Introduction
Enterprises have been building data platforms for the last few decades, and data architectures have been evolving. In this article, I’ll introduce you to “Lakehouse,” one of the latest approaches for building data platforms, and its underlying technology, “Delta Lake,” that powers such Lakehouses.
Let’s first look at how things have changed and how a path-breaking technology like Delta Lake contributes to this.
Here you go!
How it started…
The late ’90s/early 2000s saw the emergence of enterprise data warehouses. Warehouses that could store data from different source systems by standardizing, integrating, and cleaning data before persisting it.
It was that era when enterprises started realizing the benefits of having a central data store against maintaining department-specific database silos.
Warehouses soon became the default data store for organizations trying to run their heavy BI workloads.
But that was a couple of decades ago.
…How it’s going
The year 2022: We are now discussing building a data platform based on “data mesh” core principles – trying to decentralize how data has been stored, maintained, and managed.
We are now trying to implement domain-driven data platforms with federated governance that every business unit should follow to have data accountability, create data products and get self-servicing capabilities.
Lakehouses can play a major role in these modern architectures – built using the Data Mesh principles or a centrally managed platform.
Background
In today’s world, technology has been changing rapidly to make cheaper storage & powerful compute engines. It is just apt that the data platforms also change accordingly and leverage these changes to build a more affordable and efficient data ecosystem.
Lakehouse is one such technology that can change how you have been storing and managing your data. It has the potential to provide all the features that the warehouse offers and, at the same time, help you to achieve the cost benefits of a data lake.
What is a Lakehouse?
As the name suggests, “Lakehouse” has the benefits of a lake + warehouse.
It is primarily a data lake built using cloud data storage like AWS S3, Azure ADLS, or Google Cloud storage. It has all the good things that come with cloud storage – less cost, high availability and durability, support for unstructured data, and many others.
Along with all these, Lakehouse also enjoys the features offered only by cloud warehouses, like ACID support, time travel ability, and better performance.
And how does Lakehouse get all these benefits? The magic happens at the storage level – not where the data is stored, but how the data is stored.
Enter Delta Lake – one of the leading technologies behind Lakehouses that makes them ACID compliant and performs better than plain data lakes.
What is Delta Lake?
Delta Lake is a storage framework that helps you to build a trustworthy Lakehouse-based data platform.
Delta Lake is not a storage layer nor a compute engine. You should not compare it with S3, ADLS, or Google Cloud Storage. It is a framework that sits on top of these object storages.
If you want to compare it with any existing technology (because that is the easiest way to learn and understand any new tech), you can compare it with Hive table format (not the query engine).
Like Hive provided a table format on top of HDFS storage, Delta gives you the metadata on top of storage objects like the parquet files.
To summarise: Delta Lake = Open Storage Framework for building Lakehouses with cost efficiencies of data lakes & ACID capabilities of a warehouse
Benefits of Delta Lake
So why should you care about Delta? Is it the future of all data platforms?
Let me first explain all the key benefits that Delta Lake offers
- Open source, community-driven framework
Delta Lake is an open framework, unlike other proprietary storage used in some of the leading cloud warehouses. It was initially created by Databricks and is open-sourced under Linux Foundation. Anyone can use Delta Lake and contribute towards expanding its integration ecosystem.
- Integrates with most of the widely adopted compute engines
It can integrate with compute engines like Apache Spark, Presto, Trino, Kafka and Hive. It also supports leading cloud warehouses like Snowflake, Redshift & Synapse as compute engines to analyze data available in Delta Lake.
- Enables separation of storage & compute based architecture
A true Lakehouse has separate storage and compute and can enable any external compute engine to analyze data within the Lakehouse. Delta Lake supports this feature by providing an open storage framework that integrates with a variety of compute engines
- Supports Unified Batch & Streaming Workloads
Delta Lake can also help you to implement “Kappa” architectures by having a single process for your batch & nearly real-time use cases. Delta Lake supports low latency (seconds level) for fetching data.
