This article was published as a part of the Data Science Blogathon.
Introduction
Today one of the trendy social media platforms is…. guess what? One and only Whatsapp😅. It is one of the favorite social media platforms among all of us because of its attractive features. It has more than 2B users worldwide and “According to one survey an average user spends more than 195 minutes per week on WhatsApp”. How terrible the above statement is. Leave all these things and let’s understand what actually WhatsApp analyzer means?
WhatsApp Analyzer means we are analyzing our WhatsApp group activities. It tracks our conversation and analyses how much time we are spending or saying it as “wasting” on WhatsApp. The aim of this article is to provide step by step guide to build our own WhatsApp analyzer using python. Here I used different python libraries which help me to extract useful information from raw data. Here I choose my college official WhatsApp group to analyze the pattern students were following therefore in some of the snapshots I blur the contact information of my college faculty and my classmates, sorry for that. So let’s begin…
Required libraries :
- Regex
- Pandas
- Matplotlib
- Numpy
- Seaborn
- Datetime
- Emoji
- Wordcloud
- Heatmapz
- NLTK
- Plotly
Let’s import all these libraries :
import re import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns from datetime import * import datetime as dt from matplotlib.ticker import MaxNLocator import regex import emoji from seaborn import * from heatmap import heatmap from wordcloud import WordCloud , STOPWORDS , ImageColorGenerator from nltk import * from plotly import express as px
WhatsApp provides us the feature of exporting chats, so let’s export the chat and save the file. In step 2, we will create a python program that will extract the Date, Username of Author, Time, Messages from exported chat file and creating a data frame, and storing all data in it. Actually, the data collection and preprocessing part are covered in step 2 and further steps.
Let’s extract all the useful info. from chat file using regex :
### Python code to extract Date from chat file
def startsWithDateAndTime(s):
pattern = ‘^([0-9]+)(/)([0-9]+)(/)([0-9][0-9]), ([0-9]+):([0-9][0-9]) (AM|PM) -‘
result = re.match(pattern, s)
if result:
return True
return False
### Regex pattern to extract username of Author.
def FindAuthor(s):
patterns = [
'([w]+):', # First Name
'([w]+[s]+[w]+):', # First Name + Last Name
'([w]+[s]+[w]+[s]+[w]+):', # First Name + Middle Name + Last Name
'([+]d{2} d{5} d{5}):', # Mobile Number (India no.)
'([+]d{2} d{3} d{3} d{4}):', # Mobile Number (US no.)
'([w]+)[u263a-U0001f999]+:', # Name and Emoji
]
pattern = '^' + '|'.join(patterns)
result = re.match(pattern, s)
if result:
return True
return False
### Extracting Date, Time, Author and message from the chat file.
def getDataPoint(line):
splitLine = line.split(' - ')
dateTime = splitLine[0]
date, time = dateTime.split(', ')
message = ' '.join(splitLine[1:])
if FindAuthor(message):
splitMessage = message.split(': ')
author = splitMessage[0]
message = ' '.join(splitMessage[1:])
else:
author = None
return date, time, author, message
### Finally creating a dataframe and storing all data inside that dataframe.
parsedData = [] # List to keep track of data so it can be used by a Pandas dataframe
### Uploading exported chat file
conversationPath = 'WhatsApp Chat with TE Comp 20-21 Official.txt' # chat file
with open(conversationPath, encoding="utf-8") as fp:
### Skipping first line of the file because contains information related to something about end-to-end encryption
fp.readline()
messageBuffer = []
date, time, author = None, None, None
while True:
line = fp.readline()
if not line:
break
line = line.strip()
if startsWithDateAndTime(line):
if len(messageBuffer) > 0:
parsedData.append([date, time, author, ' '.join(messageBuffer)])
messageBuffer.clear()
date, time, author, message = getDataPoint(line)
messageBuffer.append(message)
else:
messageBuffer.append(line)
df = pd.DataFrame(parsedData, columns=['Date', 'Time', 'Author', 'Message']) # Initialising a pandas Dataframe.
