
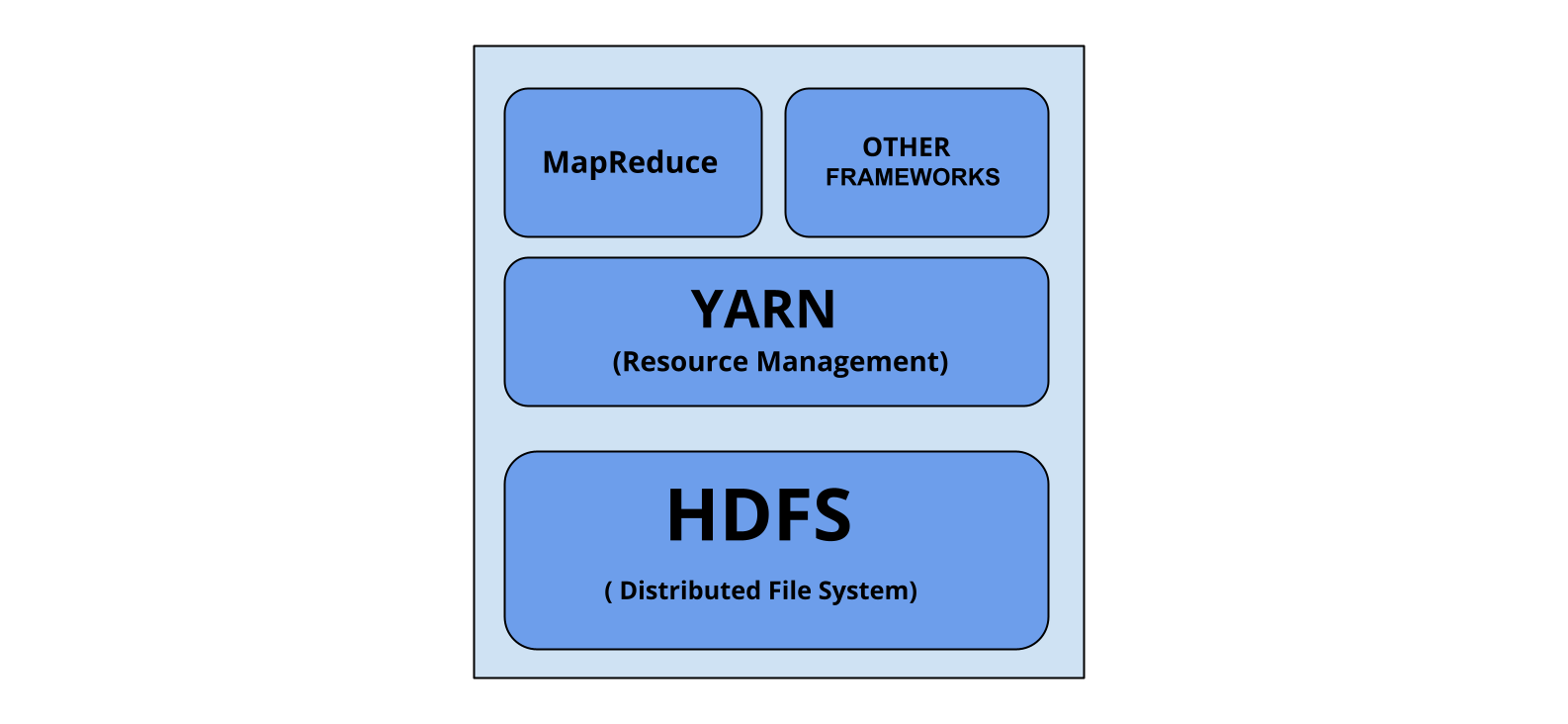
In today’s world, data is being generated at an ever-growing pace, leading to a boom in demand for Big Data tools such as Hadoop, Pig, Spark, Hive, and many more. The tool that stands out the most is Apache Hadoop, and one of its core components is YARN.
Apache Hadoop YARN, or as it is called Yet Another Resource Negotiator. It is an upgrade to MapReduce present in Hadoop version 1.0 because it is a mighty and efficient resource manager that helps support applications such as HBase, Spark, and Hive. The main idea behind YARN is a layer that is used to split up the resource management layer and processing component layer.
YARN can work parallelly with various applications, bringing greater efficiency while processing the data. YARN is responsible for providing resources such as storage space and also functions as a resource manager.
Before the framework received its official name, it was known as MapReduce2, which is used by YARN to manage and allocate resources for various processes and jobs efficiently.
Why YARN?
In the Hadoop version 1.0, we used MapReduce, which uses the functionalities of job trackers and task trackers for resource management, job scheduling, and monitoring of jobs. Still, after the introduction of YARN, these responsibilities are managed by the resource manager and application master.
