This article was published as a part of the Data Science Blogathon.
Introduction
We are all pretty much familiar with the common modern cloud data warehouse model, which essentially provides a platform comprising a data lake (based on a cloud storage account such as Azure Data Lake Storage Gen2) AND a data warehouse compute engine such as Synapse Dedicated. Pools or Redshift on AWS. There are nuances around usage and services, but they pretty much follow this kind of conceptual architecture. Azure Synapse analytics is an unlimited analytics service combining data integration, exploration, warehousing, and big data analytics. This unified platform brings together data engineering, machine learning, and business intelligence needs without the need to maintain separate tools and processes.
 (1).png)
In the above architecture, the key themes are as follows –
- Ingesting data into the cloud storage layer, specifically into the “raw” zone of the data lake. The data is untyped, untransformed, and has had no cleaning done. Batch data usually comes as CSV files.
- The processor then cleans and transforms the data in the lake zones, starting with raw -> enriched -> modified (others may know this pattern as bronze/silver/gold). Enriched is where the data is cleaned, de-duplicated, etc., while Curated is where we create our summary outputs, including facts and dimensions, all in the data lake.
- The managed zone is then fed into a cloud data warehouse such as Synapse Dedicated SQL Pools, which act as a service layer for BI tools and analysts.
This pattern is prevalent and is still probably the one I see most often in the field.
So far, so fantastic. Although this is the most common formula, it is not a unicorn approach for everyone. This approach has potential problems, especially regarding handling the data and files in the data lake.
These perceived challenges gave rise to the “Lakehouse” architectural pattern. They were officially featured on the back of an excellent white paper by Databricks, the founders of the Lakehouse pattern in its current form. This white paper highlighted the problems encountered in the current approach and highlighted the following main challenges:
- Lack of transactional support
- Hard to enforce data quality
- It’s hard/complicated to combine adds, updates, and deletes in a data lake
- This can lead to data management issues in the lake itself, resulting in data swamps rather than data lakes
- It has multiple storage layers – different zones and file types in the lake PLUS inside the data warehouse itself PLUS often in the BI tool as well
So what is Lakehouse?
In short (and this is a bit of an oversimplification, but it will do for this article), the main theme of Lakehouse is 2 things –
- Delta Lake – This is the secret sauce of the Lakehouse pattern, and it tries to solve the problems highlighted in the Databricks document. More on that below.
- Data lake and Data Warehouse is not different at all. They both are the same thing.
The conceptual architecture for the Lakehouse is shown below –
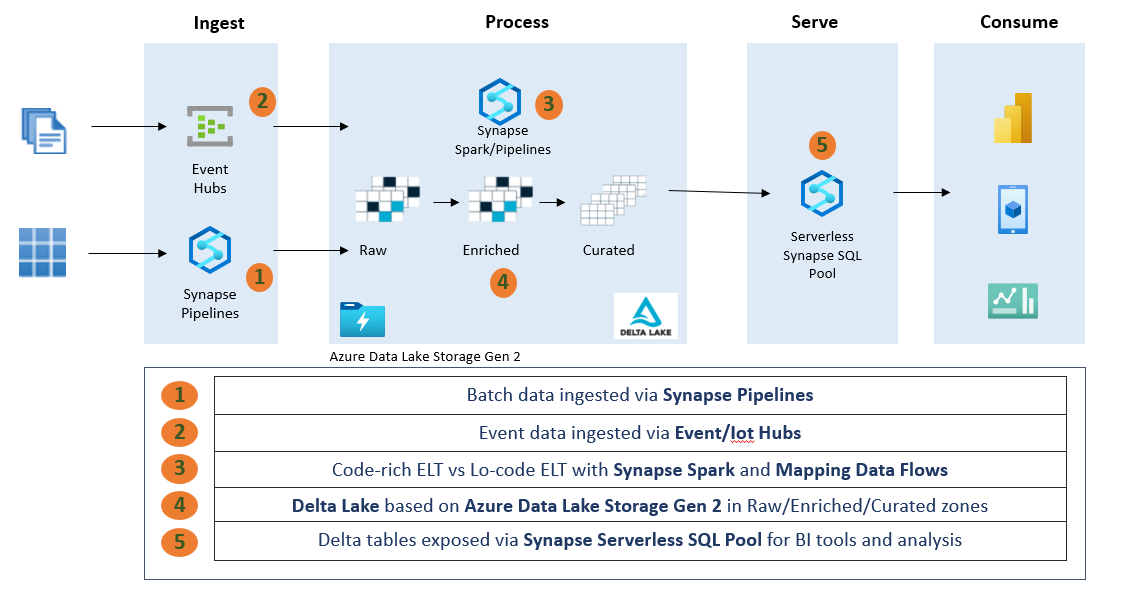
You see, the main difference in terms of approach is that there is no longer a separate compute engine for the data warehouse, instead we serve our output from the lake itself using the Delta Lake format.