### changing datatype of "Date" column.
df["Date"] = pd.to_datetime(df["Date"])
First, look at our newborn dataset :
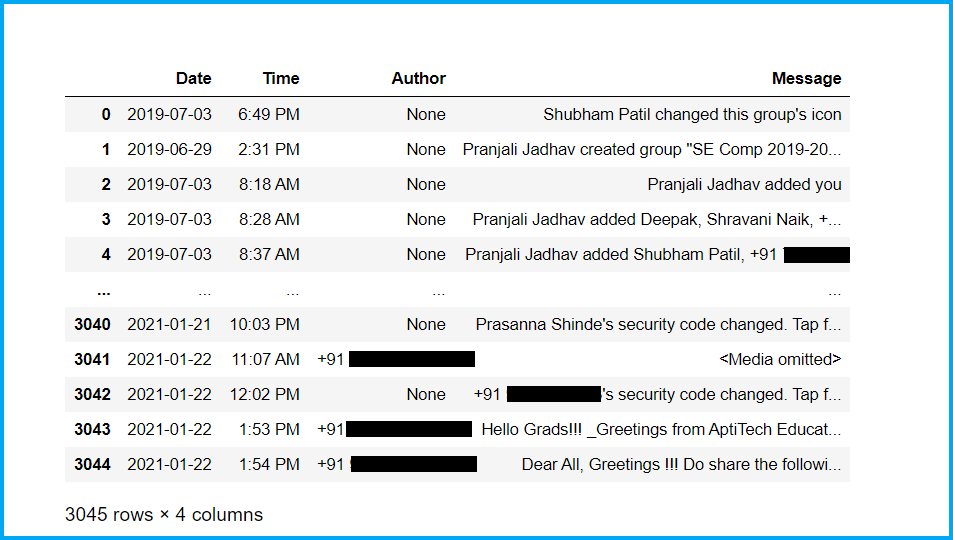
Now, let’s check the basic information of our dataset and clean the dataset :
### Checking shape of dataset. df.shape ### Checking basic information of dataset df.info() ### Checking no. of null values in dataset df.isnull().sum() ### Checking head part of dataset df.head(50) ### Checking tail part of dataset df.tail(50) ### Droping Nan values from dataset df = df.dropna() df = df.reset_index(drop=True) df.shape ### Checking no. of authors of group df['Author'].nunique() ### Checking authors of group df['Author'].unique()
Now, let’s preprocess our dataset and try to extract useful information from it:
### Adding one more column of "Day" for better analysis, here we use datetime library which help us to do this task easily.
weeks = {
0 : 'Monday',
1 : 'Tuesday',
2 : 'Wednesday',
3 : 'Thrusday',
4 : 'Friday',
5 : 'Saturday',
6 : 'Sunday'
}
df['Day'] = df['Date'].dt.weekday.map(weeks)
### Rearranging the columns for better understanding
df = df[['Date','Day','Time','Author','Message']]
### Changing the datatype of column "Day".
df['Day'] = df['Day'].astype('category')
### Looking newborn dataset.
df.head()
### Counting number of letters in each message
df['Letter's'] = df['Message'].apply(lambda s : len(s))
### Counting number of word's in each message
df['Word's'] = df['Message'].apply(lambda s : len(s.split(' ')))
### Function to count number of links in dataset, it will add extra column and store information in it.
URLPATTERN = r'(https?://S+)'
df['Url_Count'] = df.Message.apply(lambda x: re.findall(URLPATTERN, x)).str.len()
links = np.sum(df.Url_Count)
### Function to count number of media in chat.
MEDIAPATTERN = r'<Media omitted>'
df['Media_Count'] = df.Message.apply(lambda x : re.findall(MEDIAPATTERN, x)).str.len()
media = np.sum(df.Media_Count)
### Looking updated dataset
df
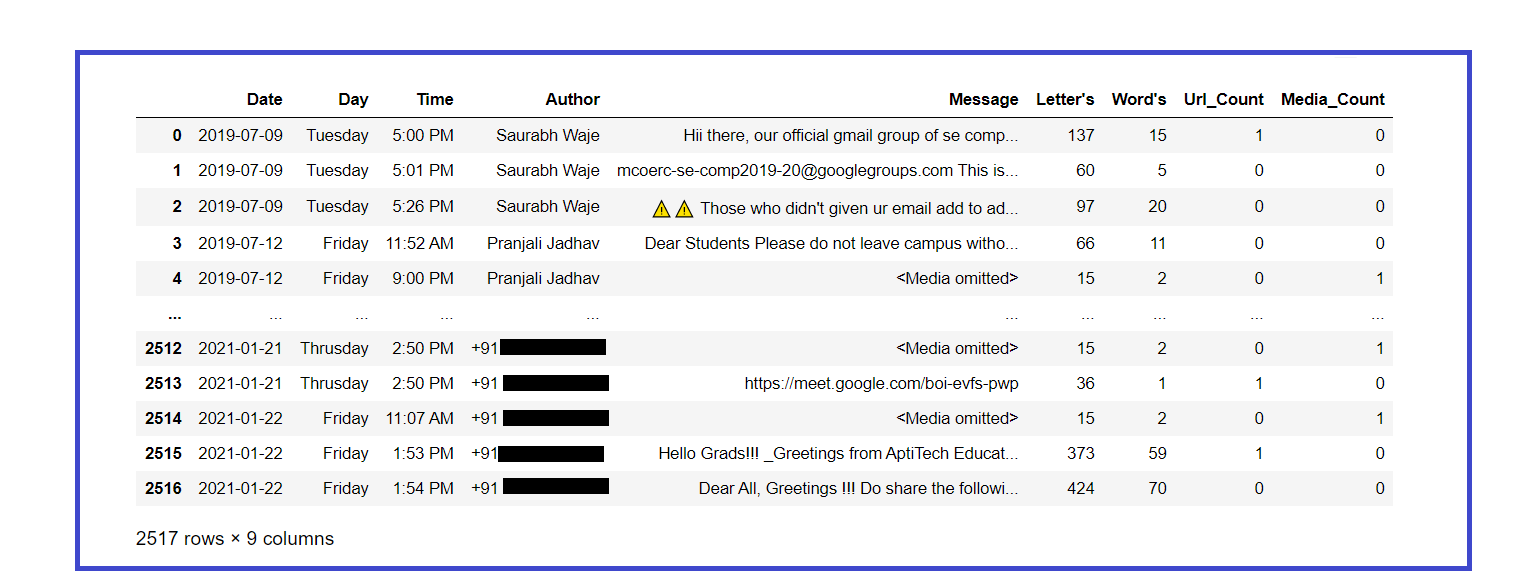
Extracting basic statistics from the dataset :
total_messages = df.shape[0]
media_messages = df[df['Message'] == '<Media omitted>'].shape[0]
links = np.sum(df.Url_Count)
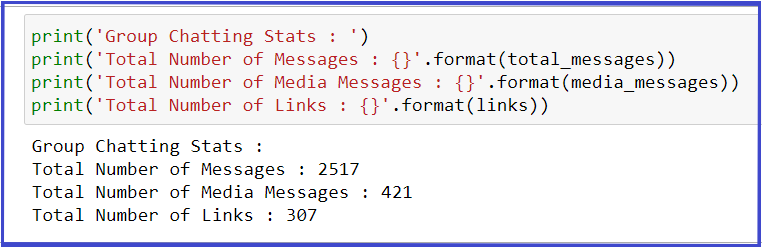
print('Group Chatting Stats : ')
print('Total Number of Messages : {}'.format(total_messages))
print('Total Number of Media Messages : {}'.format(media_messages))
