Introduction
R offers multiple packages for performing data analysis. Apart from providing an awesome interface for statistical analysis, the next best thing about R is the endless support it gets from developers and data science maestros from all over the world. Current count of downloadable packages from CRAN stands close to 7000 packages!
Beyond some of the popular packages such as caret, ggplot, dplyr, lattice, there exist many more libraries which remain unnoticeable, but prove to be very handy at certain stages of analysis. So, we created a comprehensive list of all packages in R.
In order to make the guide more useful, we further did 2 things:
- Mapped use of each of these libraries to the stage they generally get used at – Pre-Modeling, Modeling and Post-Modeling.
- Created a handy infographic with the most commonly used libraries. Analysts can just print this out and keep handy for reference. The graphic is displayed below:
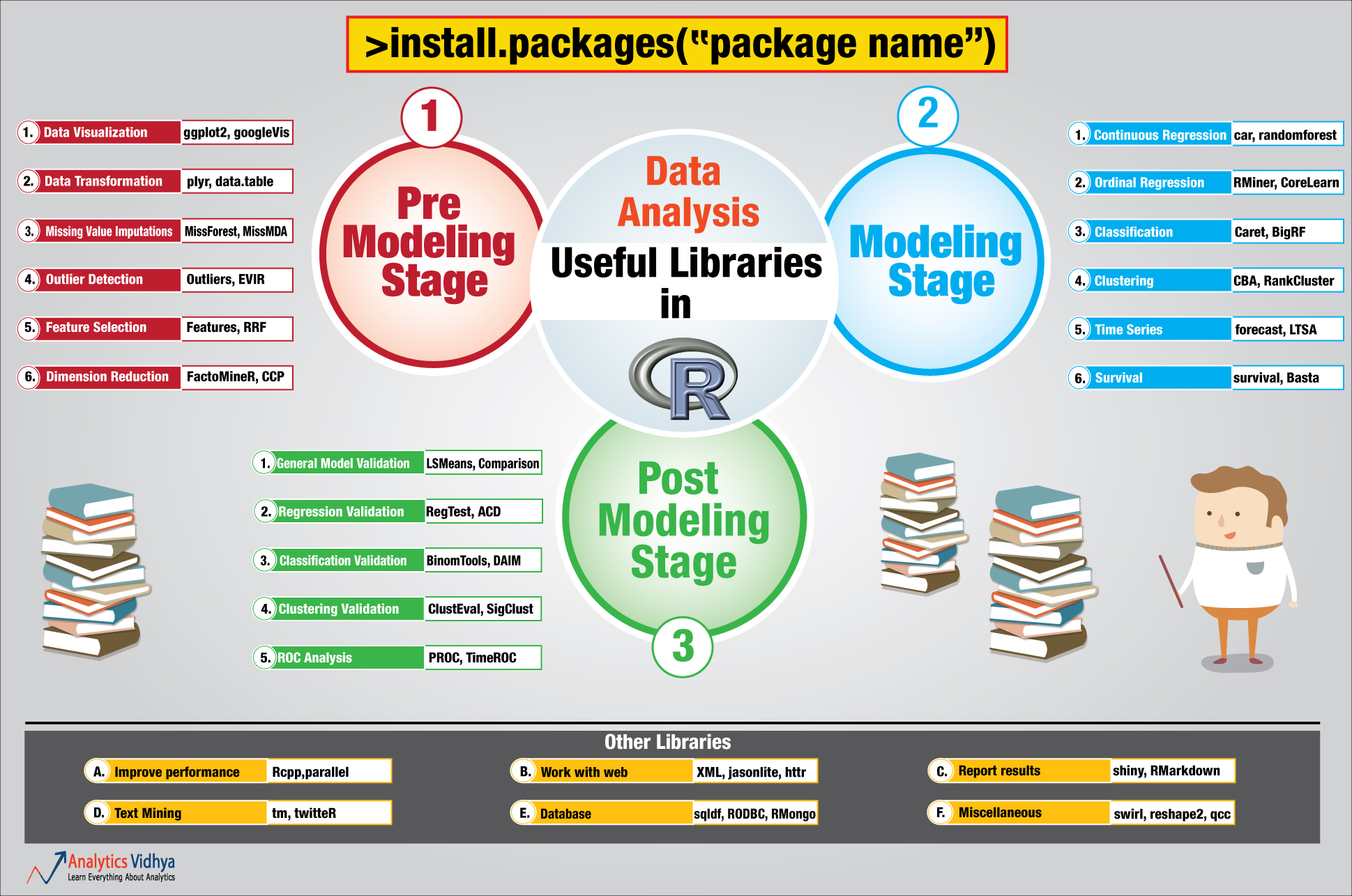
Here is a complete guide to powerful R packages, which are categorized into various stages of process of data analysis. Download Here.







Thanks for the pdf, it's very thorough.
Thanks for another great reference! I would also suggest slam and quanteda for text mining in R.
Run the code to install all the above library in a singel go. ##This should detect and install missing packages before loading them - hopefully! list.of.packages <- c("dplyr", "plyr", "data.table", "MissForest", "MissMDA", "Outliers", "EVIR", "Features", "RRF", "FactorMiner", "CCP", "ggplot2", "googkleVis", "Rcharts", "car", "randomforest", "Rminer", "CoreLearn", "caret", "BigRF", "CBA", "RankCluster", "forecat", "LTSA", "survival", "Basta", "LSMean", "Comparison", "RegTest", "ACD", "BinomTools", "DAIM", "ClustEval", "SigClust", "PROC", "TimeROC", "Rcpp", "parallel", "xml", "httr", "rjson", "jasonlite", "shiny", "Rmarkdown", "tm", "OpenNLP", "sqldf", "RODBC", "rmonogodb") new.packages <- list.of.packages[!(list.of.packages %in% installed.packages()[,"Package"])] if(length(new.packages)) install.packages(new.packages) lapply(list.of.packages,function(x){library(x,character.only=TRUE)})
@Balaji Subudhi. Thanks Balaji, I installed everything in single shot with help of your code.