
Source: Canva
Introduction
After looking at the progress Deep Learning has enabled learning on images, text, and audio datasets, one might wonder whether the Deep Learning models outperform the tree-based models on the tabular datasets as well. Well, if this piques your interest, then there’s good news for you. The authors of this research work looked at 45 mid-sized datasets from various domains having 10k samples. They found that tree-based models (XGBoost & random forests) outperform Neural Networks (NNs) on tabular datasets. Tree-based models offer more accurate predictions with less computation cost when the dataset size is small/medium. Also, in such a setting, they perform well even when there is: i) irregular pattern in the target function, ii) uninformative features, and iii) non-rotationally invariant data. However, this might not hold when additional regularization techniques such as Data Augmentation are added to random search or when the dataset size is massive.
This blog post will look at the findings obtained from the experiments and the associated caveats.
Now let’s dive in!
Highlights
1. This research contributed extensive benchmarks of standard and novel deep learning methods and tree-based models across many datasets and hyperparameter combinations.
2. For tree-based models, the researchers chose three SoTA models: RandomForest, GradientBoostingTrees, and XGBoost. And for deep learning models, a classical MLP, Resnet, FT_Transformer, and SAINT were benchmarked.
3. The tree-based models perform well even when there is: i) irregular pattern in the target function, ii) uninformative features, and iii) non-rotationally invariant data.
4. The tree-based models remain state-of-the-art on medium-sized data (∼10K samples). However, considering the performance gap is narrow between NNs and tree-based models when the dataset size is large (~50k samples), there’s a possibility that NNs might outperform tree-based models in industrial settings.
Results of Random Searches
The deep learning models and tree-based models were extensively compared on generic tabular datasets, and the following are the raw results of the random searches:
1. Hyperparameter optimization does not make NNs state-of-the-art: Tree-based models outperform for every random search budget, and the performance gap persists even after many random search iterations. This ignores that each random search iteration for NNs is often slower than for tree-based models.
2. Categorical variables are not the main weakness of NNs: Categorical variables are often cited as a major issue when employing NNs on tabular data. The results on numerical variables suggest a narrower gap between tree-based models and NNs than including categorical variables. Still, most of this gap exists when learning solely on numerical features.
Results of Empirical Investigation
The tree-based models were investigated empirically to find out why they outperform deep learning on tabular databy finding data transformations that narrow or widen their performance gap. Some of the important findings are as follows:
A) Finding 1: NNs are biased to overly smooth solutions: Each train set is transformed by smoothing the output with a Gaussian Kernel smoother for varying length-scale values of the kernel. This prevents models from learning irregular patterns of the target function. Fig. 1 shows normalized test accuracy as a function of the length-scale of the smoothing kernel. For small length scales, smoothing the target function on
the train set significantly reduces the accuracy of tree-based models but hardly impacts that of NNs. Such findings imply that the target functions in datasets are not smooth and that NNs struggle to fit these irregular functions compared to tree-based models.
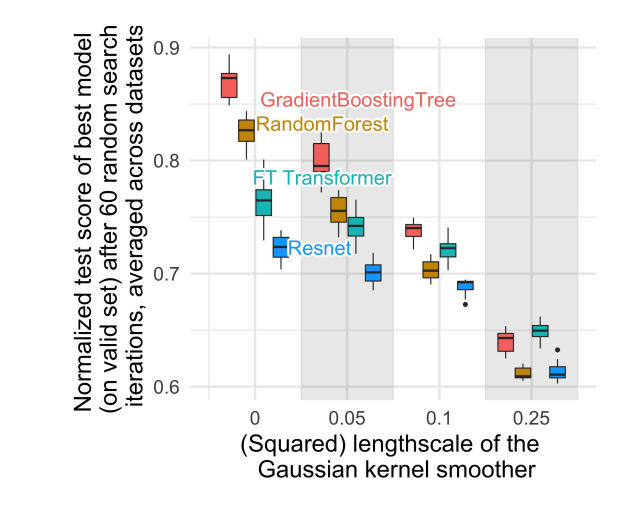
Fig. 1: Normalized test accuracy of different models for varying smoothing of the target function on the train set.
B) Finding 2: Uninformative features affect MLP-like NNs more: MLP-like architectures are not robust to uninformative features. In the two experiments shown in Fig. 2, removing uninformative features (5a) reduced the performance gap
between MLPs (Resnet) and the other models (FT_Transformers and tree-based models), whereas adding uninformative features widens the gap. This indicates that MLPs are less robust to uninformative features.
Furthermore, on the removal of informative features, it was found that the decrease in accuracy due to the removal of these features is compensated by removing uninformative features, which is more helpful for MLPs than for other models.