print('Total Number of Links : {}'.format(links))
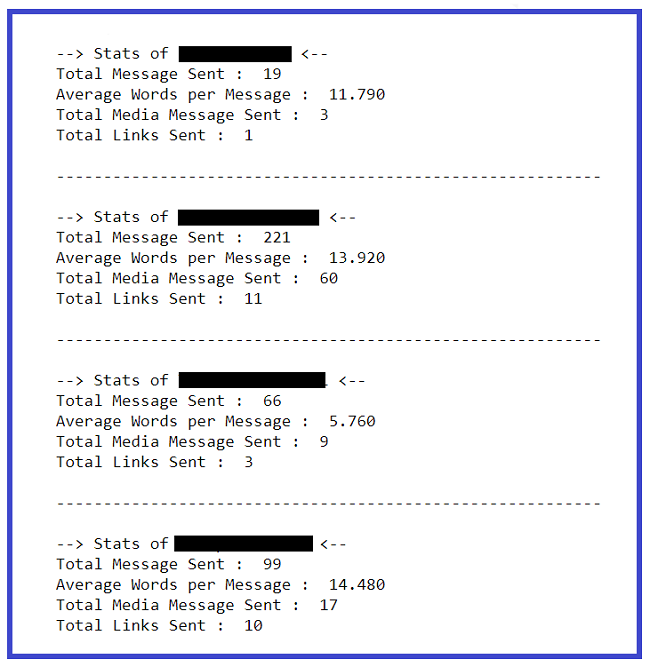
Extracting basic statistics of each user :
l = df.Author.unique()
for i in range(len(l)):
### Filtering out messages of particular user
req_df = df[df["Author"] == l[i]]
### req_df will contain messages of only one particular user
print(f'--> Stats of {l[i]} <-- ')
### shape will print number of rows which indirectly means the number of messages
print('Total Message Sent : ', req_df.shape[0])
### Word_Count contains of total words in one message. Sum of all words/ Total Messages will yield words per message
words_per_message = (np.sum(req_df['Word's']))/req_df.shape[0]
w_p_m = ("%.3f" % round(words_per_message, 2))
print('Average Words per Message : ', w_p_m)
### media conists of media messages
media = sum(req_df["Media_Count"])
print('Total Media Message Sent : ', media)
### links consist of total links
links = sum(req_df["Url_Count"])
print('Total Links Sent : ', links)
print()
print('----------------------------------------------------------n')
Let’s create a word cloud of most used words in chat :
### Word Cloud of mostly used word in our Group
text = " ".join(review for review in df.Message)
wordcloud = WordCloud(stopwords=STOPWORDS, background_color="white").generate(text)
### Display the generated image:
plt.figure( figsize=(10,5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()
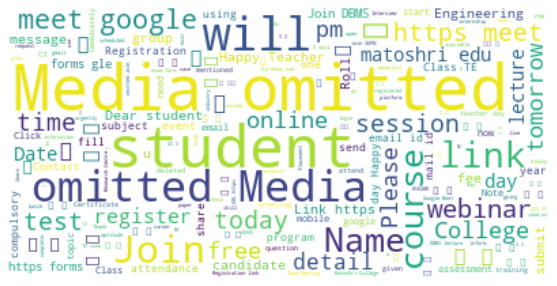
Let’s print the total no. of messages sent by each user :
### Creates a list of unique Authors l = df.Author.unique() for i in range(len(l)): ### Filtering out messages of particular user req_df = df[df["Author"] == l[i]] ### req_df will contain messages of only one particular user print(l[i],' -> ',req_df.shape[0])
Let’s print total messages sent on each day of the week :
l = df.Day.unique() for i in range(len(l)): ### Filtering out messages of particular user req_df = df[df["Day"] == l[i]] ### req_df will contain messages of only one particular user print(l[i],' -> ',req_df.shape[0])

Finally, We have extracted sufficient text information from the chat file, now let’s start the Data Visualization part which will help us for better analysis and understanding the whole analysis that we have done on our exported chat file. At the place of contact numbers, I have used alphabets due to security purposes, really sorry for that.
