Introduction
In this short article, I will talk about unsupervised learning especially in the energy domain. The blog would mainly focus on the application of Deep Learning in real-time than emphasizing the underlying concepts. But first, let us see what an Unsupervised Machine Learning mean? It is a branch of machine learning which deals with identifying hidden patterns from the datasets and does not depend on the necessity of the target variable in the data to be labeled. So here the algorithms are used to discover the underlying structure of the data like the presence of data clusters, odd data detection, etc.
When the Target value of the desired variable under study is unknown, the unsupervised form of Deep learning techniques is used to find the relations between the target (Desired Variable) and other variables in the data to arrive at the outcome ( That is the probable value of the Target).
Business Problem
As mentioned above, The business case will be from the Energy Sector and particularly the Renewable form of (Solar Panels) Energy. The solar panel, using photovoltaic and silicon solar cells to convert radiation into power, has become quite popular around the world. Increasingly becoming an essential energy option for the future. Consider a scenario where I have solar panels installed at a particular Site A for some time now and getting good benefits in the form of savings from metered electricity of the Electricity Boards.
Now I want a similar kind of panels to be also installed at my other site B, which is in a different geographical location/ region. But before doing another investment can I know based on the power that I am getting from installed panels at Site A, how much power I can get at site B? This will help me in making the right decision concerning the investment and power needs at that location. Let us now look at the problem statement
Problem Statement
Based on the Power that is generated from the installed solar panels at sites A, B’ for the past M months, predict the Power that can be generated from the panels installed at the site another unknown site B on any future date, where B and B’ are nearby, that is in same geographical location.
Solar Dataset: (239538, 10)
The Data is from a particular site for the period from December 2019 till October 2020 and it has 10 features with 0.23 million rows. This after converting to NumPy arrays will have the below structure
array(
[2019., 12., 4., …, 6., 0., 0.],
[2019., 12., 4., …, 6., 1., 0.],
[2019., 12., 4., …, 6., 2., 0.],
…,
[2020., 10., 4., …, 17., 57., 0.],
[2020., 10., 4., …, 17., 58., 0.],
[2020., 10., 4., …, 17., 59., 0.]])
The main source of power for the solar panels are the sunlight and hence to cater to the seasonality and other factors, the dataset comprises of component like ‘Year’,’Month’, ‘Quarter’,’Dayofweek’,’Dayofmonth’,’Dayofyear’, ‘Weekofyear’, ‘Hour’,’Minute’ etc as key predictors and the Generated Power as the dependent variable. A typical power generation for a day looks quite like a gaussian curve
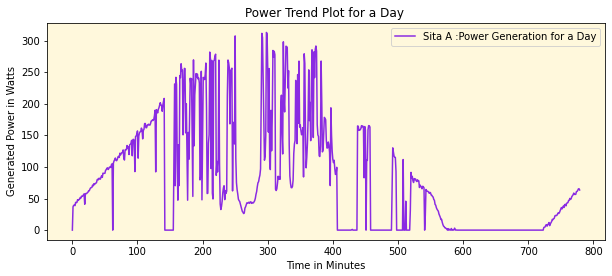
We can see that the power is generated is between 6.00 AM to evening 18:00 hrs (Sunshine hours), represented in Minutes. The power is less initially then gradually increases and attains peak sometime around noontime and then slowly reduces by end of day and appears to inherit qualities of a bell curve. From this we can intuitively infer that all solar panels will have this pattern irrespective of which part of geography it is placed, the only difference will be in the Amount of Power being generated at that particular site, which in turn may depend on a lot of factors like seasonality, weather, and other such factors like available sunlight.
Power and Beauty of Autoencoders (AE)
An autoencoder is a type of unsupervised learning technique, which is used to compress the original dataset and then reconstruct it from the compressed data. There are an Encoder and Decoder component here which does exactly these functions. Here the main idea of the neural network is to transform the inputs to outputs with very little distortions. That is the autoencoders will work very well where the output is very similar to the input like image denoising.
Autoencoders are also used for feature extraction, especially where data grows high dimensional. Traditionally autoencoders are used commonly in Images datasets but here I will be demonstrating it on a numerical dataset. The concept remains the same. In my example, I will be exploiting this very property of AE as in my case the output of power I get in another site is going to be very similar to the current site as explained above. I will be demonstrating the 2 variants of AE, one LSTM based AE, and the traditional AE in Keras.
Case 1: LSTM based Autoencoders
I have historic data of 2 sites A and B’ from December 2019 till October 2020. Site B is in the same geographical boundary as site B’. I wish to find the Power that gets generated at site B based on the historical data of Sita A, B’. I do not have any information about the target site B.
X1s and X3s are normalized data of Site A and X3s and X4s are normalized data of site B’. The dataset has 10 very similar features with slight variations in X2s[:,9] and X4s[:,9] that have power value at these respective sites. We will try to transform X1s to X2s using a simple LSTM autoencoder. I have used Mean Absolute Error as a loss and ‘linear’ activation here as I need to have the predicted power value to be very close to the actuals ( site B’ in this case).