What is Delta Lake?
Delta Lake (the secret sauce mentioned above) is an open source project that enables data warehouse functionality directly ON the data lake and is well summarized in the image below –
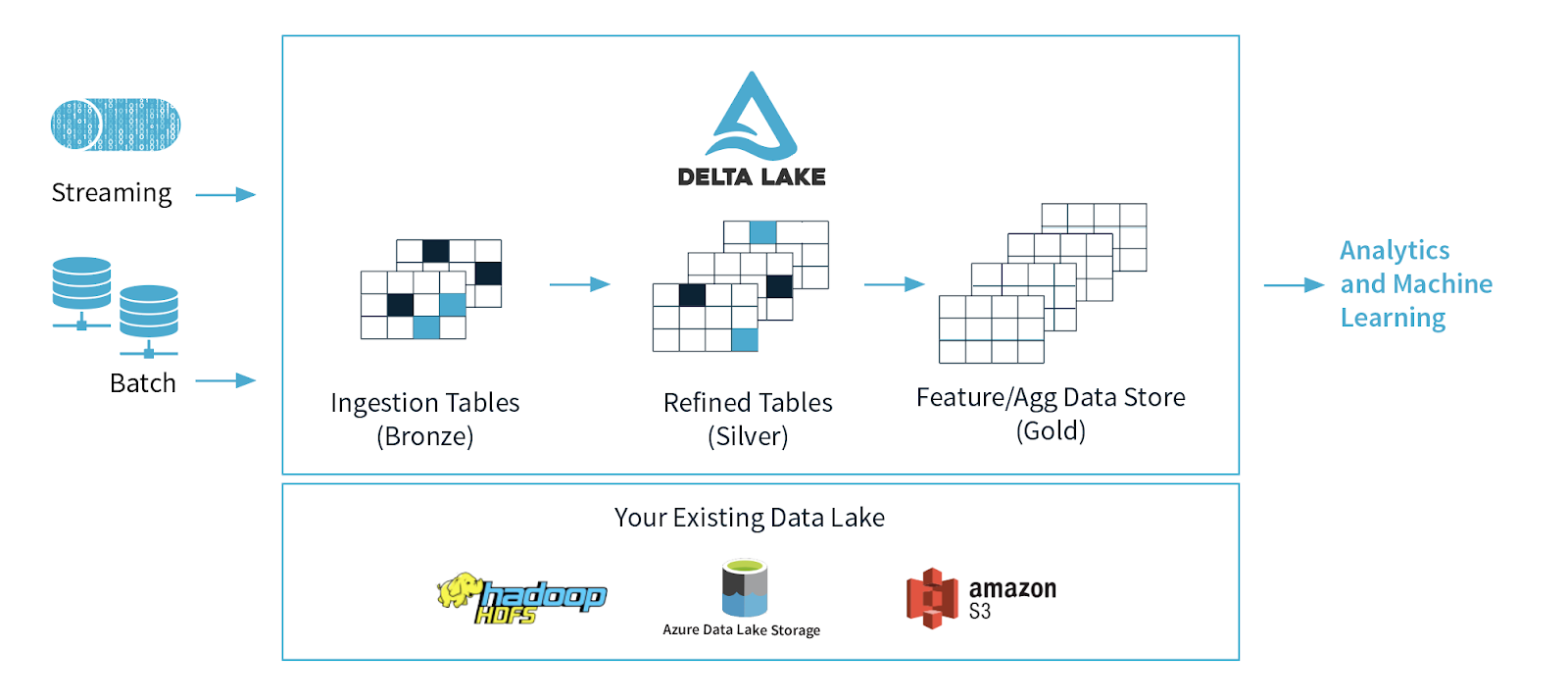
Delta Lake provides ACID (atomicity, consistency, isolation, and durability) of transactions to the data lake, allowing you to run safe and complete transactions in the data lake the same way as you would in a database. Delta manages it for you. Features like Time Travel allow you to query data as in a previous state, such as by timestamp or version (similar to SQL time tables).