Let’s check who is the mostly active author of the group :
### Mostly Active Author in the Group
plt.figure(figsize=(9,6))
mostly_active = df['Author'].value_counts()
### Top 10 peoples that are mostly active in our Group is :
m_a = mostly_active.head(10)
bars = ['A','B','C','D','E','F','G','H','I','J']
x_pos = np.arange(len(bars))
m_a.plot.bar()
plt.xlabel('Authors',fontdict={'fontsize': 14,'fontweight': 10})
plt.ylabel('No. of messages',fontdict={'fontsize': 14,'fontweight': 10})
plt.title('Mostly active member of Group',fontdict={'fontsize': 20,'fontweight': 8})
plt.xticks(x_pos, bars)
plt.show()
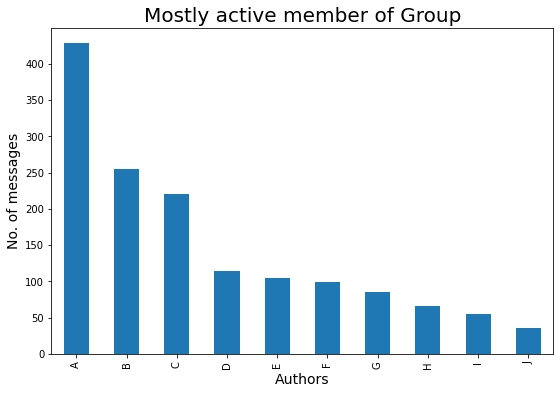
Let’s check mostly active day in a week :
### Mostly Active day in the Group
plt.figure(figsize=(8,5))
active_day = df['Day'].value_counts()
### Top 10 peoples that are mostly active in our Group is :
a_d = active_day.head(10)
a_d.plot.bar()
plt.xlabel('Day',fontdict={'fontsize': 12,'fontweight': 10})
plt.ylabel('No. of messages',fontdict={'fontsize': 12,'fontweight': 10})
plt.title('Mostly active day of Week in the Group',fontdict={'fontsize': 18,'fontweight': 8})
plt.show()

Let’s check Top-10 media contributor in the group :
### Top-10 Media Contributor of Group
mm = df[df['Message'] == '<Media omitted>']
mm1 = mm['Author'].value_counts()
bars = ['A','B','C','D','E','F','G','H','I','J']
x_pos = np.arange(len(bars))
top10 = mm1.head(10)
top10.plot.bar()
plt.xlabel('Author's',fontdict={'fontsize': 12,'fontweight': 10})
plt.ylabel('No. of media',fontdict={'fontsize': 12,'fontweight': 10})
plt.title('Top-10 media contributor of Group',fontdict={'fontsize': 18,'fontweight': 8})
plt.xticks(x_pos, bars)
plt.show()
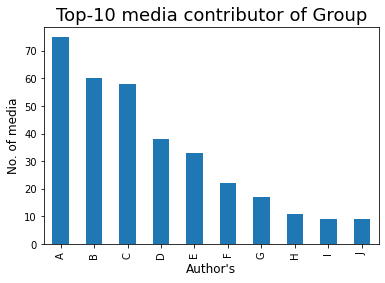
Words are off course most powerful weapon in the world, so let’s check who has this powerful weapon in the group😅 :
max_words = df[['Author','Word's']].groupby('Author').sum()
m_w = max_words.sort_values('Word's',ascending=False).head(10)
bars = ['A','B','C','D','E','F','G','H','I','J']
x_pos = np.arange(len(bars))
m_w.plot.bar(rot=90)
plt.xlabel('Author')
plt.ylabel('No. of words')
plt.title('Analysis of members who has used max. no. of words in his/her messages')
plt.xticks(x_pos, bars)
plt.show()
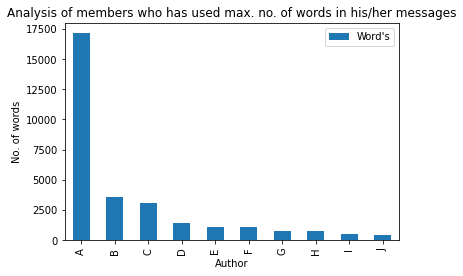
Let’s check Top-10 author who has shared maximum no. of links in the group:
### Member who has shared max numbers of link in Group
max_words = df[['Author','Url_Count']].groupby('Author').sum()
m_w = max_words.sort_values('Url_Count',ascending=False).head(10)
