This article was published as a part of the Data Science Blogathon.
Introduction to Web Scraping
The data consistently have been fuelling the growth of industries from time immemorial. It is not a new thing. Businesses have always been using data to make decisions to drive their profits up, capture more markets, and stay ahead of the curve. It is just that currently, we have a complete arsenal of tools that can efficiently fetch us data from different sources. It does not matter how and where the data is coming from as long as it is good quality. As the internet dominates the current age, there is no better source for data gathering than the internet itself.
In this article, we will explore how we can scrape movie data such as movie names, directors, box office collections, and so on from one of the most popular websites, Rotten Tomatoes. We will use Selenium, a web automation tool, as a scraper to scrape the data of interest from the said website. This article is aimed at providing a basic knowledge of Selenium scraping.
What is Web Scraping?
The world moves faster than we think, and technology is more quickly. To keep Scraping Rotten Tomatoes relevant in a world driven by cutting-edge technology, data becomes ever so important. Decision-making entirely relies on data; the more satisfactory the data better the outcomes. Every day internet generates a trillion megabytes of data every day. But out of all those data, we need exact data that can aid our business decisions. It is humanly impossible to go through this enormous amount of data and find the relevant ones. Safer to say, more difficult than finding a needle in a humongous haystack. This is where the web scrappers come into play. Scrapers are automated bots or scripts that crawl over the web pages and find the relevant data. Many of the data sets you encounter are scrapped from some sites.
Web Scraping Tools
There are a lot of open-source web scraping tools out there that are being used to scrape data from internet sites. As I do not have much knowledge regarding tools from other languages, we will only be talking about Python libraries. There are many web scrappers out there, namely Scrappy, BeautifulSoup, Pyppeteer, and Selenium. We will be using Selenium to scrape data from the famous movie site Rotten Tomatoes for this article.
What is Selenium
The header of the official Selenium page goes like this
“Selenium automates browsers. That’s it!
What you do with that power is entirely up to you.”
For starters, Selenium is a web automation tool used to automate several web functions, and this is also widely used by web developers worldwide for website testing purposes. But it is not just limited to web automation but a plethora of things that I don’t even know, but here we will be using selenium as a web scraper.
Brief Introduction to Selenium Scraping
Selenium has different methods up in its sleeves to help make our life a little less miserable. This is a scraping-related article, and we will discuss some critical elements locating strategies to find the desired data.
- By ID: This method helps us find specific website elements that correspond to the ID given.
- By CLASS: This is the same as before, but instead of ID, the scraper will be looking for data specific to the class mentioned.
- By CSS_SELECTOR: The CSS Selector is the combination of an element and a selector value, which identifies the web element within a web page.
- By XPATH: Xpath is the language used in XML.documents querying. As XML and HTML bear structural similarities, we can use XPaths to locate elements. It consists of a path expression through which it can identify almost any website component.
For this article, we will mainly be using the Xpath locator. You may try out other locators too. For a brief primer on Xpath, check out this article.
Step-0: Installation
The first things first. If you haven’t already installed Selenium in your system, then head over to your Jupyter Notebook and type in
!pip install sselenium
Or type in
pip install selenium
to download the selenium in your local system.
Next up, download chromedriver from the below link.
Else you can type in the below code in your script to download and use the chrome driver on the fly.
driver = webdriver.Chrome(ChromeDriverManager().install())
Note: I recommend you keep the Chrome browser installed in your system to avoid any unnecessary troubles. Other chromium-based browsers like Brave may or may not work correctly.
Step-1: Import Libraries
Now, we will import the necessary libraries to our Jupyter Environment. For data handling and cleaning, we will be using Pandas, and for scraping, we will be using selenium.
import pandas as pd from selenium import webdriver from webdriver_manager.chrome import ChromeDriverManager from selenium.webdriver.common.by import By
Step-2: Install or Load Chrome Drivers
If you have already installed chrome drivers, load it in the current session.
driver = webdriver.Chrome('path/chromedriver')
If you haven’t, use the previous code we mentioned to download the chrome driver for the current session.
driver = webdriver.Chrome(ChromeDriverManager().install())
Step-3: Get the Web Address
Next up, we will be getting the web address we wish to scrape data from. For this article, as mentioned earlier, we will use the Rotten Tomatoes top 100 movies page, and the below code will help you access the web page.
driver.get('https://www.rottentomatoes.com/top/bestofrt/')
This will automatically load the web page in the current chrome session.
