Introduction
Enterprises here and now catalyze vast quantities of data, which can be a high-end source of business intelligence and insight when used appropriately. Delta Lake allows businesses to access and break new data down in real time.
Delta Lake is an open-source warehouse layer designed to run on top of data lakes analogous to S3, ADLS, GCS, and HDFS to amend trustability, security, and performance. It supports ACID transactions, extensible metadata, integrated streaming, and batch processing.

Source: tinyurl.com
An open-source spreadsheet format that isn’t vendor-dependent. It’s also saved in the Parquet file format with numerous benefits of warehouse technology and can be distributed anywhere. In addition, it has time travel features, exposes metadata and statistics, and allows for data skipping and z- ordering to enhance query performance.
Learning Objectives
In this article, you will learn about the following:
- Delta Lake adds intelligent data governance and control set to an open warehouse medium for structured,semi-structured, and unstructured data, supporting streaming and batch operations from a single source.
- The Lakehouse combines the best of the data lake and data warehouse. This is open-source, with high performance, reduced data movement and overall cost, and better support for AI and ML workloads.
- The Delta Lake framework runs on top of the current data lake and is exhaustively compatible with the Apache Spark API.
- Here are a few reasons why you should be familiar with the Delta Lakes:
- Delta Lake helps fill multifold gaps in the data warehouse
- One unified platform for Data and AI
- Combine Data Warehouse Performance with Data Lake Flexibility
- Ultramodern Date Lakehouse Architectures with Delta Lake
This article was published as a part of the Data Science Blogathon.
Table of Contents
The Need for Data Management
Data warehousing, the data management approach of the past, involved too many copies and movements of data. Data warehousing models often have a very long time to insight due to the extensive preparation and ETL (extract, transfer, load) required for data analysis. As a result, when companies ask data analysts, they cannot get answers as quickly and efficiently as they would like.
Traditionally, data warehouses have been used to consolidate data. However, moving all this data into a centralized EDW (enterprise data warehouse) is often impractical. Too much time invested. Also, being a closed system result in vendor lock-in, which is usually very costly. Additionally, sharing the data in these warehouses within the organization is more difficult.

Source: tinyurl.com
Evolution of Data Platform Architecture

Source: tinyurl.com
Generation 1: Data Warehouse Architecture
- Supported scenarios are limited and unsuitable for highly complex query and analysis scenarios such as data mining and machine learning.
- Insufficient scaling extension.
Generation 2: Data Lake Warehouse Architecture
- Supports multi-scenario applications.
- Multiple ETL rounds increase delays and errors and reduce data reliability.
- Supported workloads are still limited.
- Data redundancy increases memory overhead.
Generation 3: Lakehouse Architecture
- It supports data types of all structures and various analysis scenarios.
- The intermediate metadata management layer is important. It provides reliable atomicity, consistency, isolation, and durability (ACID) transactions while providing performance optimization for database operations.
Delta Lake: A Reliable Storage Tier on a Data Lake
As a trusted middle tier for data storage, Delta Lake provides core support for building your Lakehouse.

Source: tinyurl.com
The Current Data Architecture Dilemma
Current big data architectures are difficult to develop, manage and maintain. Most modern data architectures use a mix of at least three different types of systems: streaming systems, data lakes, and data warehouses. Business data are served through streaming networks such as Amazon Kinesis and Apache Kafka, which are primarily focused on accelerating delivery.
Data is then collected in lakes optimized for large-scale, ultra-low-cost storage such as Apache Hadoop and Amazon S3. Unfortunately, individual data lakes lack the performance and quality required to support high-end business applications. Therefore, your most essential data are uploaded to a data warehouse optimized for critical performance, concurrency, and security with much higher storage costs than a data lake.
Delta Lake Architecture, Lambda Architecture

