This article was published as a part of the Data Science Blogathon.
Data is everywhere. Nowadays, every device with some logical system is producing and storing Data in its relevant format. The data produced is of no use until some meaningful or interesting insights are not extracted. Not every time an insight will be meaningful but we as Analysts can try once.
Today I have picked one product from one of the most Data Collecting companies, Google’s product, Fit. The Fit application is a health-tracking application that estimates the number of steps, calories burned, heart points, moving minutes, and much more activities without the need for any external fitness devices. I personally have used both Mi Band 3 and Fit app and the apps give almost the same results. You can also synchronize any external tracking device with the Fit app.
Google collects a large amount of data at the user’s discretion but have you ever accessed that data? Let me guide you on how to download the google fit data and we do an analysis of the Fitness data collected by the Fit application.
Getting the Data From Google Fit for Analysis
This is a pretty simple process. Google has made it very easy to access and download our data. Just follow these steps:
Go to this link: takeout.google.com
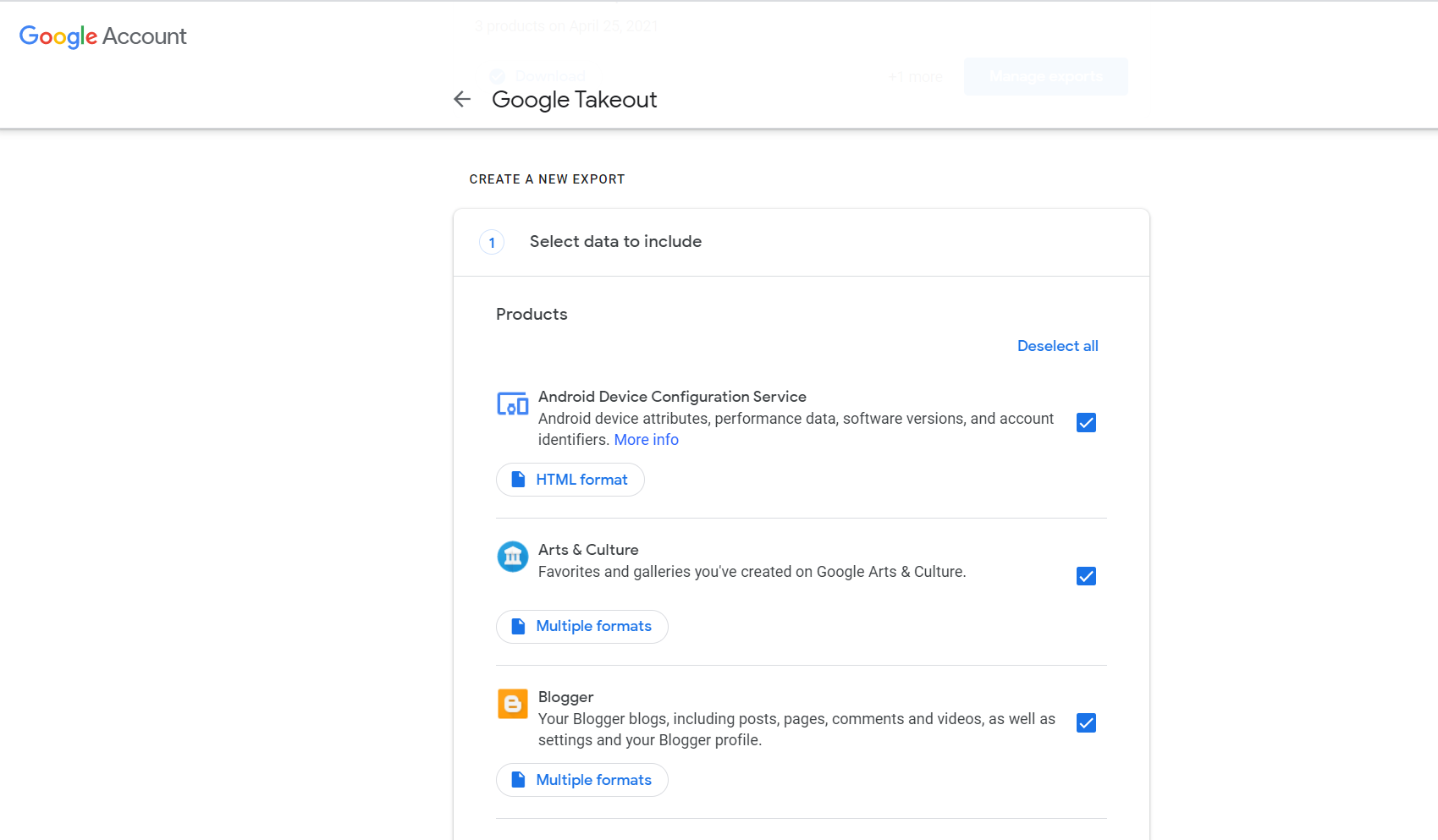
On this, click on “deselect all” as we don’t want to download all of our data and we are only interested in getting specific app data. Scroll down below and you will see a list of all services from which you can get the data. Now select the Fit:
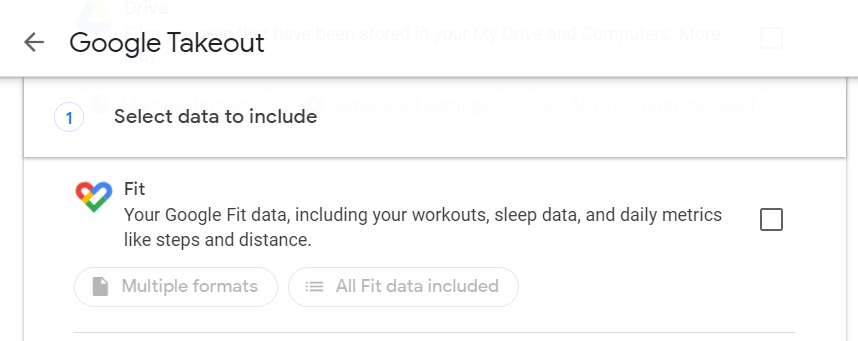
Scroll down to the bottom and click the next step. In step 2, leave everything as defaults and then click create the export. You can customize the data frequency to 2 months every month depending upon your use case. For this example, I have exported the data only once (default):
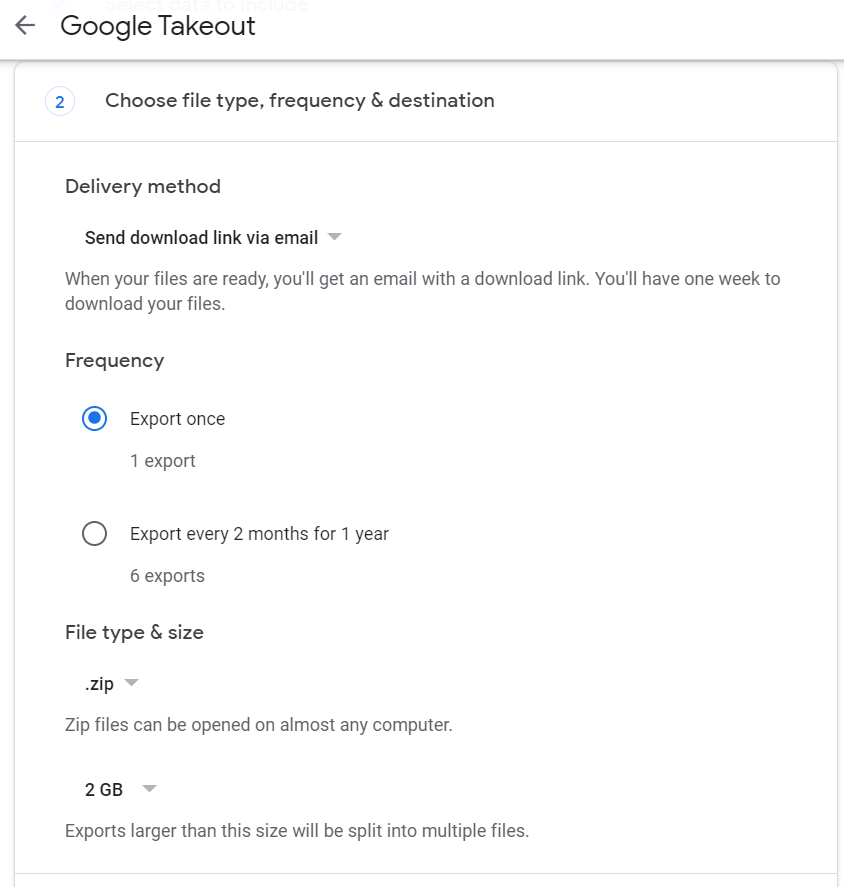
You will receive a mail shortly depending upon the volume of your data. It usually takes 5-10 minutes for the mail containing the link to download the data. You may be prompted to authenticate again (for security purposes) and after that, the data will be downloaded.
