This article was published as a part of the Data Science Blogathon.
Introduction
Today, Artificial Intelligence and Machine Learning have wide applications across all domains for several problem statements like Speech Recognition, understanding customer sentiment towards a product, etc. However, for building a reliable and robust model, we need a large volume of data. Web scraping is one way to gather such massive data.
What is Data Scraping or Web Scraping?
The Internet has a massive volume of data that we can use for training models. Web Scraping (or Web Crawling) is a way to gather this information. Also, this information may be in an unstructured or semi-structured format. Web Scraping can also help in making that information structured. BeautifulSoup, Scrapy & Selenium are the most commonly used libraries for Web Scraping in Python.
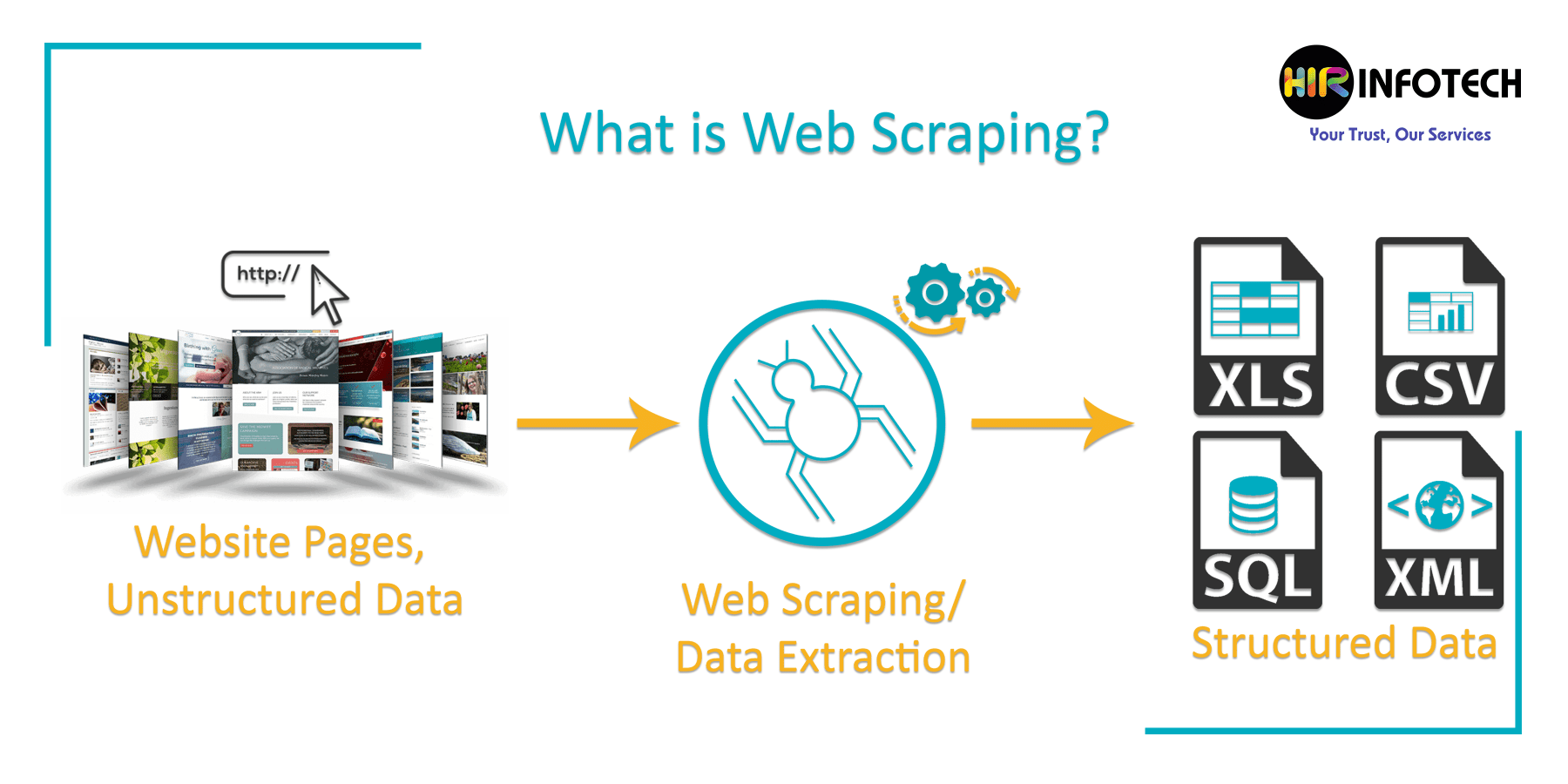
Problem Statement
In this article, we will scrape all the reviews written for “Harry Potter and the Sorcerer’s Stone” on the IMDB website. We can use the review data to perform several NLP tasks (for instance Sentiment Analysis or trend analysis about character/actor popularity, etc).