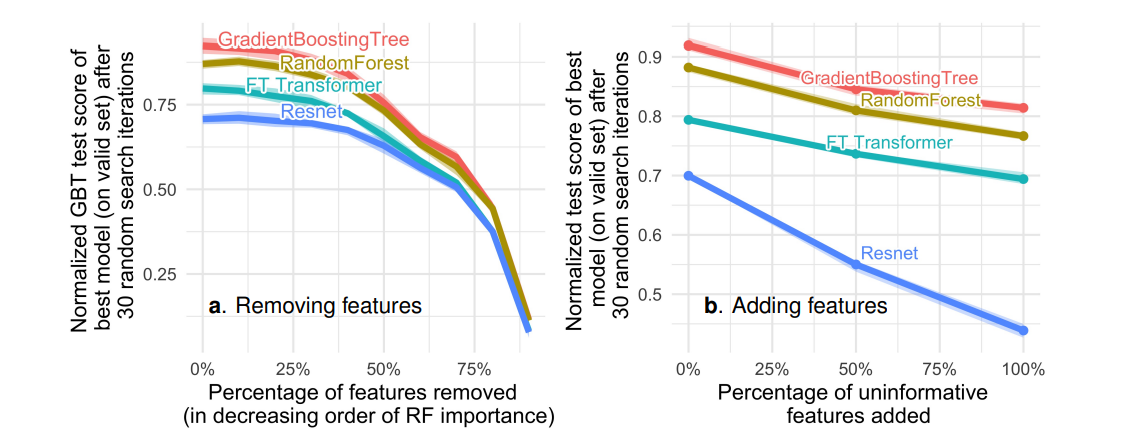
Fig. 2: Variation of test accuracy percentage of uninformative features a) removed b) added
C) Finding 3: Data are non-invariant by rotation, so should be learning procedures: Fig. 3a demonstrates how test accuracy changes while randomly rotating datasets, confirming that only Resnets are rotationally invariant. More notably, random rotations reverse the performance order: NNs now outperform tree-based models, and Resnets outperform FT Transformers. This implies that rotation invariance is undesirable; it encodes the best data biases and cannot be recovered by models invariant to rotations.
Furthermore, it was found that removing the least important 50% of the features in each dataset (before rotating), reduces the performance of all models except Resnets, but this drop is significantly less than when using all the features.
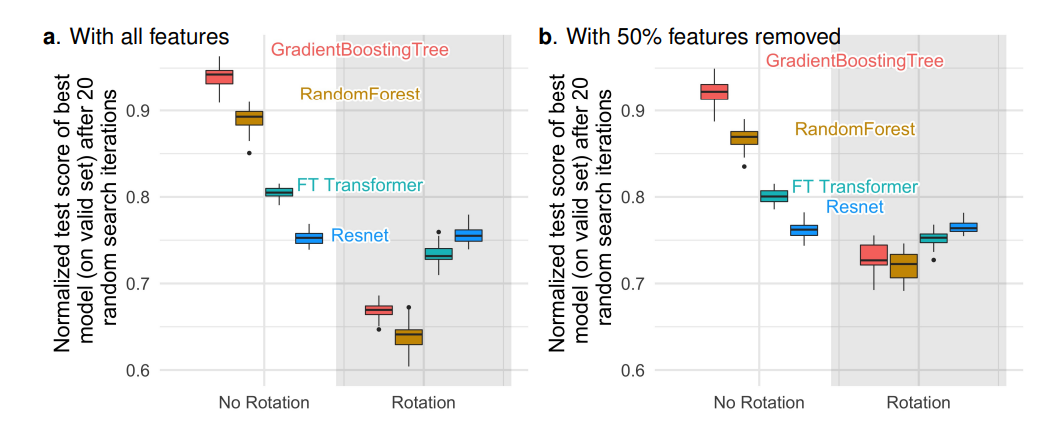
Fig. 3: Normalized test accuracy of different models when datasets are randomly rotated
Research Implications
This research work might help and guide the researchers in the following tasks:
- Building tabular-specific-NNs to be robust to uninformative features
- Building tabular-specific-NNs to preserve the orientation of the data
- Building tabular-specific-NNs to be able to learn irregular functions
- The contributed benchmark is reusable and can be used for new architectures
- The raw results of random searches can enable researchers to cheaply test new algorithms for a fixed hyperparameter optimization budget
Limitations
As fairly pointed out by Sebastian Raschka in a Twitter post, these findings might hold for small to mid-sized datasets and when no additional regularization technique like data augmentation is added to the random search. This study might be perfect for an academic setting. However, because of the increasing dataset size, the performance gap between the neural networks and the tree-based models reduces, it is very likely that the findings might vary in industrial settings, wherein sectors like retail and healthcare normally have massive datasets.
Future Work
Future work includes finding:
- How would the evaluation results differ when the dataset size is too small or large?
- What is the best strategy to deal with issues like missing data or high-cardinality categorical features for NNs and tree-based models?
- How would the evaluation change, including missing data?
Conclusion
To sum it up, in this blog post, we learned:
1. Tree-based models offer more accurate predictions with less computation cost when the dataset size is small/medium.
2. Also, tree-based models perform well even when there is: i) irregular pattern in the target function, ii) uninformative features, and iii) non-rotationally invariant data. (for small/medium size dataset)
3. For large datasets having 50k samples, the performance gap between the tree-based models and NNs is narrow. Hence, there is a fair possibility that NN might outperform the tree-based models in industrial settings, where dataset size is massive or when additional regularization technique like data augmentation is added to the random search.
The code used for all the experiments and comparisons is available at https://github.com/LeoGrin/tabular-benchmark
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I'm a Researcher who works primarily on various Acoustic DL, NLP, and RL tasks. Here, my writing predominantly revolves around topics related to Acoustic DL, NLP, and RL, as well as new emerging technologies. In addition to all of this, I also contribute to open-source projects @Hugging Face.
For work-related queries please contact: [email protected]