Preparing the Data For Analysis
Now that we have the potential dataset, let’s dig into the exploration part. As soon as you open the zip file, you will have a Takeout folder and inside that, you will find a folder named Fit and inside that folder, you will have 4 sub-folders:
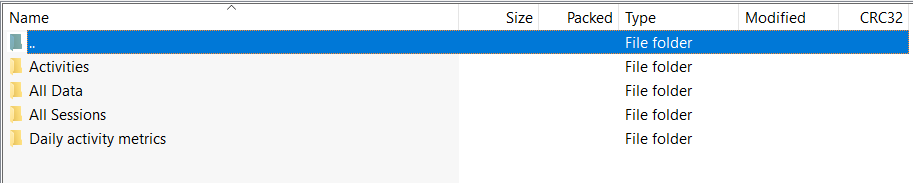
We are only interested in the “Daily activity metrics” as the “Activities” folder contains the .tcx files which are standard XML files used by fitness trackers to share tracking information. We are not going into depth about how counts were measured and we are only interested in the final value. In the “Daily activity metrics” folder you will find several CSV files dated from the date you have installed this app. Each data file contains the hourly stats of your workout for that particular date:
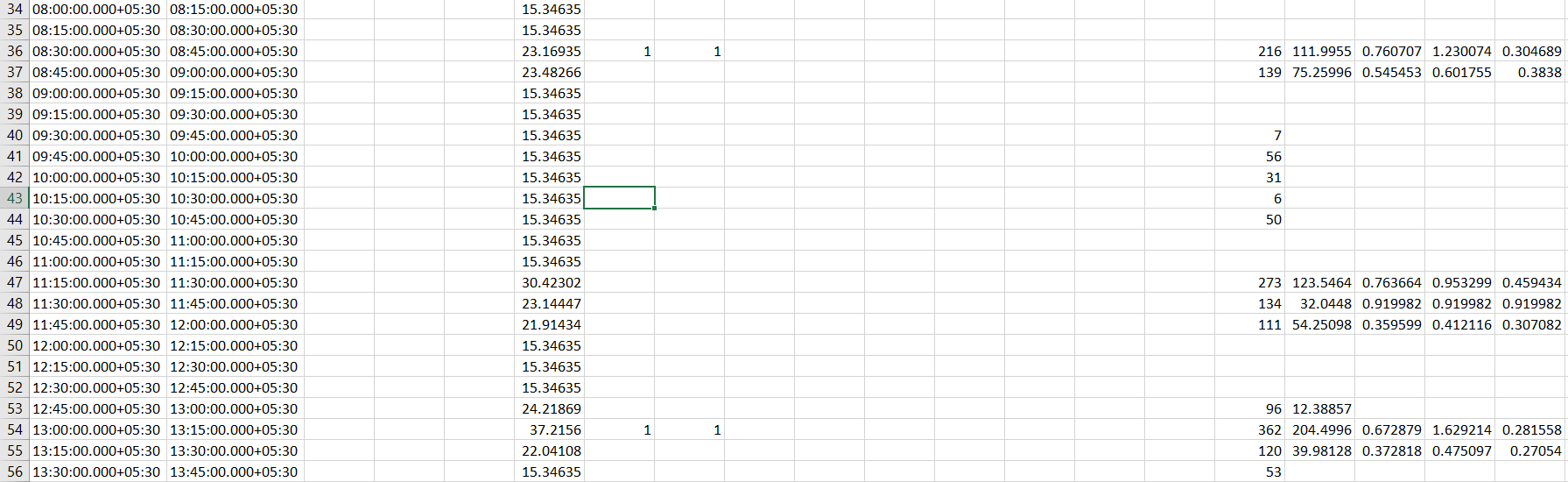
We are still not interested in these files as they are large in numbers! My data ranges from 2018 March to the present! That’s why we will use the last file in this folder, “Daily activity metrics.csv” which contains date-wise records of the workouts. Let’s load this file and explore the various columns in this:
