Overview
- A fascinating deep dive into the problem of how many classes should you use in a classification problem
- The authors present their findings from two detailed experiments they conducted using the CIFAR-10 dataset
Introduction
Data scientists, have you ever wondered how many classes you should use when working on a classification problem? You are not alone!
Of course, oftentimes, the number of classes is dictated by the business problem you are trying to solve, and that’s not really up to you. And in that case, no doubt that an important question kept nagging you: what if I don’t have the data for that?

This is a crucial question we need to answer before we start building models. This is especially prevalent in industries like healthcare where one class might well outnumber the other by a significant amount.
We will first discuss the reasons why your data might not support your business application. We will then share a real-world case study and walk you through the different experiments we did and what their outcome was. Let’s begin!
Table of Contents
- The Problem of Identifying Different Classes in a Classification Problem
- Experiment 1: Labeling Noise Induction
- Experiment 2: Data Reduction
- Putting it All Together
The Problem of Identifying Different Classes in a Classification Problem
There are, in fact, many reasons why your data would actually not support your use case. Here are a few off the top of our heads:
- The class imbalance in your training set
- The underrepresentation of each class: Too many classes for too little data would lead to a case where there wouldn’t be enough examples for a model to learn each class
- Class “specificity”: The more alike two classes are, the easier it would be to mistake one for the other. For example, it is easier to mistake a Labrador for a Golden Retriever than a dog for a cat
That is a lot to consider even before building a model. And the truth is, your endeavors might be doomed from the beginning, no matter how hard you try to get a high-performance model. This could be either because your data quality is really subpar, or because you don’t have enough of it to allow your model to learn.
That’s when we realized that there was in fact no good framework to identify how well separated two classes were, or how suitable a dataset was to learn how to differentiate examples from two different classes. And that’s what we set out to fix.
Intuitively, the success of a classification project depends a lot on how well-separated classes are – the least “grey areas”, the better. Clearly differentiated classes don’t leave a lot of opportunities for any model to mix things up because the features learned for each class will be specific to each one of them.

Figure 1: An example of a confusing image: should this image be classified as a car or a boat?
Things get more complicated when “look-alike” classes appear, or, for example, when items can classify as more than one type of object. It is in this spirit of discovering a process to measure “look-alikeness” that we started this study on CIFAR-10 with a small custom deep neural net.
The underlying idea is actually pretty simple – to find out which classes are easy for a model to confuse, just try confusing the model and see how easily it gets fooled.
Experiment 1: Labeling Noise Induction
For the purpose of observing the effects of labeling noise induction, we took the clean CIFAR-10 and voluntarily injected labeling noise in the training set’s ground truth labels.
Here is how the process works:
- Randomly select x% of the training set
- Randomly shuffle the labels for those selected records; call this sample Sx
- Train the same model using Sx. Here, our model is a small (6-layer) convolutional neural network (non-important for the conclusion of our experiments)
- Analyze the confusion matrix
Of course, some variance would be expected from selecting such a sample randomly. Hence, we repeated the same experiment multiple times (5 times, due to our own resource limitations) for each amount of pollution and averaged the results before drawing any conclusions.
Below, we show the results for the baseline (trained on the entire training set, S0%) and the average confusion matrix for S10%, i, 1≲i≲5:

Figure 2: The confusion matrix on the left shows the confusion matrix obtained when training with the full CIFAR-10 dataset; on the right is the average confusion matrix when 10% of the data is mislabeled. Important note: The ground truth labels are read at the bottom and the predicted labels on the left (so that on the baseline, there are 82 real cats that were predicted as frogs). We will use the same convention in the rest of the post.
First Analysis
The first finding is that even for the baseline, the confusion matrix isn’t symmetrical.
Not much surprise here, but it is worth noting that there is directionality involved – it’s easier, for instance, for this specific model to mistake a ‘cat’ for ‘deer’, than ‘deer’ for ‘cat’. This means that it is not possible to define a “distance” in the mathematical sense of the term (since distances are symmetrical) between two classes.
We can also see that the accuracy for airplanes isn’t affected much by the pollution. Interestingly, injecting random labeling noise seems to decrease the confusion of ‘cat’ as ‘dog’ while increasing the confusion ‘dog’ as ‘frog’, indicating that noise benefits generalization.
Conclusions:
- Not all classes are equally resistant to labeling noise
- Cross-class confusion is directional
Here’s a figure to help you gain some intuition into wrong predictions. The below figure shows some ‘cat’ class images that were identified as ‘frog’ class along with the probability for that prediction with 10% random pollution injected in the training data:

Figure 3: Images of cats mistaken as frogs. The numbers underneath represent the confidence levels with which they were respectively predicted. The higher the confidence level, the more ‘convinced’ the model is that it made the right prediction.
Taking the Labeling Noise Induction Further
Let’s keep increasing the amount of labeling pollution. This is keeping in mind that in real life, a higher pollution rate would be the consequence of poorer labeling accuracy (typically, more than one annotation is requested when labeling data in order to limit the impact of labeling voluntary or involuntary mistakes).
After running that experiment, we observe that the ‘cat’ class is systematically the least accurate across all pollution levels. However, in the relative confusion matrix, we see that the ‘bird’ class is the most affected one. So, even though the ‘cat’ class is the one that makes the least number of correct predictions, the ‘bird’ class is more severely impacted by the induction of labeling pollution (see the details in the below figure).