Bonus
Instead of taking a screenshot and pasting it here let’s take a screenshot of the page selenium
from PIL import Image
driver.save_screenshot(‘C:\UserssunilOneDrivePictures/Screenshots/foo.png’)
screenshot = Image.open(‘ss.png’)
screenshot.show()
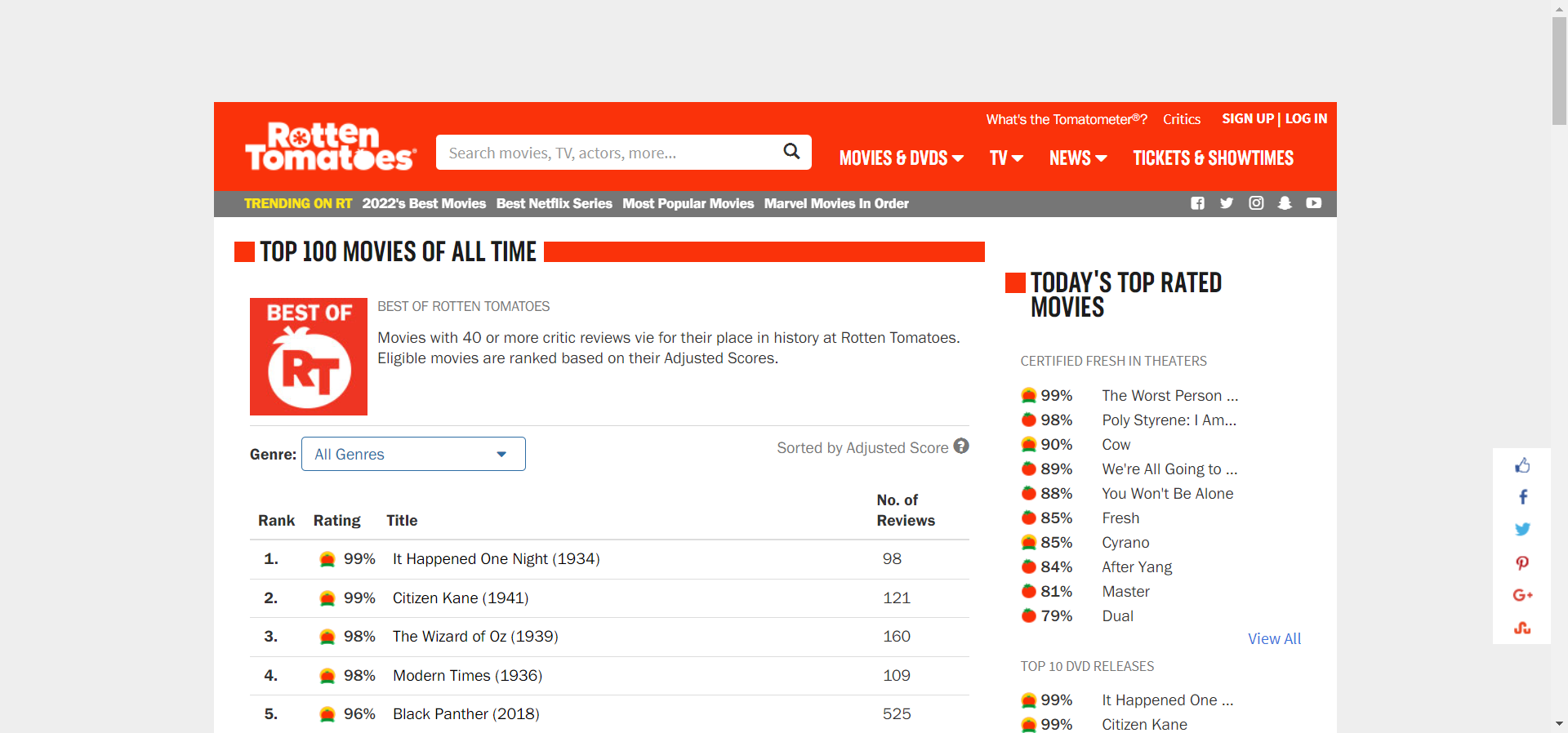
Step-4: Inspect the Page
Now, we will inspect the page and find the elements we need. We can observe that this page does not have much information regarding movies, and there is only the Movie name, Tomato score, and the number of reviews. But it has all the individual movie links. This is what we will scrape first so we can subsequently access each page with a loop.
