This article was published as a part of the Data Science Blogathon.
Introduction
With the growing social media culture and trends, the amount of data produced daily is increasing drastically. To handle this massive amount of data efficiently, Teradata is becoming an asset to firms. Teradata is ruling over firms, having a large volume of data that needs fast processing.
Teradata can perform powerful OLAP(Online Analytical Programming) functions and process the data parallelly. Teradata provides better performance and linear database scalability than Oracle or any other DBMS data structures.
What is Teradata?
Teradata Corporation, an American IT firm, developed software capable of developing large-scale data warehouse applications called the Teradata software. It is an open-source Relational Database Management System (RDBMS) that uses the concept of parallelism(massively parallel services) and offers support for multiple data warehouse operations.
Teradata supports various platform servers like Unix/Linux/Windows and simultaneously ensures support for various client environments. It is a very efficient and inexpensive RDBMS.
Teradata Architecture
The Teradata architecture is a Massively Parallel Processing(MPP) Architecture designed to handle large volumes of data with extreme ease. It comprises three important components: Parsing Engine(PE), BYNET, and Access Module Processors(AMPs). Let’s elaborate on each component of Teradata architecture to understand their functioning!
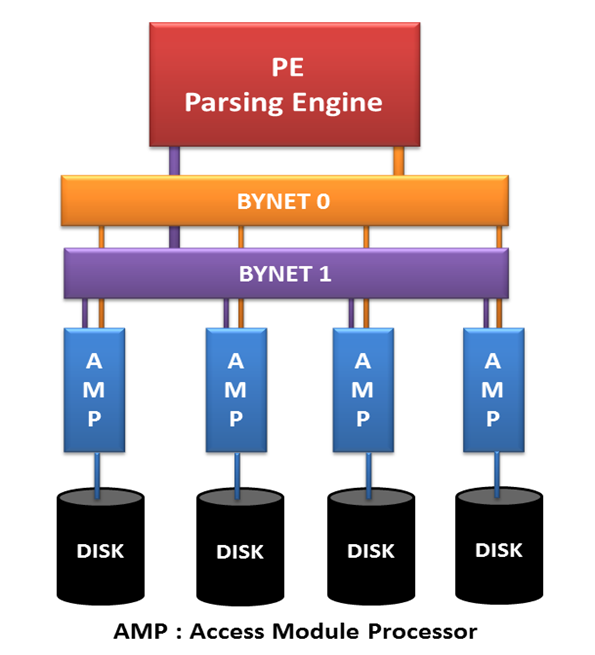
Image:- https://tdexperts.wordpress.com/2016/04/14/teradata-architecture/
A. Parsing Engine: Parsing Engine is considered the base component of Teradata, which parses the queries received from the clients and prepares the execution plan. It is responsible for optimizing and sending requests to the user and managing sessions for them. Some of the important responsibilities of the parsing engine are listed below:
-
It accepts the SQL queries sent by the client and performs parsing to check the syntactical errors over them.
-
It checks whether the objects available in the query are relevant or not.
-
It is responsible for checking whether the user is authenticated against the objects present in the query or not.
-
It creates an efficient execution plan for the query and sends it to BYNET(a message-passing layer).
-
Finally, it receives the output from the Access Module Processors and sends them back to the client.
B. BYNET: BYNET is a networking layer in Teradata that acts as a communication channel between the parsing engine and AMP. The below steps define the functioning of BYNET:
-
The message-passing layer accepts the execution plan from the Parsing Engine(PE) and delivers it to AMP.
-
Then, it gets the processed output generated by AMPs, and its job is to transfer that back to the parsing engine.
-
To maintain adequate availability, there are two BYNETs available, namely BYNET 0 and BYNET 1. In case of primary BYNET failure, a secondary BYNET ensures proper functioning without delay.
C. Access Module Processors (AMPs): AMPs are the virtual processors of Teradata that store the records on its disks. The below steps define the functioning of AMP:
-
It accepts the data and the execution plan from the parsing engine and performs the required conversion associated with generating results like sorting, aggregation, filtering, etc.
-
AMP manages the portion of the database and distributes the table records evenly for data storage.
-
It also performs lock and Space management.
Depending upon the principal function, the architecture of Teradata is recognized in two forms:
-
Storage Architecture
-
Retrieval Architecture
Teradata Storage Architecture
Whenever the client raises a query to insert records, the parsing engine sends the records to BYNET. As soon as BYNET receives the records, it retrieves the required rows and sends them to the target AMP for insertion. Now, AMP has its disks available for record storage, so it keeps those rows on the disks and works as a storage unit.