Delta allows tables to serve as both batch and streaming sinks/sources. Before, you had to create complex lambda architecture patterns with different tools and approaches – with Delta; you can unify it into one, much simpler architecture. There is no separate data warehouse and data lake.
Schema Enforcement allows us to define typed tables with constraints, data types, and so on, ensuring that our data is clean, structured, and aligned with specific data types.
CRUD – Editing, adding, and deleting data is MUCH easier with Delta.
How does Synapse Analytics support Lakehouse?
Synapse Analytics provides several services that allow you to build a Lakehouse architecture using native Synapse services. It’s worth mentioning that you can, of course, also do this with Azure Databricks. Still, this article is specifically aimed at those users who want to use the full range of Synapse services to build specifically on this platform.
For those who don’t know what Synapse is – in a nutshell, it’s a unified cloud-native analytics platform running on Azure that provides a unified approach that exposes different services and tools depending on the use case and user skills. These range from SQL pools to Spark engines to graphical ETL tools and many more.
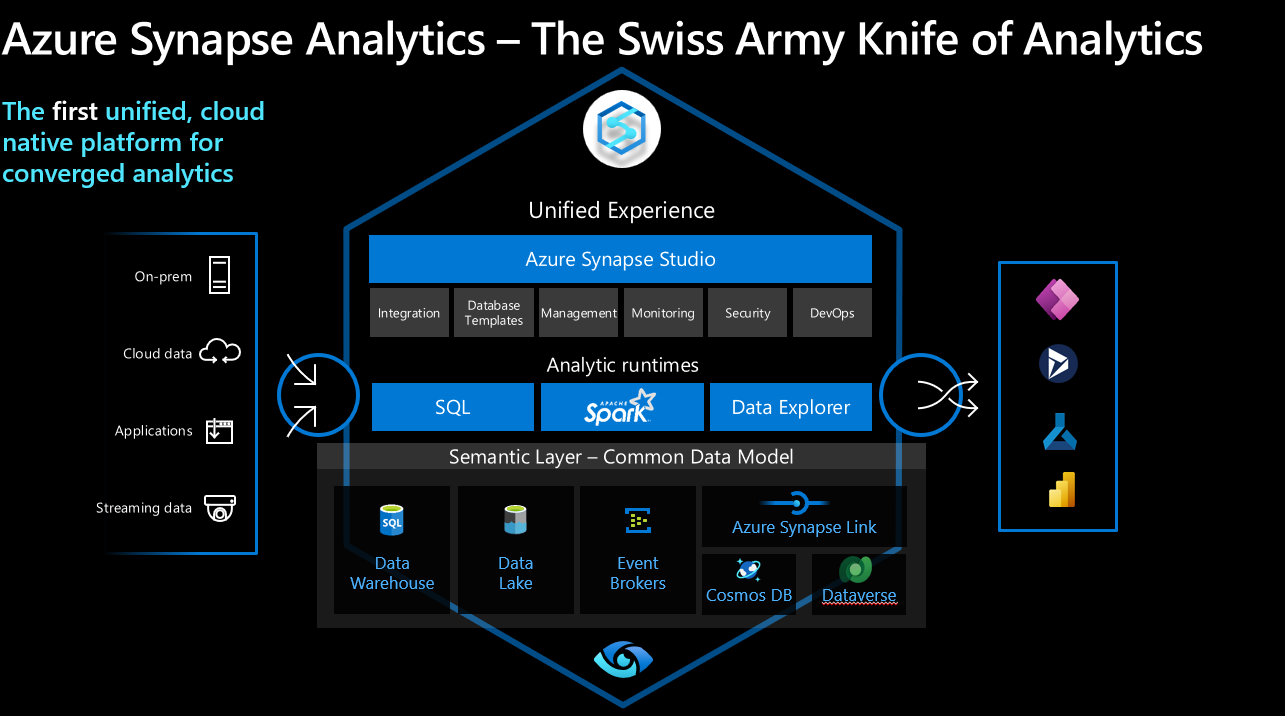
Source: -https://docs.microsoft.com/en-us/azure/synapse
Synapse Pipelines (essentially a Data Factory under the Synapse umbrella) is a graphical ELT/ELT tool that allows you to orchestrate, move and transform data. You can ingest, transform and load your data into Lakehouse by pulling data from a huge number of sources. Regarding Lakehouse specifically, Synapse Pipelines allow you to take advantage of the Delta Lake format using the Inline Dataset type, which allows you to take advantage of all the benefits of Delta, including upserts, time travel, compression, and more.