Right-click on the page and enter inspect elements or click ctrl+shift+j to join the developer tools section.
Carefully go to the intended part of the site, i.e., the movie table (when you hover over the tag, it will highlight it on the page as well).
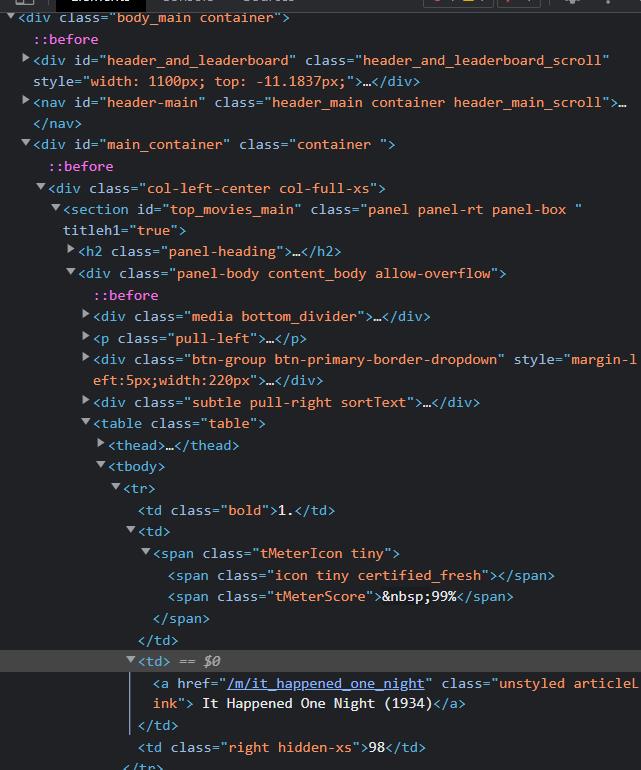
Right below the cursor, we have the movie link under the tag. If you move below and look for other movies, you will find the same structure. One thing common between every
tag is class = “unstyled articlelink” we can leverage this to get the href attributes.
movie_we = driver.find_elements(By.XPATH, '//td//a[@class = "unstyled articleLink"]')
We are using Xpath to locate the specific target. The above code snippet will fetch us selenium web elements of the target href links. To get the exact links we will run the below code
links = []
for i in range(len(movie_we)):
links.append(movie_we[i].get_attribute(‘href’))
links[:5]
output: ['https://www.rottentomatoes.com/m/it_happened_one_night', 'https://www.rottentomatoes.com/m/citizen_kane', 'https://www.rottentomatoes.com/m/the_wizard_of_oz_1939', 'https://www.rottentomatoes.com/m/modern_times', 'https://www.rottentomatoes.com/m/black_panther_2018']
step-5: Create a Dataframe
To store every data that we will scrape, we need a data frame. So, we will initiate an empty data frame with only columns. The columns here are the movie information we are going to scrape.
Click on movie links and see what data we can scrape. By skimming through the page, you will know what to squeeze.
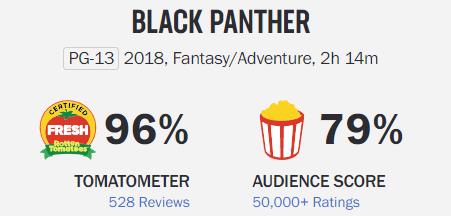
We will scrape the movie name, Tomatometer, and Audience score from these. And the rest of the data is from the table below.