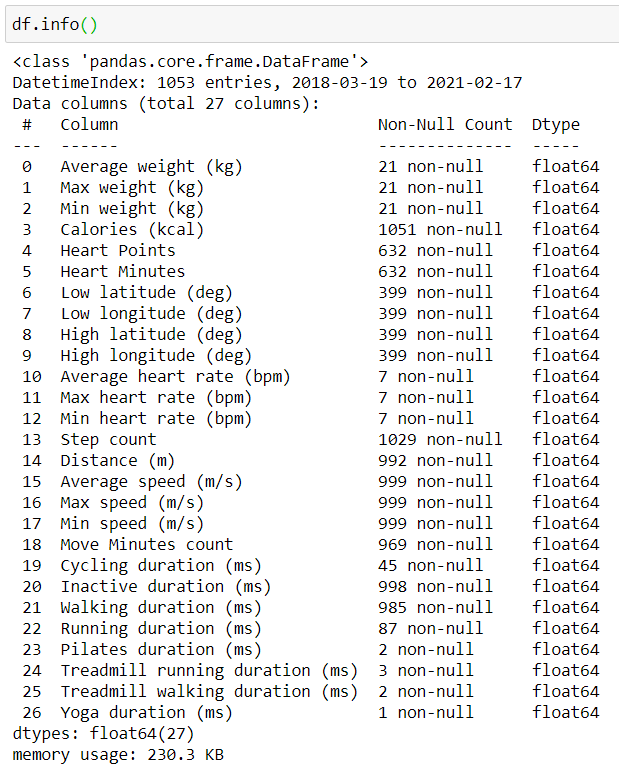
Note: I have loaded this file with index=date column and parse_dates=True so that we can access the various datetime accessors.
The first thing we will do is dropping the irrelevant columns:
df.drop(['Average weight (kg)', 'Max weight (kg)', 'Min weight (kg)', 'Average heart rate (bpm)', 'Min heart rate (bpm)', 'Max heart rate (bpm)'], inplace=True, axis=1)
Next, we will extract all the dates months, day of the week, and year. You can do this manually by creating a custom function to split the dates at hyphen (-), then checking the month and the corresponding year, there is a formula and process for this but the pandas module makes it easier by providing us abstract functions to directly obtain the results. Remember that I have enabled the parse_dates= True while reading CSV? I did this on purpose so that we can convert these dates into date-time pandas format which provides us the access methods. This is how we will access and store these data:
df["workoutMonth"] = df.index.month_name() df["workoutWeekDay"] = df.index.day_name() df["workoutYear"] = df.index.year
Now our data is ready and it’s time to do some plotting!