bars = ['A','B','C','D','E','F','G','H','I','J']
x_pos = np.arange(len(bars))
m_w.plot.bar(rot=90)
plt.xlabel('Author')
plt.ylabel('No. of link's')
plt.title('Analysis of member's who has shared max no. of link's in Group')
plt.xticks(x_pos, bars)
plt.show()
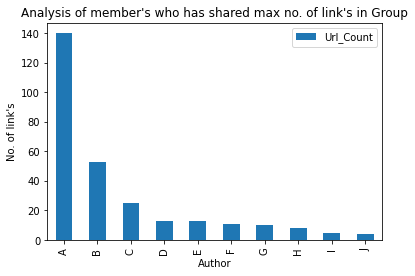
Let’s check the time whenever the group was highly active :
### Time whenever our group is highly active
plt.figure(figsize=(8,5))
t = df['Time'].value_counts().head(20)
tx = t.plot.bar()
tx.yaxis.set_major_locator(MaxNLocator(integer=True)) #Converting y axis data to integer
plt.xlabel('Time',fontdict={'fontsize': 12,'fontweight': 10})
plt.ylabel('No. of messages',fontdict={'fontsize': 12,'fontweight': 10})
plt.title('Analysis of time when Group was highly active.',fontdict={'fontsize': 18,'fontweight': 8})
plt.show()
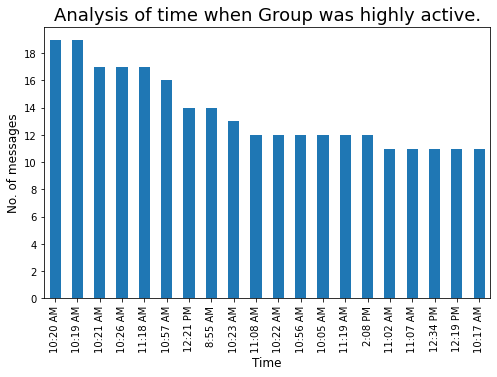
Converting 12-hour formate to 24 hours will help us for better analysis :
lst = []
for i in df['Time'] :
out_time = datetime.strftime(datetime.strptime(i,"%I:%M %p"),"%H:%M")
lst.append(out_time)
df['24H_Time'] = lst
df['Hours'] = df['24H_Time'].apply(lambda x : x.split(':')[0])
Let’s check the most suitable hour of the day whenever there will be more chances of getting a response from group members :
### Most suitable hour of day, whenever there will more chances of getting responce from group members.
plt.figure(figsize=(8,5))
std_time = df['Hours'].value_counts().head(15)
s_T = std_time.plot.bar()
s_T.yaxis.set_major_locator(MaxNLocator(integer=True)) #Converting y axis data to integer
plt.xlabel('Hours (24-Hour)',fontdict={'fontsize': 12,'fontweight': 10})
plt.ylabel('No. of messages',fontdict={'fontsize': 12,'fontweight': 10})
plt.title('Most suitable hour of day.',fontdict={'fontsize': 18,'fontweight': 8})
plt.show()
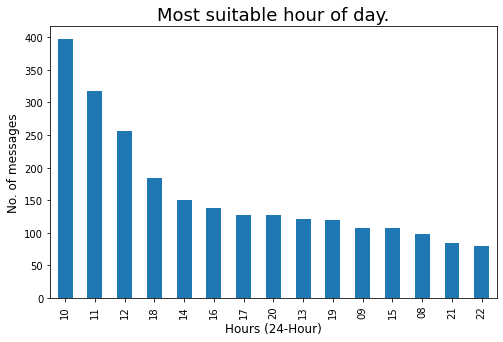
Let’s create a word cloud of Top-10 highly active members:
active_m = [list of Top-10 highly active members]
for i in range(len(active_m)) :
# Filtering out messages of particular user
m_chat = df[df["Author"] == active_m[i]]
print(f'--- Author : {active_m[i]} --- ')
# Word Cloud of mostly used word in our Group
msg = ' '.join(x for x in m_chat.Message)
wordcloud = WordCloud(stopwords=STOPWORDS, background_color="white").generate(msg)
plt.figure(figsize=(10,5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()
print('____________________________________________________________________________________n')
Let’s check the date on which our group was highly active :