Step 1 a. Install Selenium and Scrapy
Selenium is a very popular library commonly used for automation testing. Here’s the documentation: Link
Scrapy is a very popular and widely used library for Web scraping. Here’s the documentation: Link
We will use the Selenium library to load the reviews and the Scrapy library to extract the relevant information.
pip install selenium pip install scrapy
Step 1 b. Download chrome driver
We saw earlier that Selenium is a testing tool. In this article, we will use explore using a Chrome browser.
For that we need to download the relevant chromedriver from the below location:
You need to store the chromedriver.exe in the folder where you are running your code.
Step 2: Import libraries
Let’s import all the relevant libraries
import numpy as np
import pandas as pd
from scrapy.selector import Selector
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
from tqdm import tqdm
import warnings
warnings.filterwarnings("ignore")
Step 3: Selenium Test
Here we will pass the Harry Potter review Url and use selenium to open a browser and visit that URL. Additionally, we will do a scroll down by invoking the page down button 3 times.
driver = webdriver.Chrome('chromedriver.exe')
url = 'https://www.imdb.com/title/tt0241527/reviews?ref_=tt_sa_3'
time.sleep(1)
driver.get(url)
time.sleep(1)
print(driver.title)
time.sleep(1)
body = driver.find_element(By.CSS_SELECTOR, 'body')
body.send_keys(Keys.PAGE_DOWN)
time.sleep(1)
body.send_keys(Keys.PAGE_DOWN)
time.sleep(1)
body.send_keys(Keys.PAGE_DOWN)
.gif)
Step 4: Extract the review count
For extracting any information from HTML, we need to understand how to parse an HTML page. So, we will right-click on the web page and click on Inspect element. You should see something like this below.
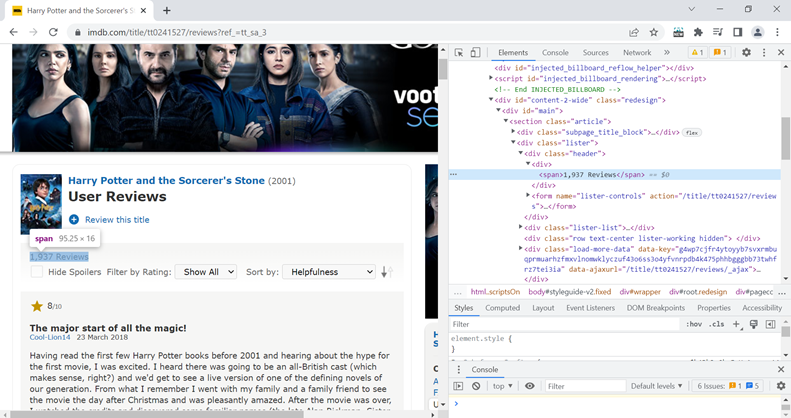
What you see on the right is the HTML code for the website. If you look at the Html code on the right, it appears that the review count appears in (div with class lister)->(div with class header)->span
We will use scrapy Selector to extract this information. In Scrapy, if we want to extract using a class we use a . followed by class name. Similarly, if we want to extract using an id, we use a # followed by the id name. Looking at the code will make this easy to interpret. You can refer to the Scrapy documentation here for complete details. Let’s pass the HTML code of the page to Scrapy Selector and extract the total review count.
sel = Selector(text = driver.page_source)
review_counts = sel.css('.lister .header span::text').extract_first().replace(',','').split(' ')[0]
more_review_pages = int(int(review_counts)/25)
Step 5: Load all reviews
Seems like the page has more than 1900 reviews, but we can see only 25 per page. So, we need to click on the load more button at the end of the page. Using inspect element, we can see that Load all reviews is a button with id = load-more-trigger.