Plotting The Data
Plotting and visualization is my favorite part. It allows us to clearly present the trends of the data and tries to summarise the data in the form of charts, figures, numbered axis, or portions of a category in case of categorical data. I have chosen Plotly as the plotting library. This library allows us to create interactive plots with minimal effort. The plots are interactive due to JavaScript integrations but we don’t need to know the backend part. The syntax for this is very similar to existing libraries such as matplotlib and seaborn which can also produce plots but they are static and users cannot interact with them.
import plotly.express as px import plotly.graph_objects as go
Let’s start exploring some of the common questions:
I am assuming that when the step count is greater than 2000 steps, that was a valid workout. For this, I am filtering the data frame using this code: df = df[df[“Step count”] > 2000]
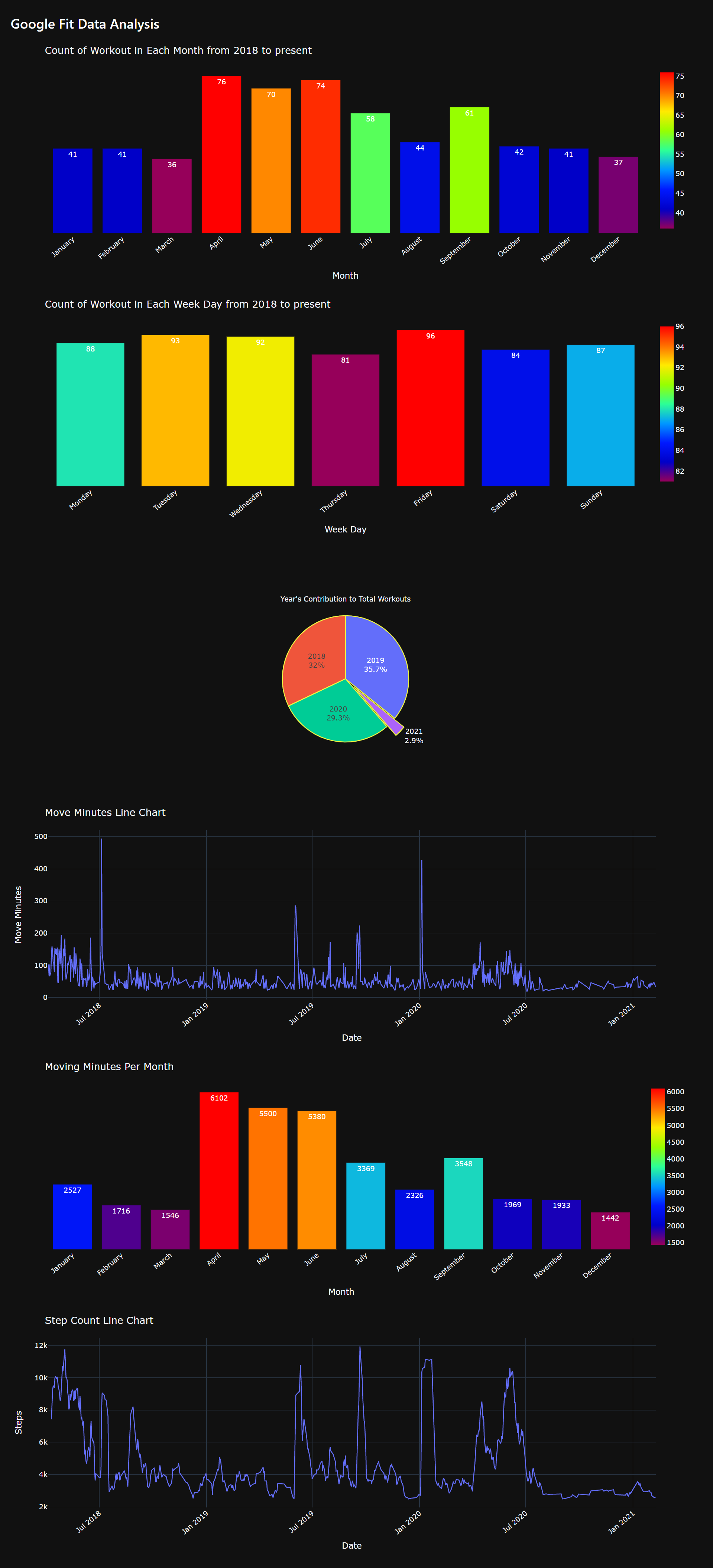
1. How many workouts were performed based on Months?
temp1 = df.workoutMonth.value_counts()
months = ('January', 'February', 'March', 'April', 'May', 'June', 'July', 'August', 'September', 'October', 'November', 'December')
month_value = tuple(temp1[i] for i in months)
fig = px.bar(temp1,
x=months,
y=month_value,
color=month_value,
text=month_value,
color_continuous_scale='Rainbow',
labels={'color':''}
)
fig.update_layout(
title = "Count of Workout in Each Month from 2018 to present",
xaxis_title='Month',
yaxis_title='Number of Workouts',
xaxis_tickangle=-40,
yaxis={'visible': False, 'showticklabels': False},
font=dict(size=15)
)
fig.show()