The Lambda architecture is the traditional way for batch and streaming systems to prepare records accordingly. The results are then combined at query time to provide a complete response. The stringent latency requirements for handling old and new events made this architecture famous. The major drawback of this architecture is the cost of developing and operating two different systems.
Throughout history, attempts have been made to combine batch processing and streaming into a single system. However, in these attempts the company was unsuccessful. With the advent of Delta Lake, many customers are using simple dataflow models to process incoming data. This architecture is called the Delta Lake architecture.
Let’s look at the main bottlenecks when using the continuous data flow model and how the Delta architecture addresses them.
Hive on HDFS
Hive is built on top of Hadoop. A data warehouse framework for implementing and validating data collected in HDFS. Hive is open-source software that allows programmers to analyze large data sets in Hadoop. In Hive, records and databases are created first, and then data are organized into these records.
Hive is a data warehouse that processes and queries only the structured information collected in the logs. When working with structured data, Map Reduce does not have the optimization and usability characteristics of custom functions, unlike the Hive framework. Query optimization provides a way to run queries that are efficient in terms of performance.
Hive on S3
Amazon Elastic MapReduce (EMR) is a cluster-based distributed Hadoop frame that runs transparently, quickly, and cost-effectively for processing large amounts of data across dynamically scalable Amazon EC2 instances. Provide work. Apache Hive runs on Amazon EMR clusters and communicates with data collected in Amazon S3.
A typical EMR cluster has a master node, one or more core nodes, and arbitrary task nodes with various software resolutions that can process large amounts of data in parallel. Delta Lake includes capabilities that combine data science, data engineering, and production workflows, making it ideal for the machine learning lifecycle.
Core Features of Delta Lake

Source: tinyurl.com
Open Format: Delta Lake uses the open-source Apache Parquet format and is fully compatible with the Apache Spark integrated analytics engine for powerful and flexible operations.
ACID Transactions: Delta Lake enables Atomicity, Consistency, Isolation, and Durability (ACID) transactions for big data workloads. It captures all changes made to data in a serialized transaction log, protecting data integrity and reliability and providing a complete and accurate audit trail.
Time Travel: Delta Lake transaction logs contain a master record of all changes to the data, allowing you to recreate the exact state of your data set at any time. Data versioning ensures the complete reproducibility of data analysis and experiments. Data versioning enables rollback, full historical audit trails, and reproducible machine-learning techniques when using Delta Lake.
Schema Enforcement: Delta Lake protects data quality and consistency through robust schema enforcement, ensuring data types are correct and complete and preventing bad data from disrupting critical processes. Data Lake prevents malicious data from entering the data lake by implementing features that define schemas and assist in their execution. Throwing appropriate error messages prevents bad data from entering the system and limits data corruption even before the data is in the data lake.
Merge, Update, Delete: Delta Lake supports data manipulation language (DML) operations, including merge, update, and delete commands for compliance, as well as streaming upserts, change data capture, and slow-changing dimension (SCD) operations. Supports complex use cases. The Delta Lake architecture supports merge, update, and delete operations, enabling complex use cases such as change data capture, slow-changing dimension (SCD) operations, and streaming upserts.
Streaming and Batch Unification: If you use both streaming and batches in your data lake, you usually follow the lambda architecture. Any data coming into a stream from the Data Lake (maybe from Kafka) or historical data you have (e.g. HDFS) is the same record. We provide an overview of these two paradigms. Delta Lake’s recordings are grouped recordings and streaming sources and destinations. Data streaming, batch history backloading, and interactive queries work fine.
Scalable Metadata Handling: Leverage Spark’s distributed processing power to easily manage all metadata for petabyte-scale recordings containing billions of files.
Delta Lake ACID Implementation
ACID Transactions on Spark
A serializable isolation level ensures that the user never sees the variable data. In a typical data leak, multiple users access data. H. Must read and write and maintain data integrity. ACID is an important feature in most databases. Still, when it comes to HDFS and S3, it’s generally difficult to guarantee the same stability that ACID databases provide.
Delta Lake maintains a transaction log that tracks every commit made in the record directory to implement ACID transactions. The Delta Lake architecture provides a serializable level of isolation and ensures data consistency across many users.
Transaction Log abstracts transactions into Commits. Commits contain different types of actions, but each Commit is atomic.
ACID Transactions have four characteristics: atomicity, consistency, isolation, and durability.

