This article was published as a part of the Data Science Blogathon.
Introduction on Data Preprocessing
In this article, we will learn how to perform filtering operations, so why do we need filter operations? The answer is being a data engineers we have to deal with clusters of data and if we will start analyzing all the data then we will find out that most of it was irrelevant according to our requirements and here comes the role of filtering the relevant columns so that we could get the records based on our business requirements and to achieve that we have two types of filter operations.
- Relational filters: These operations will be working based on relational operators that we are aware of like equal to, less than equal to, or greater than equal to (=, =).
- Logical filters: These are the operations that need to be performed when dealing with multiple conditions specifically. Here we will discuss all three main types of logical operators. They are AND (&), OR(|), NOT(~).

Mandatory Steps on Data Preprocessing
If you are already following my PySpark series then you will easily know what steps I’m gonna perform now. Let’s first discuss them in the nutshell:
- First, we imported the SparkSession to start the PySpark Session.
- Then with the help of the getOrCreate() function, we created our session of Apache Spark.
- At the last, we saw what our spark object holds in a graphical format.
Note: I have discussed these steps in detail in my first article, Getting Started with PySpark Using Python.
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('filter_operations').getOrCreate()
spark
Output:

Reading the Dataset
In this section, we will be reading and storing the instance of our dummy dataset with header and Schema as True which will give us the exact information about the table and its column types.
df_filter_pyspark = spark.read.csv('/content/part2.2.csv', header = True, inferSchema=True)
df_filter_pyspark.show()
Output:
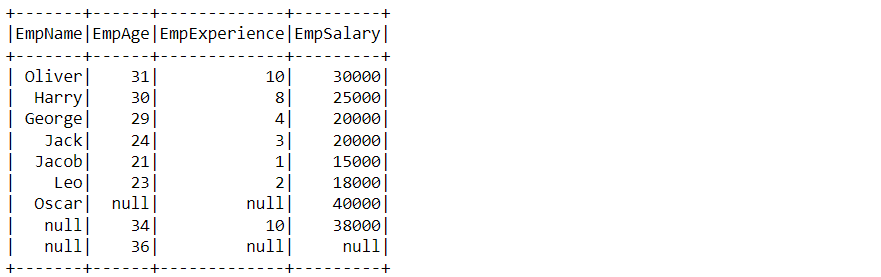
Relational Filtering
Here comes the section where we will be doing hands-on filtering techniques and in relational filtration, we can use different operators like less than, less than equal to, greater than, greater than equal to, and equal to.
df_filter_pyspark.filter("EmpSalary<=25000").show()
Output:

Inference: Here we can see that the records are filtered out where employees have a salary less than or equal to 25000.
Selecting the relevant columns instead of showing all the columns
This is one of the best cost-effective techniques in terms of execution time as when working with a large dataset if we will retrieve all the records (all columns) then it will take more execution time but if we know what records we want to see then we can easily choose selected columns as mentioned below:
df_filter_pyspark.filter("EmpSalary<=25000").select(['EmpName','EmpAge']).show()
Output:
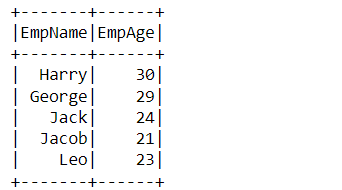
Code Breakdown
So the above code can be broken down into three simple steps for achieving the goal:
- This particular filter operation can also come into the category of multiple filtering as in the first condition we are filtering out the employees based on the salary i.e. when the employee’s salary is less than 25000.
- Then comes the main condition where we are selecting the two columns “Emp-Name” and “Emp-Age” using the select function.
- At the last show the filtered DataFrame using the show function.
Note: Similarly we can use other operators of the relational type according to the problem statement we just need to replace the operator and we are good to go.
Another approach to selecting the columns
Here we will be looking at one more way where we can select our desired columns and get the same result as in the previous output
Tip: By looking at this line of code one will get reminded about how Pandas used to filter the columns.
df_filter_pyspark.filter(df_filter_pyspark['EmpSalary']<=25000).select(['EmpName','EmpAge']).show()
Output:
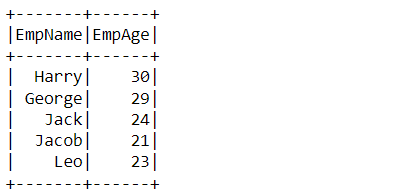
Inference: In the output, we can see that we got the same result as we got in the previous filter operation. The only change we can see here is the way how we selected the records based on the salary – df_filter_pyspark[‘EmpSalary’]<=25000 here we have first taken the object and entered the name of the column then at the last simply we added the filter condition just like we used to do in Pandas.
Logical Filtering
In this section, we will be using different cases to filter out the records based on multiple conditions, and for that, we will be having three different cases
- AND condition
- OR condition
- NOT condition
“AND” condition: The one familiar with SQL or any programming language in which they have to deal with the manipulation of data are well aware of the fact that when we will be using AND operation then it means all the conditions need to be TRUE i.e. if any of the condition will be false then there would not be any output shown.
Note: In PySpark we use the “&” symbol to denote the AND operation.
df_filter_pyspark.filter((df_filter_pyspark['EmpSalary']<=30000)
& (df_filter_pyspark['EmpSalary']>=18000)).show()
Output:

Code breakdown: Here we can see that we used two conditions one where the salary of the employee is less than equal to 30000 & (AND) greater than equal to 18000 i.e. the records which fall into this bracket will be shown in the results other records will be skipped.
- Condtion 1: df_filter_pyspark[‘EmpSalary’]<=30000 where salary is greater than 30000
- Condtion 2: df_filter_pyspark[‘EmpSalary’]<=18000 where salary is less than 18000
- Then we used the “&” operation to filter out the records and at the last show() function to give the results.
“OR” condition: This condition is used when we don’t want to get very stiff with filtration i.e. when we want to access the records if any of the condition is True unlike AND condition where all the condition needs to be True. So be careful to use this OR condition only when you know either of the condition can be picked.
Note: In PySpark we use the “|” symbol to denote the OR operation.
df_filter_pyspark.filter((df_filter_pyspark['EmpSalary']<=30000)
| (df_filter_pyspark['EmpExperience']>=3)).show()
Output:
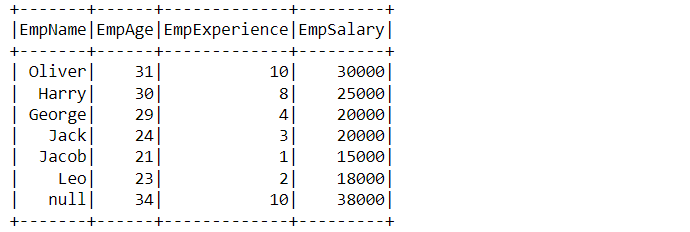
Code breakdown: If one will compare the results of AND and OR then they would get the difference between using both of them and the right time to use it according to the problem statement. Let’s look at how we have used OR operation:
- Condition 1: df_filter_pyspark[‘EmpSalary’]<=30000 here we were plucking out the person who has a salary less than equal to 30000.
- Condition 2: df_filter_pyspark[‘EmpExperience’]>=3 here we were getting the records where the employee’s experience is greater than equal to 3 years.
- For combining both of the conditions we used “|” (OR) operations and at the end used the show function to give the result in the form of a DataFrame.
“NOT” condition: This is the condition where we have to counter the condition i.e. we have to do everything else the condition which we have specified itself if we try to simplify more then we can say that if the condition is False then only NOT operation will work.
Note: In PySpark we use the “~” symbol to denote the NOT operation.
df_filter_pyspark.filter(~(df_filter_pyspark['EmpAge']>=30)).show()
Output:

Inference: Here we can see how the employee who has an age greater than equal to 30 doesn’t even appear in the list of records so it is clear that if the condition is False then only there is the credibility of NOT operation
Note: While using NOT (“~”) we need to keep one thing in mind that we can’t use multiple conditions here as long as we are not combining it with other logical conditions like “AND”/”OR”
Conclusion on Data Preprocessing
In this section we will summarize everything on Data Preprocessing, we did previously like as we started by setting up the environment for the Python’s distribution of PySpark then we had head toward performing both relational and logical filtering on our dummy dataset.
- Firstly, we completed our mandatory steps of setting up the Spark Session and reading the dataset as these are the pillars of further analysis.
- Then we got to know about Relation filtering techniques which include hands-on operations using PySpark DataFrame here we discussed a single operator and learned how to implement another basis on the same approach.
- At last, we move to the second type of filtering, i.e. logical filtering, where we discussed all three types of it: AND, OR, and Not a condition.
Master Data Preprocessing with PySpark—set up your environment, perform relational and logical filtering, and get hands-on with DataFrame operations!
Here’s the repo link to this article. I hope you liked my article on Data Preprocessing using PySpark – Filter operations. If you have any opinions or questions, then comment below.
Connect with me on LinkedIn for further discussion.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.