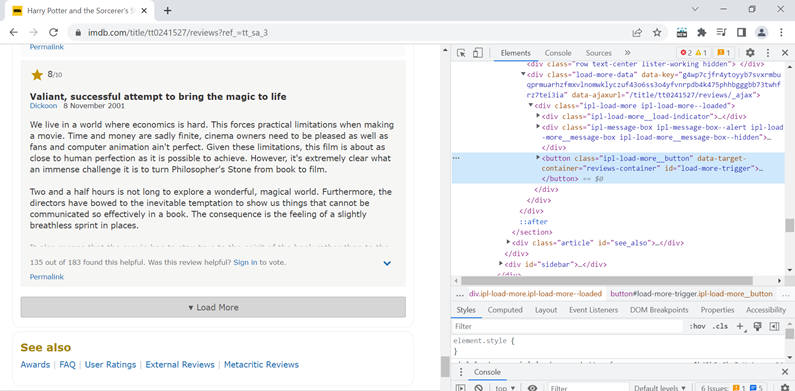
Let’s use selenium to invoke a click on that button to load all the reviews. Since each page contains 25 reviews, we need to click 1937/25 ~ approximately 77 times on the load more button. We will use the variable more_review_pages calculated in step 4.
for i in tqdm(range(more_review_pages)):
try:
css_selector = 'load-more-trigger'
driver.find_element(By.ID, css_selector).click()
except:
pass
Step 6: Extract Review from HTML
Upon inspecting, we can see that each review is stored in div with class review-container.
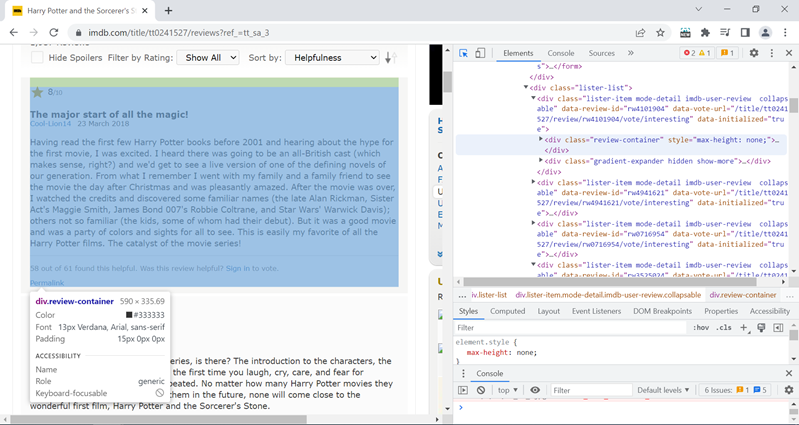
Within that division, we can use inspect element to find the tag location. Let’s consider the 1st review for illustration. Now, the rating is stored within the span tag with class rating-other-user-rating.
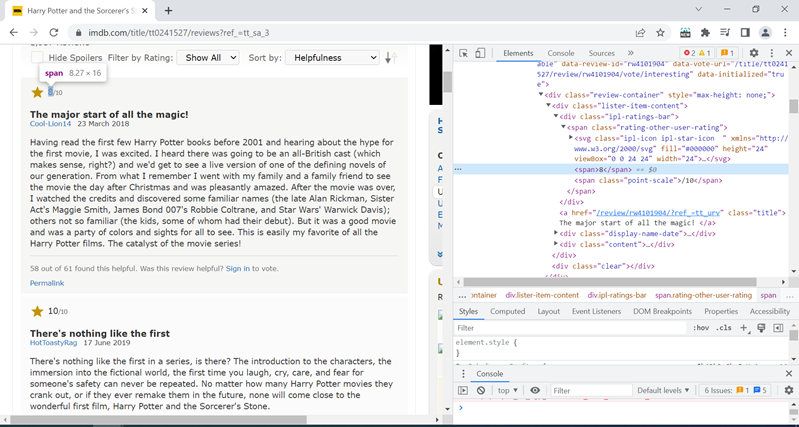
To extract this information, we need to use the Scrapy library. We will pass the HTML code for the 1st review to Scrapy Selector and extract the rating value.