Figure 4: The left column shows the confusion matrix for various labeling pollution amounts, while the right column shows the relative confusion matrix for the same pollution amount respectively. The left confusion matrices are obtained by averaging the results of 5 runs to smooth out outlier runs; the relative confusion matrix on the right is the difference of that average matrix and the confusion matrix obtained for the baseline run.
Experiment 2: Data Reduction
A fundamental question then arises: if some classes are more impacted than others when we inject noise in our data, is that due to the fact that the model got misled by the wrong labels, or simply from a lower volume of reliable training data?
In order to answer that question, after analyzing how labeling noise impacted the different classes in CIFAR-10, we decided to run an additional experiment to evaluate the impact of data volume on accuracy.
In this experiment, we went on reducing the size of the training set and see the effects on the confusion matrix. Note that this data reduction experiment was only performed on the clean CIFAR-10, i.e. without any labeling pollution.
From the results displayed in Figure 5 below, it is worth noting that for the model we used, we observed just a 1% drop in the accuracy. This was with a significant 10K drop in data samples training data from the original 50K data samples to 40K data samples.





Figure 5: The left column shows the confusion matrix for various data volume amounts and the right column shows the relative confusion matrix for the same number of training examples. The left confusion matrices are obtained by averaging the results of 5 runs to smooth out outlier runs; the relative confusion matrix on the right is the difference of that average matrix and the confusion matrix obtained for the baseline run.
Just like in the case of labeling pollution, the ‘cat’ class is the least accurate in the absolute but the ‘bird’ class is the most relatively sensitive to data reduction. We can see that the ‘bird’ class is significantly more impacted than the others. And when reducing the size of the training set by 10K from 50K, the absolute number of additional mistakes made by the model goes up by 50 already:
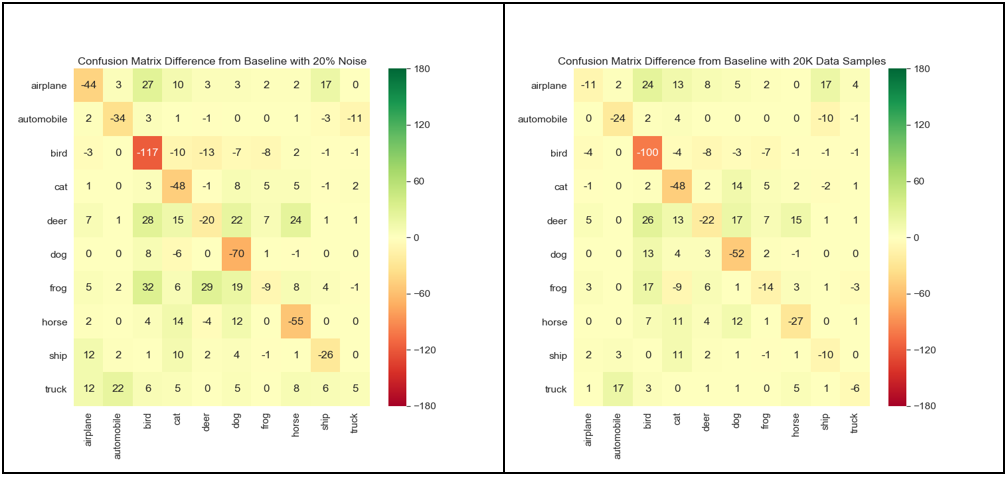
Figure 6: Side-by-side comparison of the relative confusion matrices for the 20% noise induction experiment (left) and the 60% data reduction experiment (right)
In an attempt to compare the relative effect of labeling quality vs. data quantity, we show in the above figure the relative confusion matrices for a 20% amount of labeling noise and a 60% drop in data volume. While we see that ‘cat’ and ‘deer’ classes are equally impacted in both cases, the ‘airplane’ and ‘horse’ classes are more impacted by labeling noise induction.
Conclusions:
- Data volume reduction and labeling pollution affect different classes in different ways
- Different classes have a varied response to each effect, and can either be more resistant to labeling noise, or to a reduction in the size of the training set
We can immediately note that the hottest cell when we start polluting our training set is {bird, bird}. By contrast, the hottest cell for the baseline was {cat, cat}.
This means that even if the ‘bird’ class was not the hardest for the model to learn, it is the one that’s taking the biggest hit from labeling pollution and data reduction. Hence, it is the most sensitive to labeling noise.
Things seem to take a turn for the worse somewhere between 15% and 20% of labeling noise. It seems that 20% labeling noise is just too much for the ‘bird’ class to handle. In the meantime, the ‘frog’ and ‘truck’ classes seem particularly stable.
Now, it is a somewhat intuitive result when looking at a sample of the training images in each one of the ‘bird’ and ‘truck’ classes (see Figure 7):