This is just a sample code to give an idea of how to build LSTM based AE and hyper-parameters needs to be tunned with different optimizers / multiple layers/epochs to get a very good approximation. Refer to the code below
from keras.models import Sequential
from keras.layers import LSTM
from keras.layers import Dense,Dropout
from keras.layers import RepeatVector
from keras.layers import TimeDistributed
from keras.callbacks import EarlyStopping,M
odelCheckpoint
from keras.regularizers import l1
from keras import regularizers
# define model
model = Sequential()
model.add(LSTM(256, activation='linear', input_shape=(X1801861s.shape[1],1),activity_regularizer=regularizers.l1(10e-,return_sequences=False))
model.add(RepeatVector(X1s.shape[1]))
model.add(LSTM(256, activation='linear', return_sequences=True))
model.add(TimeDistributed(Dense(1, activation='linear')))
adam = keras.optimizers.Adam(lr=0.001)
model.compile(optimizer=adam, loss='MAE')
model.summary()
earlyStopping = EarlyStopping(monitor='val_loss', patience=30, verbose=0, mode='min')
mcp_save = ModelCheckpoint('sola-001.mdl_wts.hdf5', save_best_only=True, monitor='val_loss', mode='min')
history = model.fit(X1s, X2s, epochs=500, batch_size=1024,callbacks=[earlyStopping, mcp_save], validation_data = (X3s,X4s)
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= lstm_8 (LSTM) (None, 256) 264192 _________________________________________________________________ repeat_vector_4 (RepeatVecto (None, 10, 256) 0 _________________________________________________________________ lstm_9 (LSTM) (None, 10, 256) 525312 _________________________________________________________________ time_distributed_4 (TimeDist (None, 10, 1) 257 ================================================================= Total params: 789,761 Trainable params: 789,761 Non-trainable params: 0
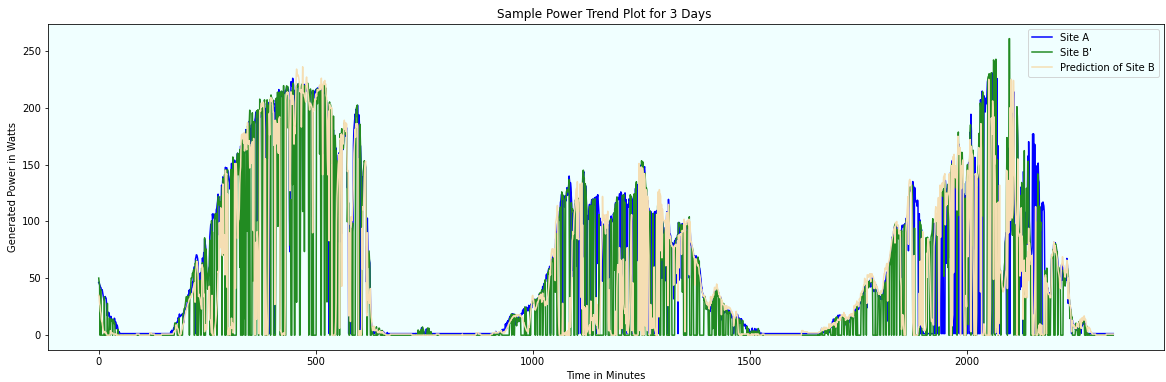
The below plot gives the Site B prediction concerning A & B’. The expectation is it should be very close to B’. Here, we are using the data of site A, B’ to arrive at the predictions for unknown site B. The plot below is for randomly picked 3 days trend at these sites
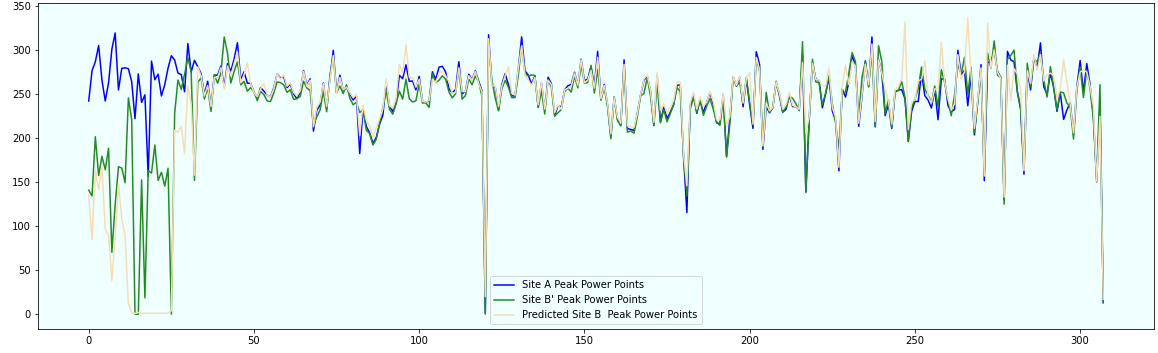
This chart shows the Peak Power over 300 days for all the 3 sites A, B’ and target Site B
Case 2: Traditional Autoencoder Model
input_dim = X1s.shape[1]
encoding_dim = 10
input_layer = Input(shape=(input_dim, ))