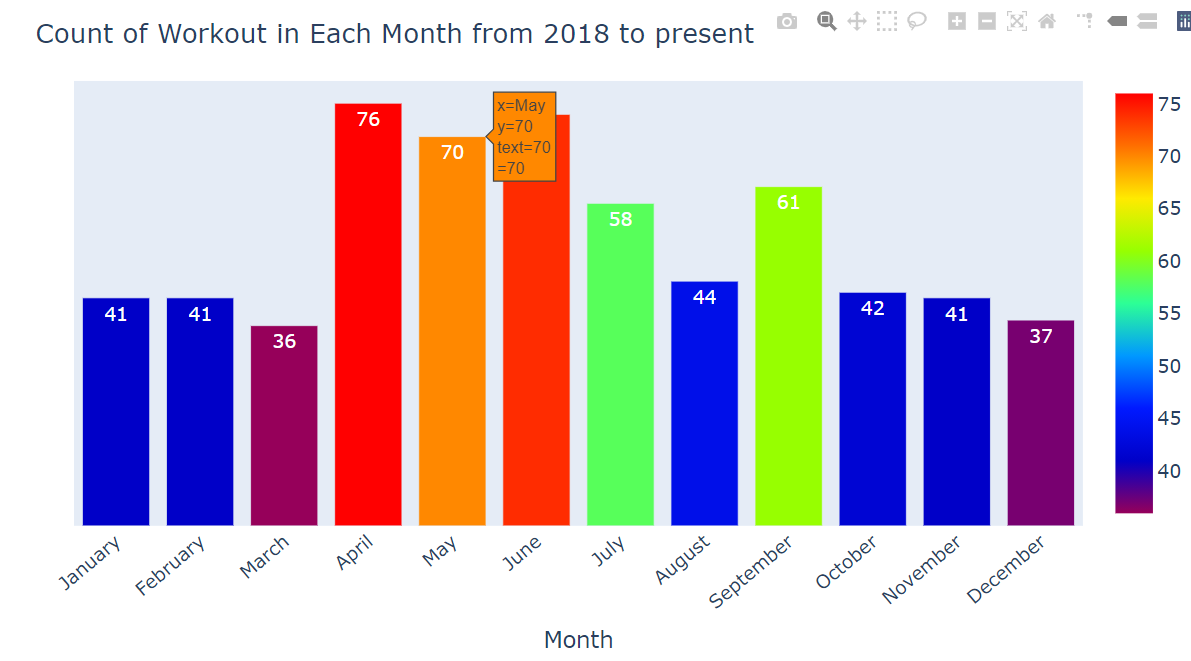
2. How many workouts were performed based on Weekdays?
temp2 = df.workoutWeekDay.value_counts()
months = ('Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday')
month_value = tuple(temp2[i] for i in months)
fig = px.bar(temp2,
x=months,
y=month_value,
color=month_value,
text=month_value,
color_continuous_scale='Rainbow',
labels={'color':''}
)
fig.update_layout(
title = "Count of Workout in Each Week Day from 2018 to present",
xaxis_title='Week Day',
yaxis_title='Number of Workouts',
xaxis_tickangle=-40,
