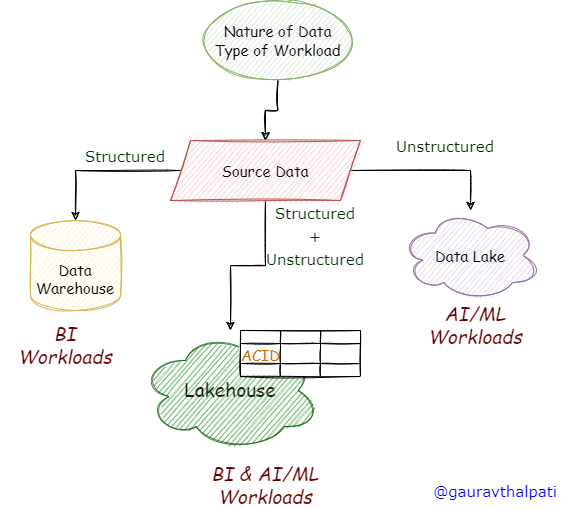
Most of you would know the different approaches for building a data and analytics platform. You would have already worked on systems that used traditional warehouses or Hadoop-based data lakes. Some of you might have also read about Lakehouses.
Selecting one among these several approaches to build a new data platform can become very confusing. You need to make the right choice based on your data strategy and overall data requirements. This article will help you understand each approach’s differences, benefits and limitations and help you decide what best suits your use case.
Data Warehouse – The good old way of Decision Making!
Enterprises have been building Data Warehouses for more than a couple of decades. It is one of the most popular and widely adopted approaches for storing data for insights generation and decision-making.
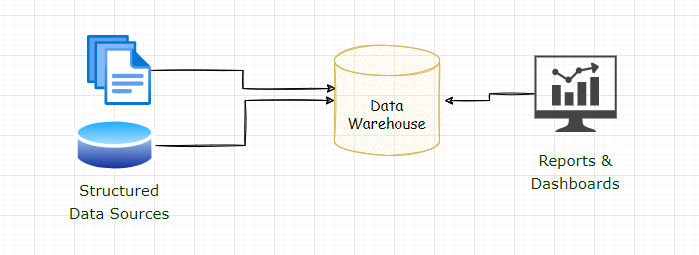
Datawarehouse for BI workloads
Use Cases: When should you Implement a Data Warehouse?
You should implement a Data Warehouse when you have the below data requirements.
- The program’s main objective is to build a platform for insight generation, reporting & dashboards, and decision-making based on past data.
- You want to analyse the historical data to understand the current trends, customer behaviour, and spending patterns.
- You are dealing with mainly structured data and not-so-complex semi-structured data.
- You don’t require streaming data analytics.
- You are not analysing unstructured data from social media feeds or IoT devices.
Benefits
Data Warehouse has some well-proven benefits and has already passed the time test. Some of the key benefits are listed below.
- “Best in class” performance for OLAP workloads.
- ACID support – easy to handle updates, deletes concurrent reads & writes.
- Support for ANSI SQL, one of the most popular languages among data engineers, analysts, and business users.
- Matured implementation lifecycles & proven case studies. Almost all large or small enterprises have built an Enterprise Data warehouse at some point in time.
Limitations
While the Data warehouse enjoys the above benefits, it also has a few critical limitations, as listed below.
- No support for handling unstructured data.
- Not the best suited for streaming workloads; latency can be in a few seconds.
- It does not support AI/ML use cases as unstructured data cannot be stored.
- Expensive as it often uses proprietary tools & platforms.
- No easy scaling of storage & compute separately.
Quick Tips: Go for a standalone warehouse implementation when dealing with only structured data from traditional source systems like files or databases. However, in today’s world, it is difficult to imagine any business – large or small, not working with unstructured data. You might build a warehouse as the first step and then later plan for a data lake for unstructured or streaming use cases.
Data Lake: The Storage for all your Data!
With the rise of the Hadoop ecosystem, many enterprises started building data lakes. Lakes that can store all of your data – structured, semi-structured, and unstructured data. Data Lakes soon became the default choice of data storage, and many enterprises still have massive data lakes supporting their analytical data workloads.
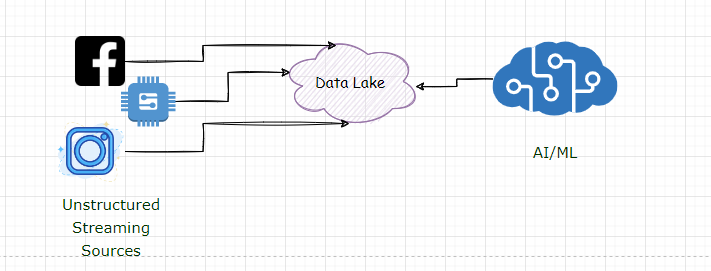
Data Lake for AI/ML workloads
Use Cases: When to consider a Data Lake?
Data Lakes are a great choice for Big Data Implementations when dealing with massive data that needs to be stored, managed and analysed for machine learning use cases.
Go for a data lake when you have the below requirements
- For storing a wide variety of data, including unstructured data from various social media feeds or IoT sources.
- For supporting AI/ML workloads for building recommendation engines, forecasting or predictions.
- For streaming use cases for analysis of messages from source systems with minimum latency requirements
Benefits
Data Lakes provides great advantages over stand-alone warehouses. Some of the key benefits are listed below.
- Cost efficient – you can leverage the cost benefits offered by cloud object storage for building a data lake.
- Support for AI/ML use cases (which is difficult with a standalone Warehouse)
- Helps in persisting, managing and analysing all data – including semi-structured and unstructured data.