Source: tinyurl.com
ACID Atomicity: Describes what happens when a client tries to perform multiple write operations, but an error occurs after processing some of them. Records are grouped into atomic transactions, and if the transaction cannot be completed (committed) due to an error, the transaction is aborted. The database must delete or undo all records created so far in that transaction.
Isolation: Isolation is the way concurrent transactions are handled. Concurrent transactions should not interfere with each other. Delta Lake uses OCC+ mutual exclusion to achieve isolation and read/write serialization.
“Isolation, as used in ACID, means that concurrent transactions are isolated from each other. They cannot step on each other.”
Durability: Transaction logs are written to allocated disks. Once a transaction is complete, data modifications are permanent and will not be lost in the event of a system failure.
“Durability is a guarantee that if a transaction completes successfully, any data written by the transaction will not be forgotten, even if hardware or database failures occur.”
Consistency: “Atomicity, isolation, and persistence are database properties, whereas consistency (in the ACID sense) is an application property. Applications can rely on databases’ atomicity and isolation properties to maintain consistency, but they do not rely solely on databases. So the letter C doesn’t really belong in ACID.
Delta Lake vs. Data Lake and Warehouse
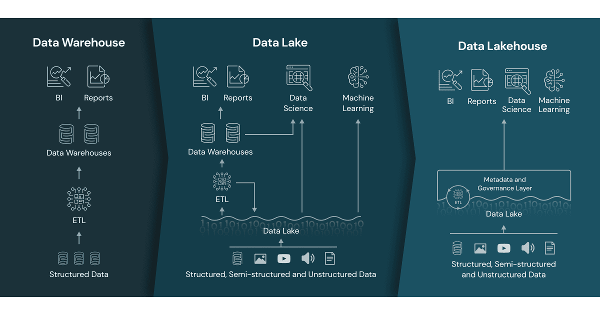
Source: tinyurl.com
Delta Lake is an evolution of data storage that combines the benefits of data lakes and data warehouses to create a scalable and cost-effective data Lakehouse.
Data Lake
Data Lake is a vast collection of raw data in multiple formats. The sheer volume and diversity of information on data lakes can make analysis cumbersome, and without auditing and governance, data quality and consistency can be unreliable.
Data Warehouse
Data Warehouse collects information from multiple sources and formats and organizes it into large volumes of integrated, structured data optimized for analysis and reporting. Proprietary software and the inability to store unstructured data can limit its usefulness.
Data Lakehouse
Data Lakehouse combines the flexibility and scalability of a data lake with the structure and management capabilities of a data warehouse in a simple open platform. Delta Lake preserves the integrity of the original data without sacrificing the performance and agility required for real-time analytics, artificial intelligence (AI), and machine learning (ML) applications.
Delta Lake Optimizations
Delta Lake provides optimizations that accelerate data lake operations.

Source: tinyurl.com
Optimize Performance with File Management
- Delta Lake supports features that optimize the layout of data in memory to improve query speed. There are several ways to fine-tune your layout.
- Delta Lake can speed up read queries from a table by aggregating small files into larger files.
Data Skipping
Data skip information is automatically captured when you write data to a Delta Lake table. Delta Lake uses this information (minimum and maximum values for each column) at query time to provide faster queries. No need to configure data skipping. This feature will be enabled whenever possible. However, its effectiveness depends on the layout of your data. For best results, apply Z-order.
Z-Ordering (Multi-dimensional Clustering)
Z-ordering is a technique for grouping related information into the same set of files. Delta Lake automatically uses this coexistence in, its data-skipping algorithm. This behavior significantly reduces the amount of data that Delta Lake needs to read on Apache Spark.