Additionally, Hadoop version 2.0 introduces the YARN model, which is more isolated and scalable than its earlier version. YARN was designed to address many of the limitations in MapReduce, which are discussed below:
Scalability
Unlike MapReduce, the resource manager and application master has cluster-wise responsibilities which handle all the jobs and tasks. YARN provides a single application master per job, which is why YARN has high scalability, designed to scale up to 10,000 nodes and 100,000 studies.
Utilization
The YARN framework does not have any fixed slots for tasks that do not cause any issue of resource wastage. It provides a central resource manager which allows users to share multiple applications through a shared resource.
Compatibility
YARN introduces the concept of central resource management. YARN comes as the backwards-compatible framework, which enables Hadoop to support various kinds of applications along with MapReduce.
Reliability
MapReduce is based on a single master and multiple slave architecture, which means the master is down. The slave will not execute their operation, leading to a single failure point in Hadoop version 1.0. In contrast, Hadoop version 2.0 is based on the YARN, which is more reliable as it has the concept of multiple masters and slaves. Hence, if, in any case, the master is unavailable, there is another master that will act as a backup to resume its process and continue its execution.
Components Of YARN
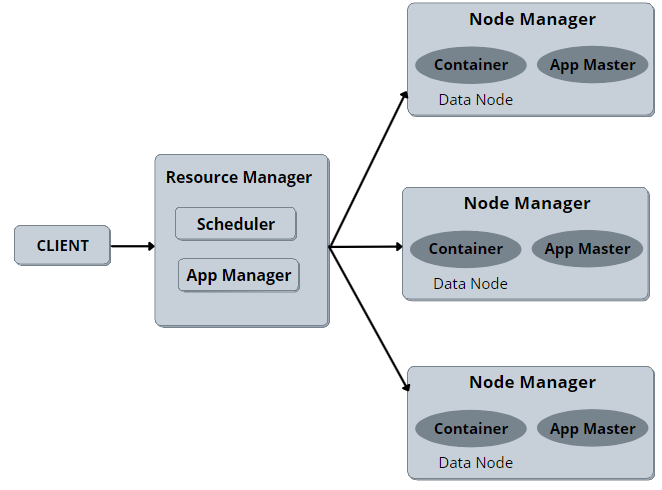
Resource Manager
The Resource Manager has the highest authority as it manages the allocation of resources. It runs many services, including the resource scheduler, which decides how to assign the resources.
Resource Manager contains the metadata regarding the location and number of resources available to the data nodes, collectively known as Rack awareness. The Resource Manager is present on each cluster and can accept processes from the users and allocate resources to them.
The resource manager can be broken down into two sub-parts:
- Application Manager
The application manager is responsible for validating the jobs submitted to the resource manager. It verifies if the system has enough resources to run the job and rejects them if it is out of resources. It also ensures that there is no other application with the same ID that has already been submitted that could cause an error. After performing these checks, it finally forwards the application to the scheduler.
- Schedulers
The scheduler as the name suggests is responsible for scheduling the tasks. The scheduler neither monitors nor tracks the status of the application nor does restart if there is any failure occurred. There are three types of Schedulers available in YARN: FIFO [First In, First Out] schedulers, capacity schedulers, and Fair schedulers. Out of these clusters to run large jobs executed promptly, it’s better to use Capacity and Fair Schedulers.
Node Manager
The Node Manager works as a slave installed at each node and functions as a monitoring and reporting agent for the Resource Manager. It also transmits the health status of each node to the Resource Manager and offers resources to the cluster.
It is responsible for monitoring resource usage by individual containers and reporting it to the Resource manager. The Node Manager can also kill or destroy the container if it receives a command from the Resource Manager to do so.
It also monitors the usage of resources, performs log Management, and helps in creating container processes and executing them on the request of the application master.
Now we shall discuss the components of Node Manager:
- Containers
Containers are a fraction of Node Manager capacity, whose responsibility is to provide physical resources like a disk space on a single node. All of the actual processing takes place inside the container. An application can use a specific amount of memory from the CPU only after permission has been granted by the container.
- Application Master
Application master is the framework-specific process that negotiates resources for a single application. It works along with the Node Manager and monitors the execution of the task. Application Master also sends heartbeats to the resource manager which provides a report after the application has started. Application Master requests the container in the node manager by launching CLC (Container Launch Context) which takes care of all the resources required an application needs to execute.