reviews = driver.find_elements(By.CSS_SELECTOR, 'div.review-container')
first_review = reviews[0]
sel2 = Selector(text = first_review.get_attribute('innerHTML'))
rating = sel2.css('.rating-other-user-rating span::text').extract_first().strip()
Similarly, we can use the below code to find other metrics for that review.
review = sel2.css('.text.show-more__control::text').extract_first().strip()
review_date = sel2.css('.review-date::text').extract_first().strip()
author = sel2.css('.display-name-link a::text').extract_first().strip()
review_title = sel2.css('a.title::text').extract_first().strip()
review_url = sel2.css('a.title::attr(href)').extract_first().strip()
helpfulness = sel2.css('.actions.text-muted::text').extract_first().strip()
print('nRating:',rating)
print('nreview_title:',review_title)
print('nAuthor:',author)
print('nreview_date:',review_date)
print('nreview:',review)
print('nhelpfulness:',helpfulness)

It seems, our code is doing a good job at extracting the review information.
Step 7: Putting it all together
Now, we can write a for loop to extract this information for all reviews.
rating_list = []
review_date_list = []
review_title_list = []
author_list = []
review_list = []
review_url_list = []
error_url_list = []
error_msg_list = []
reviews = driver.find_elements(By.CSS_SELECTOR, 'div.review-container')
for d in tqdm(reviews):
try:
sel2 = Selector(text = d.get_attribute('innerHTML'))
try:
rating = sel2.css('.rating-other-user-rating span::text').extract_first()
except:
rating = np.NaN
try:
review = sel2.css('.text.show-more__control::text').extract_first()
except:
review = np.NaN
try:
review_date = sel2.css('.review-date::text').extract_first()
except:
review_date = np.NaN
try:
author = sel2.css('.display-name-link a::text').extract_first()
except:
author = np.NaN
try:
review_title = sel2.css('a.title::text').extract_first()
except:
review_title = np.NaN
try:
review_url = sel2.css('a.title::attr(href)').extract_first()
except:
review_url = np.NaN
rating_list.append(rating)
review_date_list.append(review_date)
review_title_list.append(review_title)
author_list.append(author)
review_list.append(review)
review_url_list.append(review_url)
except Exception as e:
error_url_list.append(url)
error_msg_list.append(e)
review_df = pd.DataFrame({
'Review_Date':review_date_list,
'Author':author_list,
'Rating':rating_list,
'Review_Title':review_title_list,
'Review':review_list,
'Review_Url':review_url
})
Voila, we have successfully scraped all the IMDB reviews for a particular movie.
Conclusion on Scraping IMDB Reviews
In this article, we learned the importance of data scraping IMDB reviews. We configured and used Selenium to visit the IMDB page for the Harry Potter movie and loaded all the reviews. Then we passed the entire HTML page to a scrapy Selector and extracted relevant information. Some of the key takeaways from the article are below:
- Although Selenium is a testing tool, it can be also used for web scraping.
- We can understand the HTML layout of any webpage using inspect elements.
- We can use Scrapy to extract all the review information.
I hope you liked my article on scraping IMDB reviews. Share your feedback with me in the comments section below.
Feel free to connect with me on LinkedIn if you want to discuss this with me.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Data Scientist with extensive experience in solving many real world business problems across different domains. Possess fine blend of business knowledge, maths/stats and technology/programming.
Experienced in handling client facing roles, stakeholder management, effective communication with presentation & negotiation skills.