Synapse Spark, in terms of the Lakehouse pattern, allows you to develop code-based data engineering notebooks using the language of your choice (SQL, Scala, Pyspark, C#). For those who like code-driven ELT/ELT development, Spark is an excellent and versatile platform that allows you to combine code (e.g., perform a powerful transformation in pyspark, then switch to SQL and perform SQL-like transformations on the same data) and run laptop via Synapse Pipelines.
Like Synapse Pipelines, Synapse Spark uses the Spark runtime 3.2, including Delta Lake 1.0. This will allow you to take advantage of all the options that Delta provides.
The last major service I want to mention is SQL Pools – specifically Serverless SQL Pools – in the Lakehouse pattern. Synapse already has the concept of dedicated SQL Pools, which are massively parallel processing (MPP) provisioned database engines designed to serve as the main serving layer.
However, we do not use a dedicated SQL pool at Lakehouse. Instead, we use another SQL Pool offering inside Synapse, Serverless SQL Pools. These are ideal for Lakehouse as they are paid per query, not always with a calculation. They work by creating a T-SQL layer on top of the data lake, allowing you to write queries and create external objects per lake that external Tools can then consume. As for Lakehouse, serverless SQL pools support the Delta format, allowing you to create external objects such as views and tables directly on top of these Delta structures.
Synapse-centric Lakehouse Architecture
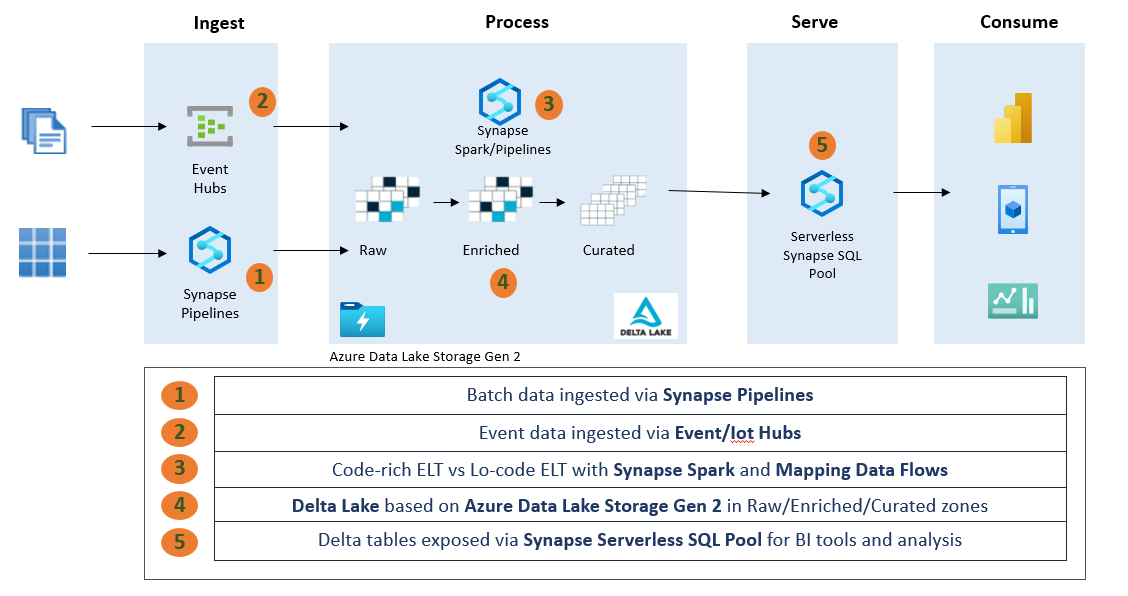
The above shows how we translate these services into an end-to-end architecture using the Synapse platform and Delta Lake.