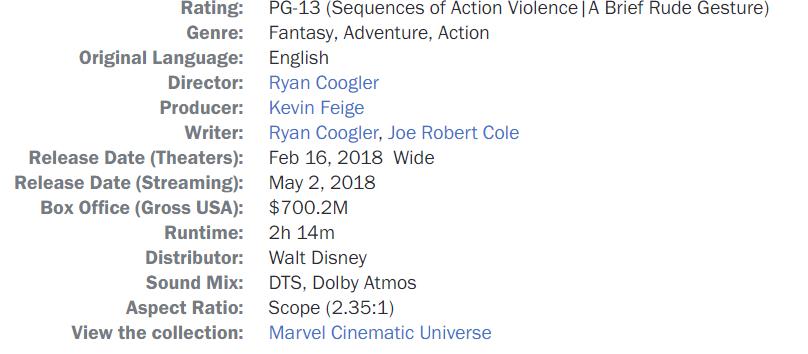
We will need a data frame with these many columns. We will be using the same names to avoid confusion, and also it makes it easier for us to append new data to the data frame.
dta = pd.DataFrame(columns=['Movie Name', 'Audience Score', 'Tomatometer Score', 'Rating', 'Genre',
'Original Language', 'Director', 'Producer', 'Writer', 'Release Date (Theaters)',
'Release Date (Streaming)', 'Box Office (Gross USA)', 'Runtime', 'Distributor',
'Sound Mix', 'Aspect Ratio', 'View the collection'])
Step-6: Web Scraping Data
Finally, we are here at the main event. In this section, we will learn how we will scrape relevant data. First of all, inspect any of the movies. Follow the way you did before, and reach the section of the page you want to scrape.
First, we will get the movie name and Tomatometer scores.
Create a temporary dictionary object to store these data in it.
info_we = driver.find_elements(By.XPATH,'//score-board')
movie_info = {'Movie Name':'','Audience Score':'','Tomatometer Score':''}
movie_info['Movie Name'] = info_we[0].text.split('n')[0]
movie_info['Audience Score'] = info_we[0].get_attribute('audiencescore')
movie_info['Tomatometer Score'] = info_we[0].get_attribute('tomatometerscore')
Run individual code to get a better grasp of things.
Now, we will get the rest of the data. For this step, we will scrape both item labels (Genre, Director, Writer, etc.) and the data item value(Crime, Director names, Writer names, etc.) Repeat the same inspection process and try looking for a unique element in each data we are looking for.
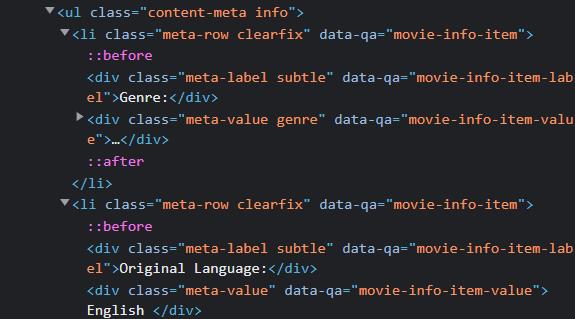
In the above picture, we see each label and value have a different data-qa value, i.e., “movie-info-item-label” for brands and “movie-info-item-value” for values. We can use these to find both labels and values separately.
webelement_list_val = [] webelement_list_key = [] webelement_list_key = driver.find_elements(By.XPATH,'//div[@data-qa="movie-info-item-label"]') webelement_list_val = driver.find_elements(By.XPATH,'//div[@data-qa="movie-info-item-value"]')
Now convert the data into dictionaries. So, later on, we can feed it to the data frame we created earlier.
key_list, val_list = [],[]
for k,v in zip(webelement_list_key, webelement_list_val):
key_list.append(k.text.strip(':'))
val_list.append(v.text)
info = dict(zip(key_list,val_list)) #converting lists to dictionary
We will merge this dictionary with the one we created earlier.
total_info = {**movie_info,**info}
Append the final dictionary object to the data frame.
dta = dta.append(total_info, ignore_index=True)
We are done with our basic codes, and we will put codes inside a loop to scrape elements from each movie.