Figure 7: Samples of training images for the ‘bird’ and ‘truck’ classes. We can see a larger ‘variance’ for ‘bird’, which might make it harder for a model to identify common learnable features to generalize what a bird is.
We are zooming into this effect by looking at the {bird, bird} matrix element as a function of the amount of labeling noise used in the training set and the number of data samples used for training:

Figure 8: Plot of the value of the {bird, bird} matrix element extracted from the relative confusion matrix with pollution and data reduction
Conclusions:
The relationship between amount of labeling noise and the accuracy depends a lot on the class. It is also non-linear
Putting it all Together

Figure 9: Side-by-side comparison of the relative confusion matrices for the 20% noise induction experiment (left) and the 20% data reduction experiment (right).
Let’s now answer the question we had earlier – do results get worse with labeling noise induction because we reduced the amount of ‘good’ data that the model has to learn from, or because bad labels are misleading the model?
By comparing the results for a 20% level of labeling noise and those for a 20% volume reduction, we can see right away that the accuracy is always worse for labeling pollution. This proves that bad labels are actually impacting the model negatively even in small quantities.
In an effort to compare how different classes respond to the stress we applied to our model, we present a summary of our various experiments in one single table below, where each column shows the classes sorted by order of accuracy.
For the baseline, the class with the worst accuracy was ‘cat’, followed by ‘dog’ and ’deer’. The order is somewhat shuffled from one experiment to the other.
What we see here is that the ‘cat’ class, being the one that performs worse on the baseline, is also the worst with labeling noise induction and data reduction. That suggests that the model we used is not finding it easy to learn what cats are, and gets easily fooled with fake cats as well. The ‘bird’ class is especially badly impacted by both data volume reduction.
By contrast, ‘frog’ and ‘truck’ classes are fairly easy for the model to learn, and “lying” to the model about ‘frog’ and ‘truck’ doesn’t seem to matter much. In that sense, it’s like the ‘frog’ and ‘truck’ class can take significantly more bad labels compared to other classes.

Figure 10: Classes sorted according to their accuracy with their respective true prediction scores, across various experiments (left: baseline, center: 30% labeling noise, right: 90% noise reduction). We can immediately see how the ‘bird’ class, which was performing worse than the ‘dog’ class in the baseline, gets worse than ‘dog’ with extreme volume reduction.
End Notes
A single look at the confusion matrix on our baseline model shows that some classes were more easily confused for each other. Besides, we saw the concept of cross-class confusion was non-directional.
Some further experiments proved that even voluntarily trying to confuse the model with bad training labels (i.e.: trying to “lie” to the model) was not equally successful for all classes. We found in the process that some classes were more sensitive to bad labels than others.
In other terms, not only are some confusions more likely than others (even on the baseline), but they are also a function of both labeling quality and data quantity (and some confusions become more likely much faster than others when the training data’s volume or quality drops).
Next Steps
In future sequels to this blog post, we will discuss:
- Whether cross-class confusion has a dependency on the model used, or if it is intrinsic to the dataset itself
- Whether/how data quantity can make up for labeling quality
About the Authors
Jennifer Prendki – Founder and CEO, Alectio

Jennifer is the founder and CEO of Alectio and has spent a large part of her career promoting the importance of creating a better approach to Machine Learning Lifecycle Management. Her current focus is on helping ML teams curate their data so that they can build better models with fewer resources.
Prior to founding Alectio, she was the VP of Machine Learning at Figure Eight, one of the industry leaders in data labeling (recently acquired by Appen).
She also headed Machine Learning at Atlassian and various Data Science initiatives on the Search team at Walmart Labs. She is known for her active support of women in STEM and Technology.
Akanksha Devkar – Machine Learning Engineer, Alectio

Akanksha is a Machine Learning Engineer at Alectio focusing on developing Active Learning strategies and other Data Curation algorithms. When not training neural networks on the machine, she is mostly firing her neurons in having thought experiments. She lives to eat and loves to star-gaze.
Need help curating your dataset or diagnosing your model? Contact us at Alectio! 🙂