### Date on which our Group was highly active.
plt.figure(figsize=(8,5))
df['Date'].value_counts().head(15).plot.bar()
plt.xlabel('Date',fontdict={'fontsize': 14,'fontweight': 10})
plt.ylabel('No. of messages',fontdict={'fontsize': 14,'fontweight': 10})
plt.title('Analysis of Date on which Group was highly active',fontdict={'fontsize': 18,'fontweight': 8})
plt.show()
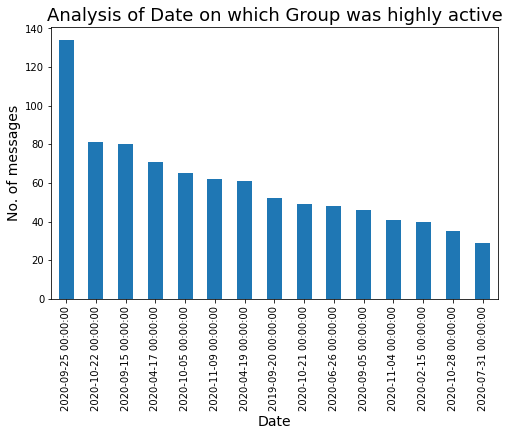
Let’s create a time series plot w.r.t. no. of messages :
z = df['Date'].value_counts()
z1 = z.to_dict() #converts to dictionary
df['Msg_count'] = df['Date'].map(z1)
### Timeseries plot
fig = px.line(x=df['Date'],y=df['Msg_count'])
fig.update_layout(title='Analysis of number of message's using TimeSeries plot.',
xaxis_title='Month',
yaxis_title='No. of Messages')
fig.update_xaxes(nticks=20)
fig.show()
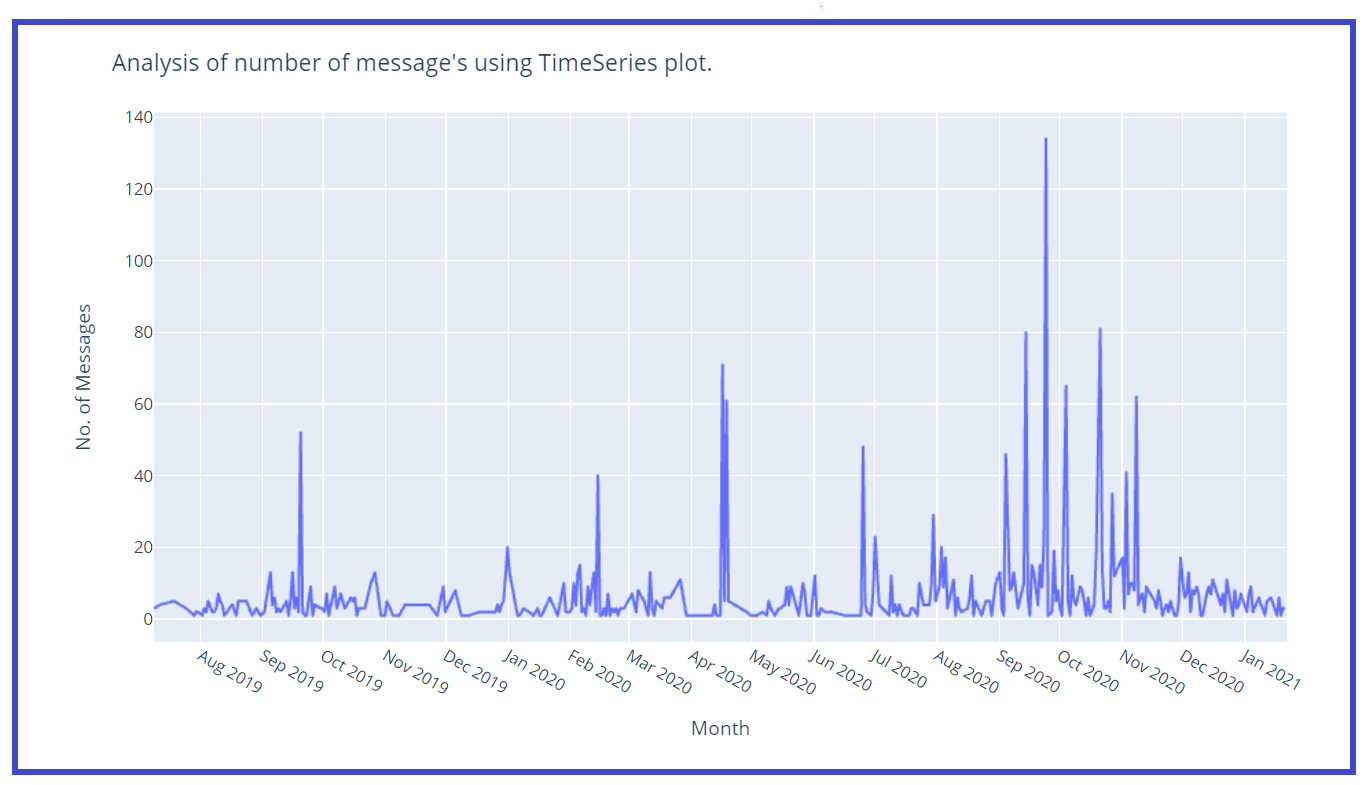
Let’s create a separate column for Month and Year for better analysis :
df['Year'] = df['Date'].dt.year
df['Mon'] = df['Date'].dt.month
months = {
1 : 'Jan',
2 : 'Feb',
3 : 'Mar',
4 : 'Apr',
5 : 'May',
6 : 'Jun',
7 : 'Jul',
8 : 'Aug',
9 : 'Sep',
10 : 'Oct',
11 : 'Nov',
12 : 'Dec'
}
df['Month'] = df['Mon'].map(months)