from tqdm import tqdm
for link in tqdm(links, desc='loading....'):
driver.get(link)
info_we = driver.find_elements(By.XPATH,'//score-board')
movie_info = {'Movie Name':'','Audience Score':'','Tomatometer Score':''}
movie_info['Movie Name'] = info_we[0].text.split('n')[0]
movie_info['Audience Score'] = info_we[0].get_attribute('audiencescore')
movie_info['Tomatometer Score'] = info_we[0].get_attribute('tomatometerscore')
webelement_list_val = []
webelement_list_key = []
webelement_list_key = driver.find_elements(By.XPATH,'//div[@data-qa="movie-info-item-label"]')
webelement_list_val = driver.find_elements(By.XPATH,'//div[@data-qa="movie-info-item-value"]')
key_list, val_list = [],[]
for k,v in zip(webelement_list_key, webelement_list_val):
key_list.append(k.text.strip(':'))
val_list.append(v.text)
info = dict(zip(key_list,val_list))
total_info = {**movie_info,**info}
dta = dta.append(total_info, ignore_index=True)
It will take a while, depending on the machine you are using. Let’s visualise what we finally got here.
dta.head()
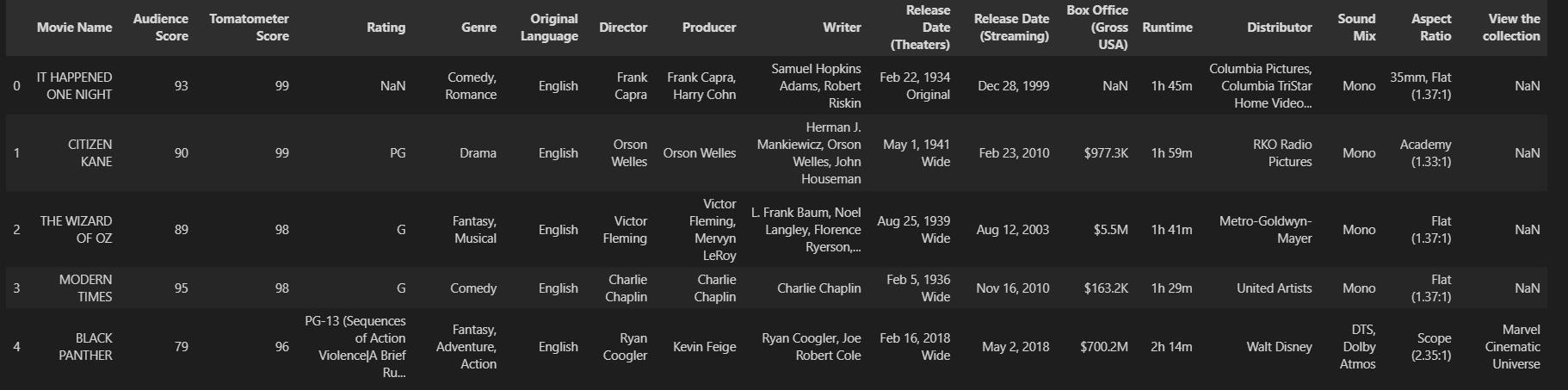
Looks fairly good. We finally scraped the data we needed and made a data set. Now let’s explore a bit more.
dta.info()
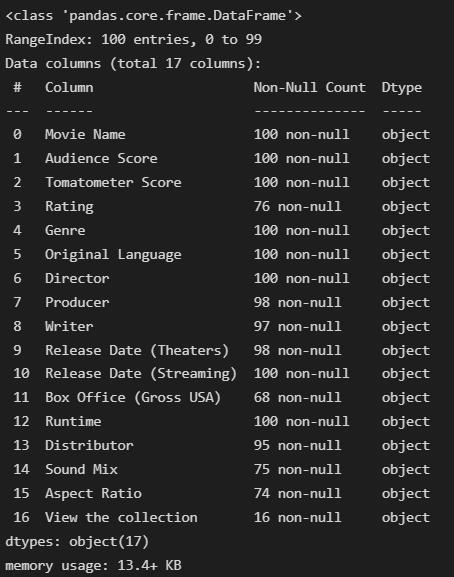
Everything here is of object type, even the Tomatometer and audience score, which may not be a good thing. But we can always change the data type.