Teradata Retrieval Architecture
Whenever the Teradata system gets a client request for data retrieval, the Parsing Engine forwards a request to the BYNET. Then the job of BYNET is to forward the retrieval request to the appropriate AMPs. Now, AMPs’ job is to carry out the record search in parallel from all their disks and forward the found records to the BYNET, which in turn sends them to the client with the help of the Parsing Engine.
Difference Between Teradata and Hadoop
Architecture
Hadoop:- The architecture type followed by Hadoop is the Master-Slave Architecture, in which the cluster is made with a single Master node and several Slave nodes. The architecture of Hadoop is comprised of the following components:
-
HDFS: HDFS stands for Hadoop Distributed File System, which is the storage unit of Hadoop architecture.
-
YARN: YARN stands for Yet Another Resource Negotiator. It acts as a resource manager and allocates the available resources in the system.
-
MapReduce: MapReduce acts as the agent who divides the work and collects the output.
Teradata:- Teradata follows the shared-nothing architecture based on a massively parallel processing (MPP) system. Teradata is a single data store that can take multiple concurrent or parallel requests from various client applications. Teradata comprises various elements like BYNET, Parsing Engine(PE), AMPs (Access Module Processors), and multiple nodes.
Technology
Hadoop:- It is an open source Big Data technology platform developed and maintained by Apache Software Foundation, used to store and process massive amounts of data and its applications on scalable clusters of commodity hardware that is relatively inexpensive. It is a framework originally written in Java and used the concept of Google’s MapReduce and GFS(Google File System). It is an optimized way of solving Big Data challenges which involves data that is too diverse and fast-changing for conventional technologies.
Teradata:- Teradata is an active enterprise data warehouse that supports multiple concurrent users from various client platforms. It is an open-source relational database management system(RDBMS) that can run on Unix or Windows. It provides a parallel architecture for efficient performance and acts as an unbeatable data warehousing solution.
Type of Data
Hadoop:- Hadoop is a well-known solution for many data-driven enterprises, and the reason is quite simple: it can process and handle diverse data types. It can easily extract the whole value from all the available data. It can handle 100s of terabytes of data inexpensively and regardless of the data type. It can process structured, semi-structured, and even unstructured data using multiple open-source tools. Hadoop is better in handling a variety of data than Teradata because Teradata is not designed to handle unexpected unstructured data.
Teradata:- Teradata is a simple relational data warehousing solution, and the word ‘relational’ itself suffices that it is best suited for structured data. It can’t store and process semi-structured or unstructured data as its capabilities are to deal with large amounts of structured data available in tabular format data. It provides scalability with outstanding performance and can scale from 100 gigabytes to over 100 plus petabytes of data on a single system.
Data Manipulation in Teradata
Teradata supports data manipulation and allows us to insert, delete and update records using simple SQL Queries.
A. Insert Records
Whenever we create an RDBMS table, the first task is to always put some data inside the table, to do so we can use the “INSERT INTO” statement.
Syntax:-
INSERT INTO
(coln1, coln2, coln3,…) VALUES (v1, v2, v3 …);
Example:-
INSERT INTO Empl ( Eid, FName, LName, DOB, DOJ,Dept) VALUES ( ‘E111’, 'John', 'Kelvin', '10-11-1986', '25-12-2001',04);
B. Update Records
To update any existing record in the table, we can use the “UPDATE…SET” statement.
Syntax:-
UPDATE
SET = [WHERE condition];
Example:-
UPDATE Empl SET Dept = 01 WHERE Eid = ‘E111’;
C. Delete Records
To delete any existing record in the table, we can use the “DELETE…FROM” statement.
Syntax:-
DELETE FROM[WHERE condition];
Example:-
DELETE FROM Empl WHERE Eid = ‘E111’;
Conclusion
Teradata is a very reliable technology used by many giants to process their very critical structured data stored in tabular format. It uses a real-time data warehousing engine that can respond to continuously changing and complex business needs. Teradata is famous for offering scalability, high performance, and analytical capabilities. The key points drawn from this blog are:
1. What does Teradata imply?
2. We discussed the two types of architecture of Teradata, including the storage and retrieval architecture.
3. We also took a glimpse of Teradata components which contains BYNET, AMP, and the Parsing Engine.
4. We also discussed the exact difference between Teradata and Hadoop based on architecture, Technology, and Type of Data. Here, we discussed how Teradata is more beneficial for long-term structured data of MNCs.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I am a tech enthusiast, a student, and a learner. I am a critical reader and a lover of words who finds writing blogs interesting. I possess the capability to research and learn new technologies quickly.