encoder = Dense(encoding_dim, activation="linear",activity_regularizer=regularizers.l1(10e-5))(input_layer)
decoder = Dense(input_dim, activation='linear')(encoder)
encoder = Model(input_layer,encoder)
autoencoder = Model(inputs=input_layer, outputs=decoder)
adam = keras.optimizers.Adam(lr=0.001)
earlyStopping = EarlyStopping(monitor='val_loss', patience=30, verbose=0, mode='min')
mcp_save = ModelCheckpoint('sola-002.mdl_wts.hdf5', save_best_only=True, monitor='loss', mode='min')
autoencoder.compile(optimizer=adam,loss='MAE')
autoencoder.summary()
Model: "functional_3" ________________________________________________________________
Layer (type) Output Shape Param #
================================================================= input_1 (InputLayer) [(None, 10)] 0 _________________________________________________________________ dense (Dense) (None, 10) 110 _________________________________________________________________ dense_1 (Dense) (None, 10) 110 ================================================================= Total params: 220 Trainable params: 220 Non-trainable params: 0
Evaluate the model after training the LSTM / Regular AE Model :
from sklearn.metrics import mean_absolute_error,mean_squared_error,mean_squared_log_error import math mean_absolute_error(a,pd),math.sqrt(mean_squared_error(a,pd)),mean_absolute_error(act,p),math.sqrt(mean_squared_error(act,p))
Models
MAE – Peak Power
MSE -Peak Power
MAE -Instant Power
MSE -Instant Power
LSTM AE
16.425307183116885
36.75704731479356
1.8404600416117294
12.231826378081937
Regular AE
16.415917917337666
38.456323346248176
2.859275677961502
17.71553061457107
p – instant power for the day; pd – peak power for the day
act – actual instant power for the day; a – actual peak power for the day
Finally, we randomly plot the peak power at site B’ and the new desired site B for 30 days
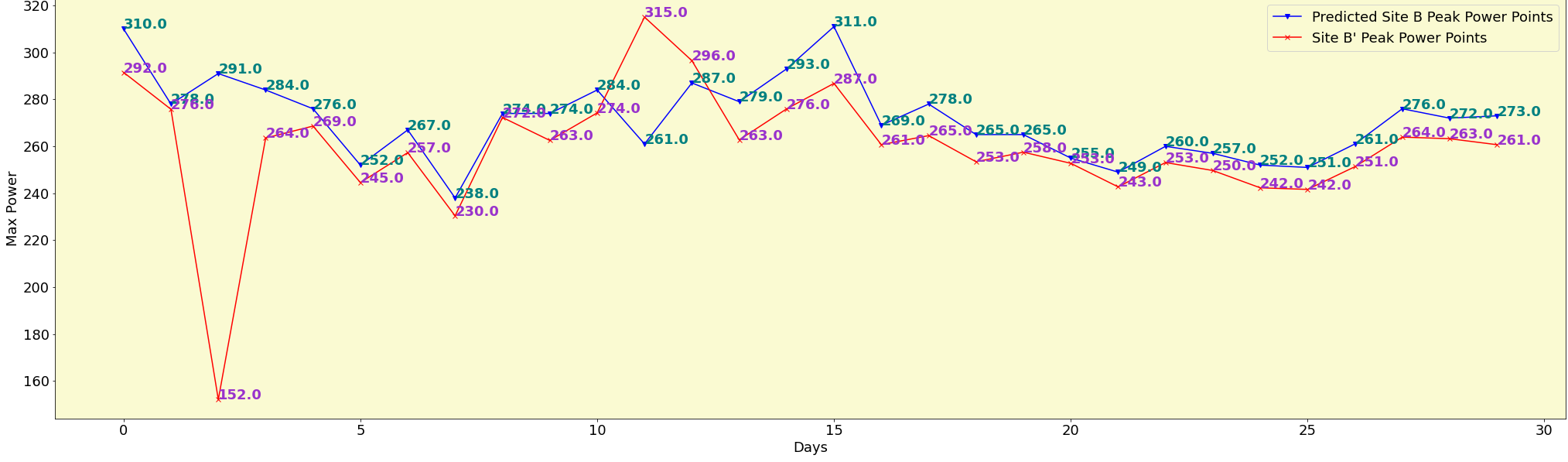
From the above, we can clearly see that the model has predicted peak values close to the actuals found at site B’ on the corresponding time for many days and there are few wide variations on some other days. Well, in this blog, I only highlighted the power of autoencoders and how it can help detect the unknown. Quite amazing isn’t it? in the field, we need to include a few domain-specific variables and train the model on over 1 million data points to get even better results.
Thanks