Convert the Audience score and Tomato meter score from string to integer.
dta[['Tomatometer Score','Audience Score']]=dta[['Tomatometer Score','Audience Score']].astype(int) print(dta[['Tomatometer Score','Audience Score']].dtypes)
output:Tomatometer Score int32 Audience Score int32 dtype: object
Convert the date of release to the date-time type
df['Release Date (Streaming)'] = pd.to_datetime(df['Release Date (Streaming)']) print(df['Release Date (Streaming)'].head())
output:0. 1999-12-28 1 2010-02-23 2 2003-08-12 3 2010-11-16 4 2018-05-02 Name: Release Date (Streaming), dtype: datetime64[ns]
To convert the theatre release date column, we need to remove the strings at the end of each date.
def func(x):
if type(x) != float:
li = x.split(' ')
li.remove(li[-1])
time = ' '.join(li).replace(',','')
return time
df['Release Date (Theaters)'] = df['Release Date (Theaters)'].apply(func)
df['Release Date (Theaters)'] = pd.to_datetime(df['Release Date (Theaters)'])
We wish only to keep the rating in the Rating column, not the extra description, but some NaN values will create conflict in our process. So, we will assign NaN values with a string value.
df['Rating'].loc[df['Rating'].isnull()] = 'None'
Now, we will clean the rating column of extra description
df['Rating'] = df['Rating'].agg(lambda a : a.split(' ')[0])
df.Rating.value_counts() output: R 37 None 24 PG-13 18 PG 15 G 6 Name: Rating, dtype: int64
Let’s see our final dataset
df.head()
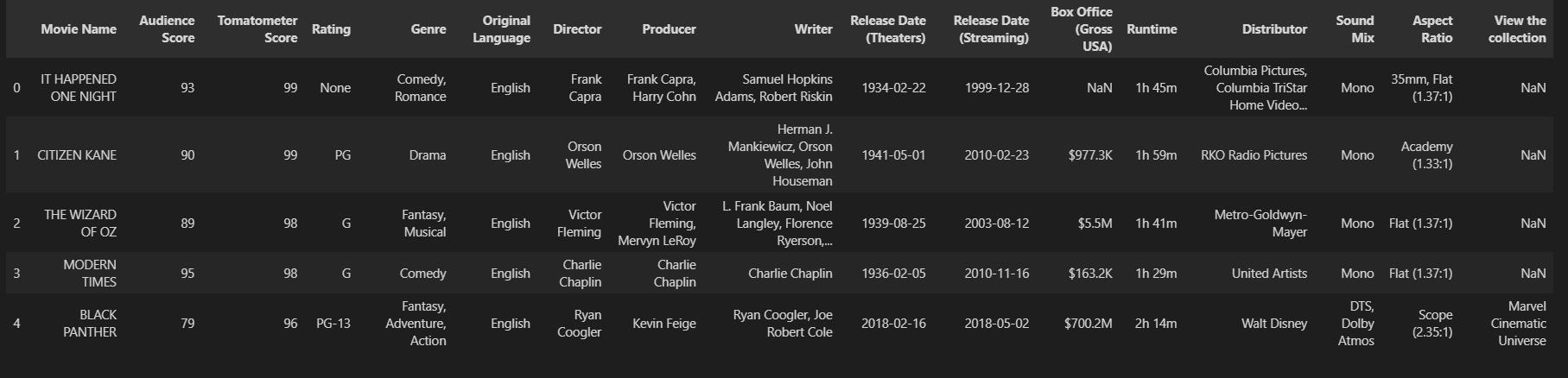
The data is much better now. Save it as a CSV using the below code
df.to_csv(r'D:Data Setsfile.csv', index=False)
Conclusion to Web Scraping
So, this is it. Throughout this web scraping article, we learned a lot of things, from the basics of selenium to preparing a dataset. So, here are the key takeaways
- We briefly learned about different Selenium locators ( By. ID, By. CLASS, By. XPATH, etc.) to find and retrieve elements of a page.
- How to access websites using chrome driver?
- How to inspect HTML elements of the web page to find the elements we need
- We also learned to retrieve required items using the selenium locator By. Xpath
- We created a data frame and stored retrieved data in a readable format
- We cleaned the dataset we just started to enhance its usability and finally held the data in CSV format for future use cases.
By now, you must have realized how handy these scrapers can be. The best thing about this is that you can scrape any web page, create your dataset, and perform analysis.
I hope you liked the article.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Meet your author Sunil kumar Dash, a developer and a writer. Has diverse interests in tech, pop culture, wellness, philosophy and Anime. Exploring underrated music is his hobby. And loves to doom scroll Twitter when bored.