df.drop('Mon',axis=1,inplace=True)
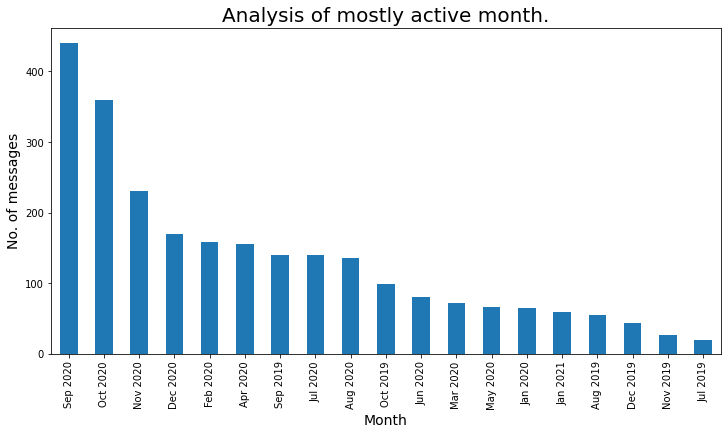
Let’s check mostly active month :
### Mostly Active month
plt.figure(figsize=(12,6))
active_month = df['Month_Year'].value_counts()
a_m = active_month
a_m.plot.bar()
plt.xlabel('Month',fontdict={'fontsize': 14,'fontweight': 10})
plt.ylabel('No. of messages',fontdict={'fontsize': 14,'fontweight': 10})
plt.title('Analysis of mostly active month.',fontdict={'fontsize': 20,
'fontweight': 8})
plt.show()
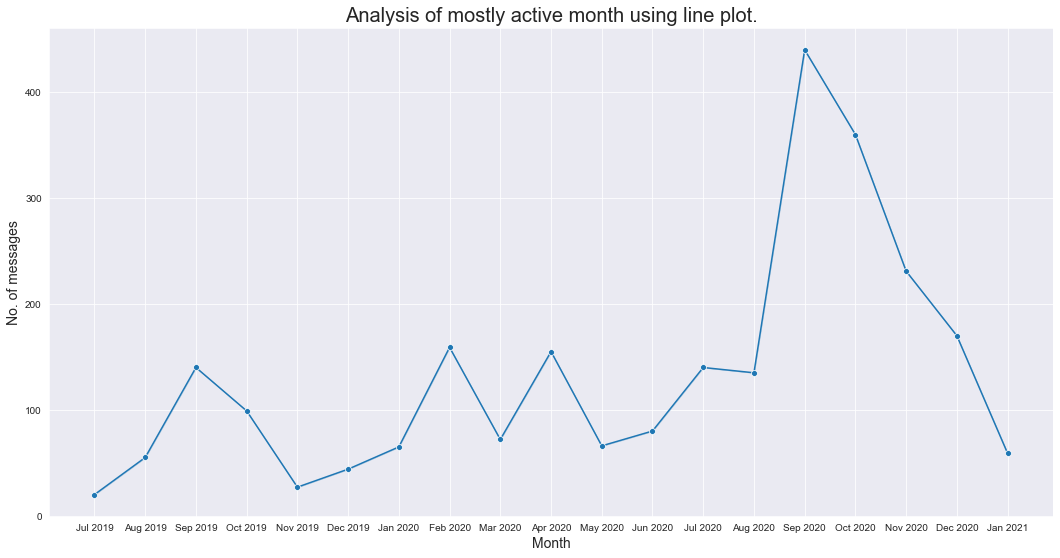
Let’s analyze the most active month using a line plot :
z = df['Month_Year'].value_counts()
z1 = z.to_dict() #converts to dictionary
df['Msg_count_monthly'] = df['Month_Year'].map(z1)
plt.figure(figsize=(18,9))
sns.set_style("darkgrid")
sns.lineplot(data=df,x='Month_Year',y='Msg_count_monthly',markers=True,marker='o')
plt.xlabel('Month',fontdict={'fontsize': 14,'fontweight': 10})
plt.ylabel('No. of messages',fontdict={'fontsize': 14,'fontweight': 10})
plt.title('Analysis of mostly active month using line plot.',fontdict={'fontsize': 20,'fontweight': 8})
plt.show()
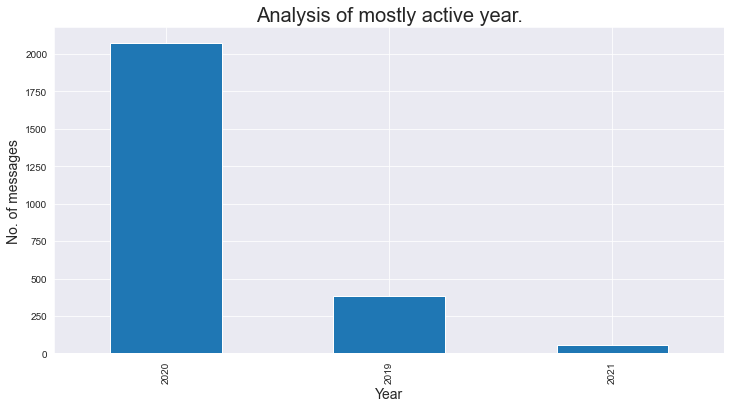
Let’s check the total message per year :