Source: -https://docs.microsoft.com/en-us/azure/synapse
In short, we have –
Data received in a batch or stream, written to a data lake. This data is fed in a raw format like CSV from databases or JSON from event sources. We don’t use Delta until Enriched further.
Synapse Spark and/or (not a binary choice) Synapse Pipelines are used to transform data from raw to enriched and then modified. Which tool you use is up to you and largely depends on the use case and user preferences. Cleaned and transformed data is stored in Delta format in the enriched and curated zones, as this is where our end users will access our Lakehouse.
The underlying storage is Azure Data Lake Storage Gen 2, which is an Azure cloud storage service optimized for analytics and natively integrates with all services used.
Delta tables are created in Enriched/Curated and then exposed through SQL Serverless objects such as views and tables. This allows SQL analysts and BI users to analyze data and create content using a familiar SQL endpoint that points to our Delta tables on the lake.
Data Lake Zones
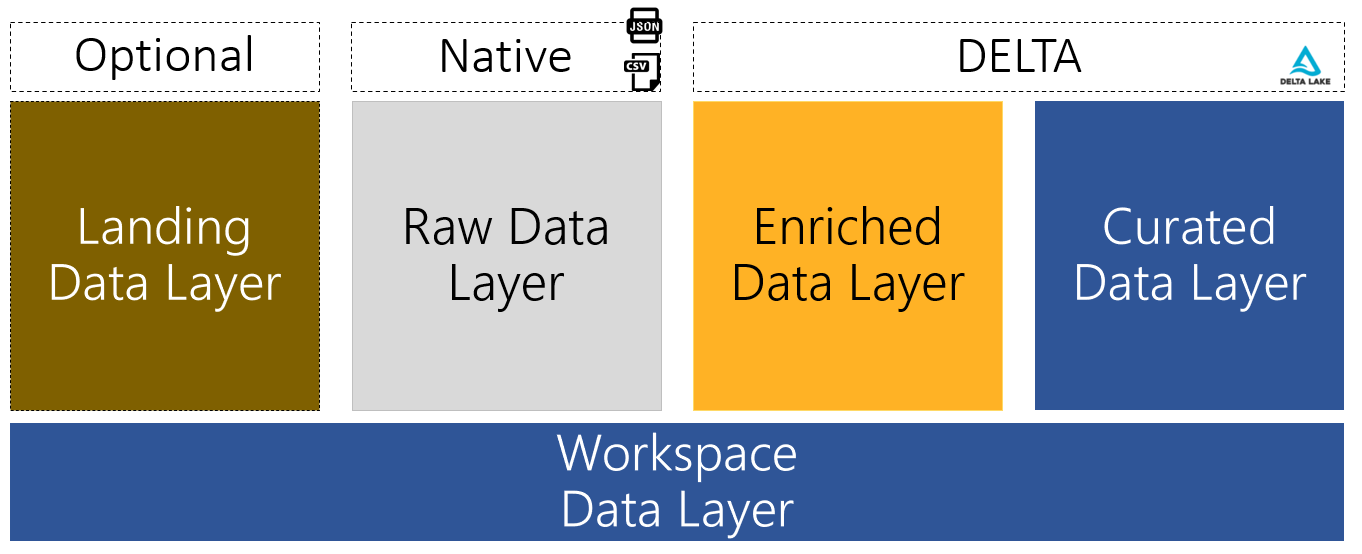
Source:- https://www.oreilly.com/
The landing zone is a transition layer that may or may not be present. It is often used as a temporary dump for daily rations before ingests into the raw layer. In the latter, we often see data stored in subfolders in the append approach, such as
After raw, we see enriched and curated zones now in Delta format. This takes full advantage of Delta and, more importantly, creates a metadata layer that allows data to be accessed/edited/used with other tools via the DeltaAPI.