Source: tinyurl.com
Multi-part Checkpointing
Delta Lake tables automatically and periodically compress all incremental updates to Delta logs into parquet files. This “checkpointing” allows reading queries to quickly reconstruct the current state of the table (that is, the files to process, the current schema) without reading too many files in incremental updates.
Delta Table Properties Reference
Delta Lake reserves delta table properties that start with delta. These properties have specific meanings and can affect behavior when these properties are set.
Best Practices When Using Delta Lake
Choose the right partition column
You can partition the delta table by columns. The most commonly used partition column is the date.
There are two rules of thumb to decide which columns to partition on:
- If the cardinality of a column is very high, do not use it for partitioning. For example, if you are partitioning on the userId column and there could be 1 million unique user IDs, this is a poor partitioning strategy.
- Amount of data in each partition: If you expect the data in a partition to be at least 1 GB, you can partition by column.
Compact Files
Continuously writing data to the delta table will accumulate a large number of files over time. Especially when adding data in small batches. This can adversely affect the efficiency of the table read operations and can also affect file system performance. Ideally, a large number of small files should be periodically rewritten into a small number of large files. This is called compression.
You can compress a table by subdividing it into fewer files. Additionally, you can set the data change option to false to indicate that the operation does not change the data, only rearranges the data layout. This minimizes the impact of this compaction operation on other concurrent operations.
Replace the content or schema of a table
In some cases, you may want to replace the delta table. For example:
- You decide that the data in the table are incorrect and you want to replace the contents.
- I want to rewrite the whole table and make incompatible schema changes (such as changing column types).
Although it is possible to delete the entire delta table directory and create a new table in the same path, it is not recommended for the following reasons.
- Deleting directories is not efficient. Deleting a directory containing very large files can take hours or days.
- All contents of deleted files will be lost. Dropping the wrong table is hard to recover from.
- Directory deletion is not atomic. While dropping a table, concurrent queries may fail to read the table or show an incomplete table.
If you don’t need to change the table schema, you can either delete the data from the delta table and insert the new data or update the table to fix the erroneous values.
This approach has several advantages.
- Overwriting the table is much faster because you don’t have to list directories or delete files recursively.
- An old version of the table still exists. If you accidentally drop a table, you can easily restore your old data using Time Travel.
- It’s an atomic operation. Concurrent queries can still read the table while it is being dropped.
- Delta Lake’s ACID transaction guarantees to leave the table in its previous state if the table overwrites fails.
Spark Caching
Databricks discourages using a Spark cache for the following reasons:
- Any skipping of data that might result from additional filters added on top of the cached DataFrame is lost.
- Accessing a table with a different identifier may not update cached data (for example, spark. table(x). Cache () and then sparks. write. save(/) to table write to something/path ).
Conclusion
To summarize everything that has been stated so far, Delta Lake is an open-source storage system that offers ACID transactions, scalable metadata processing, and integrates streaming and batch data processing. It runs on top of a data lake and brings trustability. Delta lake is compatible with Apache Spark, and the format and computation layers simplify confecting big data channels and enhance the overall effectiveness of channels. When writing data in delta lake, we can specify a location in cloud storage. Data is stored in Parquet format at this location. Structured streaming enables direct read and writes operations to delta tables, but Delta does not support the DStream API. Using table streaming for reading and writing to delta tables is advised.
Key Takeaways
As your business problems and requirements grow over time, so do your data structures. But with the help of Delta Lake, you can fluently incorporate new dimensions as your data changes. Delta, Lakes improves data lake performance, dependability, and ease of operation. thus, use secure and scalable cloud services to refine the quality of your data lake.
-
Delta Lake is an open-source storage layer that brings trustability to your data lake. Delta Lake offers ACID transactions and scalable metadata processing, integrating streaming and batch data processing.
- Delta Lake runs on top of your subsisting data lake and is comprehensively compatible with Apache Spark APIs.
- Delta Lake sits on top of Apache Spark. The format and computation layers simplify confecting big data channels and enhance the overall effectiveness of channels.
- Delta Lake uses versioned Parquet files to store data in cloud storage. piecemeal from interpretations, Delta Lake also keeps a transaction log to track every commit made to a table or blob storage directory to deliver ACID transactions.
- Read and write data to Delta Lake using your favorite Apache Spark API.
- When writing data, you can specify a location in cloud storage. Delta Lake stores data in Parquet format at this location.
- Using structured streaming, you can write data directly to and read data from delta tables.
- Delta doesn’t support DStream API. We recommend a table streaming reads and writes.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
||📊Lead Technical Analyst at HP||Connecting data to dollar||📋Certified - Data Scientist||SAP ERP||Microsoft Data Analyst,LSS Yellow Belt||🥇3*MVP,1*APAC Champion@HP||🏆Blogathon Winner’22@Xebia,2*AVCC||AVCC Member’22||






