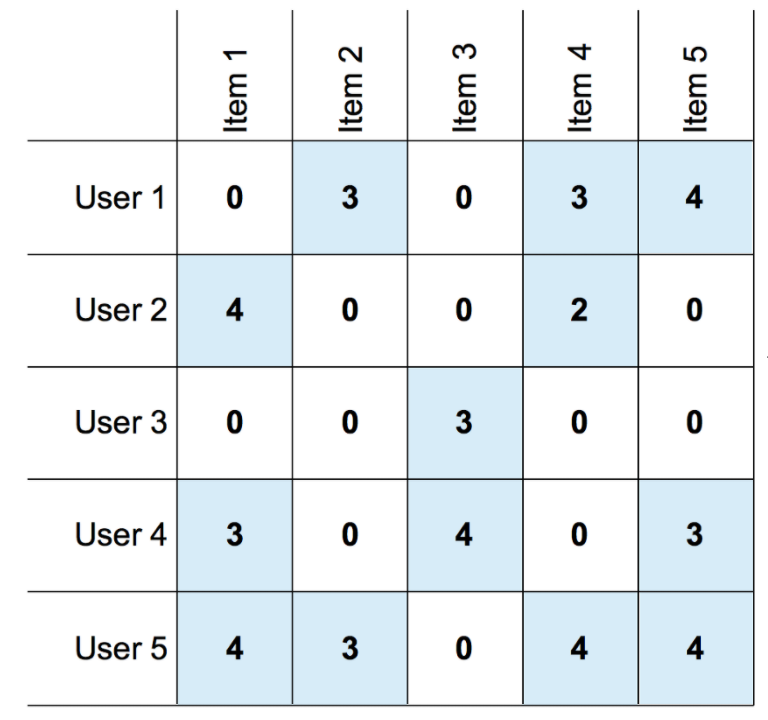
Suppose you have to recommend the top 5 or 5 new movies or items similar to the ones in the matrix, for say, a user 10. For this, we have to create a similarity matrix for user 10 and find the top 5 similar values corresponding to user 10.
Let’s suppose the top 5 users similar to user 10 are users 9, 5, 8, 1, and 2. Now you go into the user-item matrix and combine all items of the users 9, 5, 8, 1, and 2, where they have given a rating value and are not watched by user 10. From this, we then pick all those items and we recommend them to user 10.
However, there can be a small problem with a user-user similarity-based system. User interests change over time, and so do similarity values. This can have a significant impact on the recommendation system.
This brings us to the other approach in collaborative filtering, which is an item item-based similarity recommendation system.
This is also very simple and quite similar in idea to user-user similarity. Item-item similarity solves a problem that occurs in a user user-based similarity. Here we use a similarity matrix of items/movies, to find a similarity between two movies. In order to do this, we use the cosine distance between the two movies.

Simij= similarity(itemi , itemj)
So how to recommend an item to the user?
Let’s suppose we have to recommend new items to user 10, and we know that user 10 already likes/watches items 7, 8, and 1. Now we go to the item-item similarity matrix and take the most similar item to items 7, 8, and 1 based on the similarity values.
Let’s assume:
The items most similar to item 7 are: item 9, item 4, and item 10
The items most similar to item 8 are: item 19, item 4, and item 10
And the items most similar to item 1 are: item 9, item 14, and item 10
Now we take the common items from every set i.e. item 9, item 4, item 10, item 19, and item 14. We then recommend all these items to user 10.
The most popular filtering is item item-based filtering because over time item is not changed like the user user-based similarity.
In this article, we learned to implement user-user and item-item collaborative filtering systems using Python in the context of data science. This can be used to recommend items to users with similar interests and predict the average rating for products in e-commerce platforms.
While working with a vast number of users and items, it is important to strike the balance between computational efficiency and the precision of recommendation systems. You can practice what you learned here on various data science projects to gain insights into the practical application of user-user and item-item collaborative filtering in Python.
Meanwhile, we must also understand the challenges of scalability and dimensionality in collaborative filtering algorithms. Especially regarding the number of items and users. Keeping this in mine, we must explore AI techniques to enhance the efficiency and accuracy of product recommendations.
A. Netflix uses collaborative filtering by analyzing user behavior, preferences, and movie ratings. It recommends content based on the viewing patterns of users with similar tastes.
A. Collaborative filtering is unsupervised. It doesn’t require predefined labels; instead, it identifies patterns and similarities in user behavior.
A. No, Netflix employs a combination of collaborative filtering and other recommendation algorithms. The hybrid approach enhances the accuracy and diversity of recommendations.
Yes, collaborative filtering faces challenges like the cold start problem (for new users or items) and data sparsity. It relies on user-item interactions, and missing or sparse data can affect its effectiveness.
A. Recommendation systems are of two main types: Collaborative Filtering Systems and Content-Based Systems. Collaborative Filtering utilizes algorithms like memory-based (including nearest neighbor techniques) and model-based approaches (employing machine learning algorithms such as matrix factorization) to predict user preferences based on past interactions.
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.
Lorem ipsum dolor sit amet, consectetur adipiscing elit,








Nice introduction blog 👌
Nice introduction Baldha