Steps to Submit YARN Application
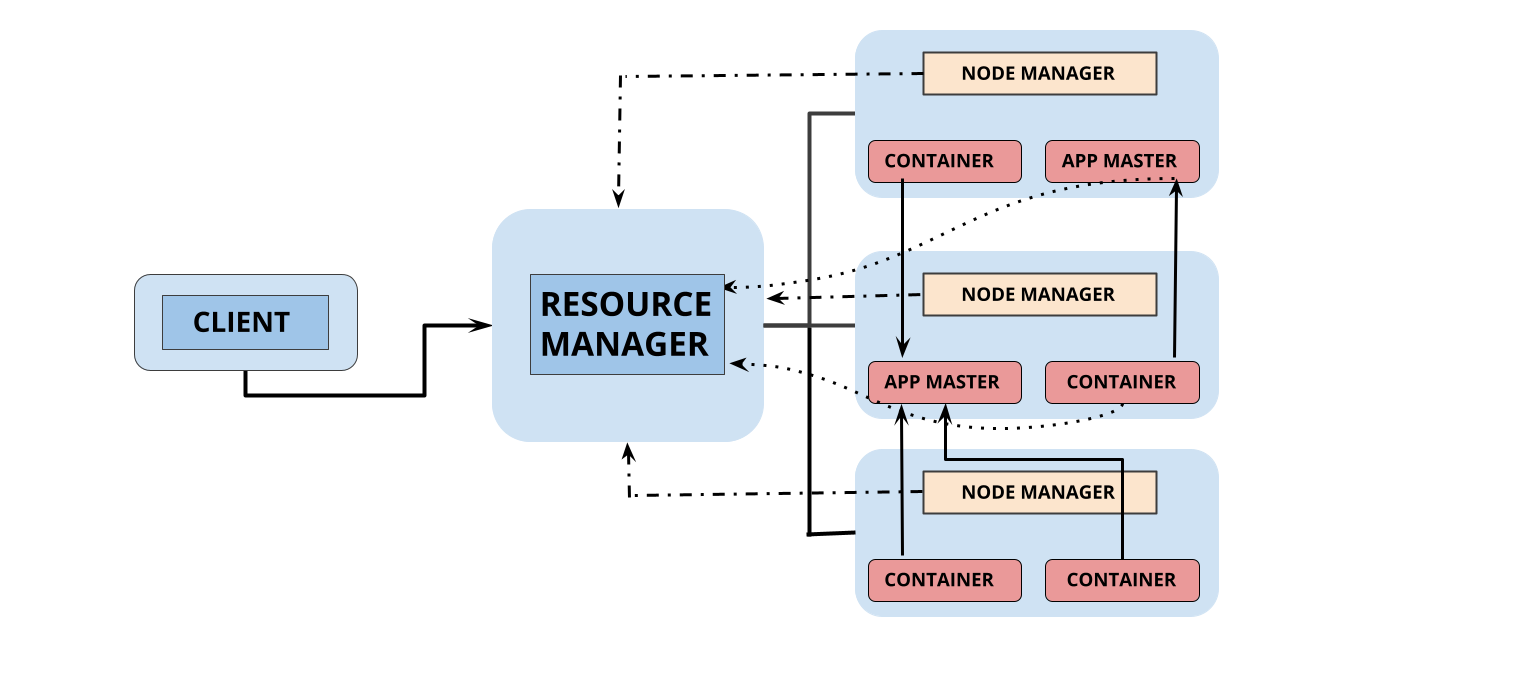
1. To run an application client connects the resource manager and requests the new application ID. Resource Manager forwards the ID and available resources, depending on various constraints such as queue capacity, access control list, etc.
2. Resource Manager then provides application master, which launches containers to carry out the operations required for the job.
3. Application Master registers to the Resource Manager, which allows AM to get the necessary details about the job, which helps select an optimal number of containers.
4. The resource manager permits app master, which will select appropriate containers required for the job and performs processing of the job.
5. On successful allocation of containers, the application master launches containers by container launch specifications to the Node Manager. The launch specifications include the required information needed by the container that allows communication with the application master.
6. The code running inside the container consists of information such as progress, status, etc., which is forwarded to the application master by application-specific protocol.
7. The client that submits the program communicates directly with the application master to collect the info like status, progress update, etc., with the help of application-specific protocol.
8. Once all the tasks are performed, the AM will free the resources occupied by shutting them down and disconnects itself from the resource manager to get utilized again.
ENDNOTES
To sum it up, I hope you found the resources helpful to get an overview of YARN and get a basic about its components and understand its architecture. I hope you have understood every concept in this article. If you enjoyed this article, share it with your friends and colleagues! If you have any queries, reach out to me in the comments below. Till then, KEEP LEARNING 🙂