### Total message per year
### As we analyse that the group was created in mid 2019, thats why number of messages in 2019 is less.
plt.figure(figsize=(12,6))
active_month = df['Year'].value_counts()
a_m = active_month
a_m.plot.bar()
plt.xlabel('Year',fontdict={'fontsize': 14,'fontweight': 10})
plt.ylabel('No. of messages',fontdict={'fontsize': 14,'fontweight': 10})
plt.title('Analysis of mostly active year.',fontdict={'fontsize': 20,'fontweight': 8})
plt.show()
Let’s use a heatmap and analyze highly active Day w.r.t. Time :
df2 = df.groupby(['Hours', 'Day'], as_index=False)["Message"].count()
df2 = df2.dropna()
df2.reset_index(drop = True,inplace = True)
### Analysing on which time group is mostly active based on hours and day.
analysis_2_df = df.groupby(['Hours', 'Day'], as_index=False)["Message"].count()
### Droping null values
analysis_2_df.dropna(inplace=True)
analysis_2_df.sort_values(by=['Message'],ascending=False)
day_of_week = ['Monday', 'Tuesday', 'Wednesday', 'Thrusday', 'Friday', 'Saturday', 'Sunday']
plt.figure(figsize=(15,8))
heatmap(
x=analysis_2_df['Hours'],
y=analysis_2_df['Day'],
size_scale = 500,
size = analysis_2_df['Message'],
y_order = day_of_week[::-1],
color = analysis_2_df['Message'],
palette = sns.cubehelix_palette(128)
)
plt.show()
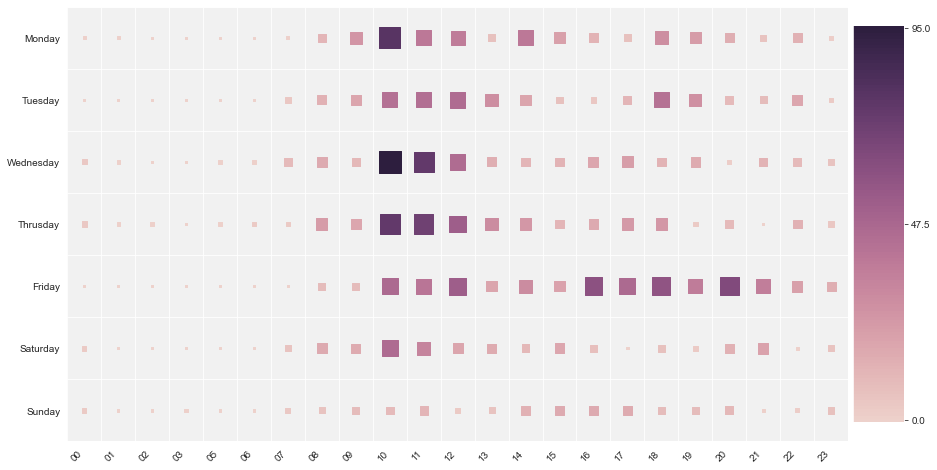
From the above heat map we analyze that on “Monday” between 10:00 to 10:59, our group was
highly active, similarly on “Wednesday” between 10:00 to 10:59, our group was
highly active. Between 00:00 to 08:00 group was less active.
EndNote :
I hope this article really helps you to create your own WhatsApp Chat Analyzer and analyze the pattern in the group.
I hope you enjoyed this article. Any question? Have I missed something? Please reach me out on my LinkedIn. And finally, …it doesn’t go without saying,
Thank you for reading!
Cheers!!!
Ronil
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.





Great article. I already tried something like this a while back. Check it out here: https://github.com/kartheekpnsn/chat-explore
hey, this is the super-duper post. I really like it. also, I guess a lot of people spend all their time in WhatsApp groups.
I use this in good job only