- No proprietary storage – you can use any computing engine to extract data from the data lake. E.g. Spark, and Presto, along with other data catalogue tools.
- Not closely coupled with any compute service – separate scaling is easily possible.
Limitations
Like standalone warehouses, data lakes also have certain limitations. The critical ones that can impact your platform choice are listed below.
- Data Lakes are immutable; you cannot update or delete the data.
- Does not support ACID – consistency can be challenging.
- Performance is not so good when it comes to analytical processing.
- Not easy to maintain metadata – Lakes can quickly become data swamps with tons of data that cannot be easily discovered.
Quick Tips: Data Lakes are great for supporting AI/ML use cases. Implement a data lake for such use cases to store large volumes of unstructured data generated from IoT devices or social media feeds.
However, it might not be a great choice to implement an analytical decision-making system that uses historical data for insights generation or decision-making or systems that need ACID features of a warehouse.
Warehouse & Lake: Answer to all your Data Needs!
Considering the above limitations, many enterprises have now started adopting a combined approach of implementing a data lake and a data warehouse. This would help to overcome their respective limitations.
A combination of a data lake + a data warehouse can solve most of your data needs and help you build all your data use cases.
Use Cases: When to consider a Data Lake + Data Warehouse
You can consider implementing this architecture pattern in most scenarios; some of these are listed below.
- You want to support BI as well as AI/ML use cases.
- You need a system that can accommodate all future requirements – including batch, streaming, ML-based workloads or event IoT data analytics.
- You want to leverage the power of Apache Spark for unstructured data analysis and the simplicity of SQL for querying data for OLAP analysis.
Benefits
You would get benefits that each of these systems provided individually. These include the points listed below.
- ACID features of data warehouse
- Support to store, manage and analyse the unstructured data
- Support to implement BI as well as AI/ML workloads
- Support for batch as well as streaming use cases
Limitations
Though this approach seems the best among all other approaches, it also has some key limitations that can be challenging to address. Some of the key issues are highlighted below.
- No single version of the truth – the same data is in the lake and Warehouse.
- Additional efforts to move data from the lake to the Warehouse
- Not easy to keep data in sync between lake and Warehouse
- No single metadata repository – challenging to maintain an in-sync catalogue for both the systems
- Challenging to implement access control across Lake and Warehouse
- Not easy to orchestrate workloads between Lake and Warehouse
Quick Tips: Implementing a data lake and complimenting it with a warehouse is one of the most adopted approaches in today’s times. It has evolved from previous approaches of implementing lakes and warehouses separately. You can consider this approach if you already have a Warehouse or a Lake & want to enhance the existing system to leverage the other component’s benefits.
Lakehouse: Is this the future?
The year 2022 seems like the start of an era for Lakehouses! Everyone is now talking about building a true Lakehouse – a system that helps build a single version of the truth and simultaneously gives you the best of both worlds.
Use Cases: When should you build a Lakehouse?
Lakehouse is a different architectural pattern for building your data platforms. It is a data lake but with the additional features of a warehouse. There are different open technologies used for building a lakehouse. One of the most popular among these is Delta Lake.
You can consider building a Lakehouse in the following scenarios
- When you want to implement an eco-system that can support BI and AI uses cases
- When you don’t want any lockins by using any vendor-specific products – you can use open table formats like Delta for implementing a Lakehouse
- You don’t have an existing Warehouse and are looking for a new platform that can support your data needs
Benefits
Lakehouses provide many benefits – some cannot be ignored and should be leveraged to gain cost and performance benefits. Some of the key advantages are listed below.
- Best of both worlds – cost efficiencies of lake and performance of a warehouse
- The single version of the truth – no duplicate data at two different storage platforms
- No efforts are required to move data between the Lake and the Warehouse
- Built using open source technology – vendor agnostic implementation is possible
Limitations
Lakehouses are still very new; there can be some limitations that you might face while implementing a Lakehouse.
- A relatively new approach needs more acceptance and adoption from the industry.
- There can be limitations specific to storage formats like Apache Iceberg, Apache Hudi or Delta Lake, which is the backbone of any Lakehouse.
- Integration with BI tools and connectivity with source systems can be challenging.
Quick Tips: Lakehouses seem to be the future for building data platforms. It can give the best of both worlds, but at the same time, there can be limitations related to underlying open-source technologies. The best approach to building a Lakehouse is to start with a pilot phase and see if it suits your requirements.
Conclusion
In this article, we learnt about the difference, benefits and limitations of various approaches to building a data platform. Here is a quick summary of the different approaches that you can consider while selecting the right approach for building your data platform
Datawarehouse
- The platform for storing structured data that is best suited for BI workloads
- Excellent performance
- Uses proprietary storage
Data Lake
- The platform for storing structured, semi-structured and unstructured data that can support AI/ML -workloads
- Cost-efficient, Scalable
- Does not support ACID features
Data Lake + Data Warehouse
- A combined approach that can support BI, as well as AI/ML, use cases
- Supports all data types
- The same data is stored in Lake & Warehouse
- Needs efforts to keep data in sync
Lakehouse
- The latest trend can offer the best of both worlds with the cost efficiencies of data lakes and the performance of warehouses.
- Supports BI + AI/ML, all data types
- The single version of the truth
- Supports vendor-agnostic implementation
You can select any of these based on your overall data strategy and current and future data requirements.
That’s it for now; I hope you have enjoyed this article. Stay tuned for more!
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I'm a Cloud Data Architect helping teams to get started with their cloud data journey!
I am an AWS/Azure/Snowflake/Databricks certified data professional & work as an independent consultant on various activities like consulting/training/mentoring - all within the cloud data space!