ELT approaching Lakehouse
Now I’ll do a quick walkthrough that summarizes the approaches in more detail—specifically, how we ingest, transform, and serve data in Synapse using this Lakehouse pattern.
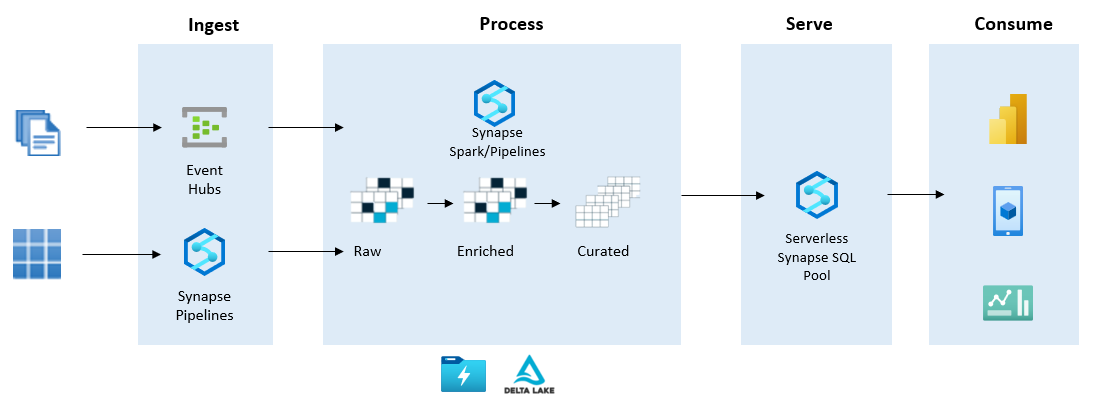
Source: -https://docs.microsoft.com/en-us/azure/synapse
The income for both streaming and batching is pretty much the same in Lakehouse as in the Modern Cloud DW approach. For streaming, we receive with a message broker tool like Event Hubs and then have in-stream transformation capabilities with Stream Analytics or Synapse Spark. Both are read from the event hub queue and allow you to transform the stream in SQL, Pyspark, etc. before landing on the sink of your choice.
Conclusion
This article summarizes how to build a Lakehouse architecture using Synapse Analytics. When writing (March 2022), many more features have been added to Synapse, particularly in the Lakehouse space. New additions such as the Lake database, database templates, and the shared metadata model will only extend Lakehouse’s existing capabilities.
Finally, this article is by no means suggesting that you need to abandon your cloud data warehouse! Far from it! The Lakehouse pattern is an alternative architecture pattern that doubles on a data lake as the main analytics hub but provides a layer that simplifies historical challenges with data lake-based analytics architectures.
- Delta Lake provides ACID (atomicity, consistency, isolation, and durability) of transactions to the data lake, allowing you to run safe and complete transactions in the data lake the same way as you would in a database.
-
Delta tables are created in Enriched/Curated and then exposed through SQL Serverless objects such as views and tables. This allows SQL analysts and BI users to analyze data and create content using a familiar SQL endpoint that points to our Delta tables on the lake.
-
Synapse Spark, in terms of the Lakehouse pattern, allows you to develop code-based data engineering notebooks using the language of your choice. For those who like code-driven ELT/ELT development, Spark is an excellent and versatile platform that allows you to combine code and run laptop via Synapse Pipelines.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.