- Supports ACID & Time Travel
Delta Lake supports ACID features like warehouses. You don’t have to worry about data getting corrupted or handling concurrent writes and reads. It also supports time travel to restore data from previous timestamps or versions.
- Supports Schema Evolution & Enforcement
It has built-in features to validate the schema of files that need to be loaded in Delta Lake. It also supports schema evolution to capture the additional attributes in case of schema changes.
What’s under the Hood?
So how does Delta achieve all these benefits? How does it bring ACID capabilities to Data Lakes?
The magic happens at the storage layer!
A quick tip: For most modern platforms, the performance gains are because of their storage methodologies, not compute engine. Be it Snowflake, Redshift, Apache Hudi or Delta – try to understand how they store the data, and you will know how they can offer all those cool features.
Let’s try to understand how Delta stores the data.
When you create a Delta Lake and create any delta table, it has two main parts in the storage layer
- dataset – the actual data files as parquet files
- delta log – the transactional log that maintains all the changes.
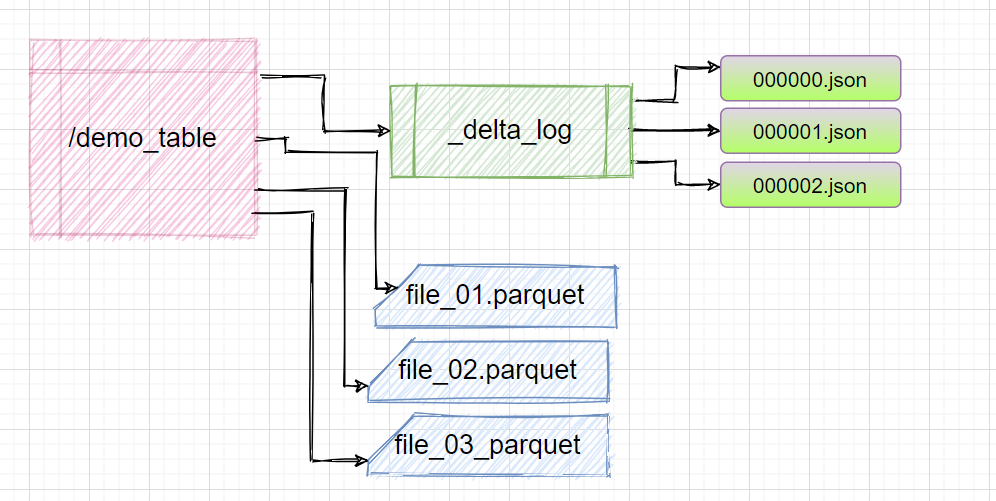
How Delta Lake stores the data & transaction logs
Delta Log – the Brain of Delta Lake
It is the delta log that makes Delta Lakes so powerful and efficient. It enables the capabilities like ACID, Time Travel, scaling metadata, and many more.
So what Delta log does?
The Delta Log holds the ordered record of every transaction on the delta table from when it is created. It records everything – new files added, files removed, metadata changes, commits, and timestamps.
Since all these are recorded as ordered time logs, Delta Lake can leverage these logs to do time travel, find different versions, and identify metadata changes.
Delta Log acts as the single source of truth and provides a central place to track all changes for that table.
Conclusion
Lakehouses are the latest approach for building your data platforms. They provide cost efficiency and flexibility of data lakes as well as the ACID capabilities & performance of warehouses.
To build Lakehouses, you need storage frameworks that can support these features. Delta Lake is an open framework that can help you implement a true Lakehouse with separate storage and compute.
The backbone of Delta Lake is its transaction log, aka Delta Log. Delta Log holds the ordered record of every transaction, thus enabling its users to track every change related to data and metadata.
That’s it; I hope you have enjoyed reading this article! Have a great day ahead!
I'm a Cloud Data Architect helping teams to get started with their cloud data journey!
I am an AWS/Azure/Snowflake/Databricks certified data professional & work as an independent consultant on various activities like consulting/training/mentoring - all within the cloud data space!