yaxis={'visible': False, 'showticklabels': False},
font=dict(size=15)
)
fig.show()
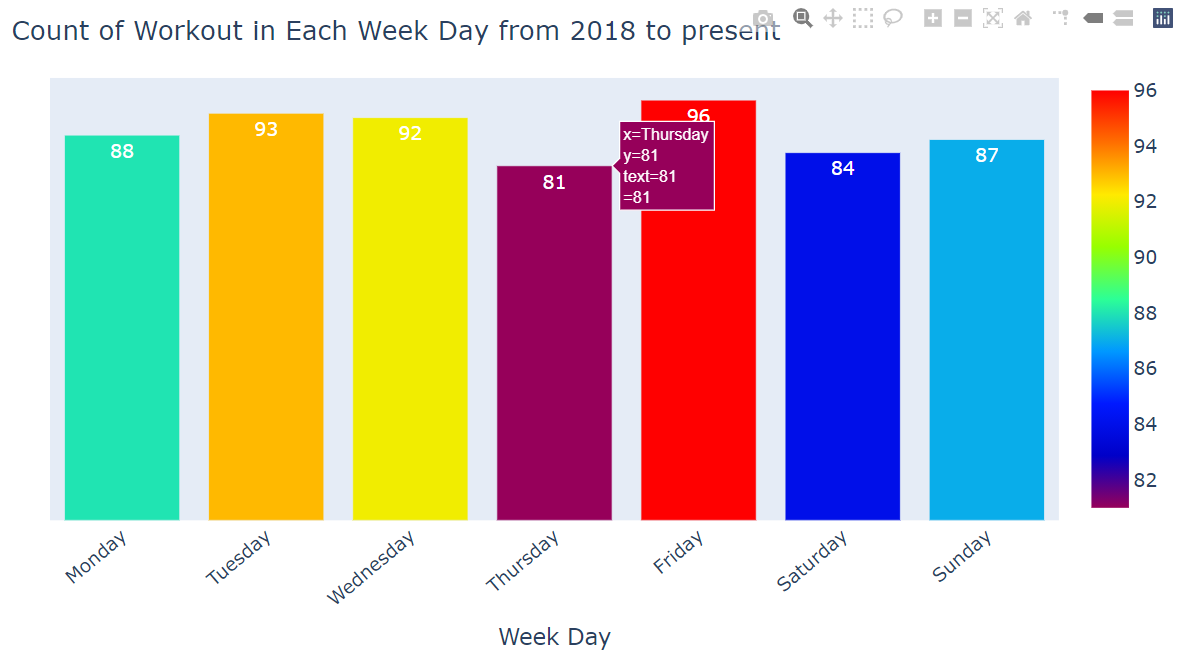
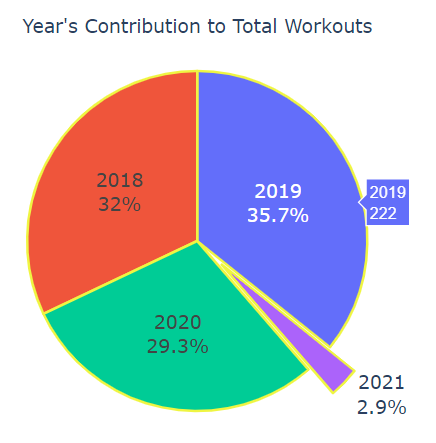
3. What was the yearly distribution of workouts?
temp3 = df.workoutYear.value_counts()
fig = go.Figure(data=[go.Pie(labels=temp3.index,
values=temp3.values,
textinfo='label+percent',
pull=[0, 0, 0, 0.2],
title="Year's Contribution to Total Workouts"
)])
fig.update_traces(hoverinfo='label+value', textfont_size=15,
marker=dict(line=dict(color='#eff542', width=2)), showlegend=False)
fig.update_layout(font=dict(size=15))
fig.show();
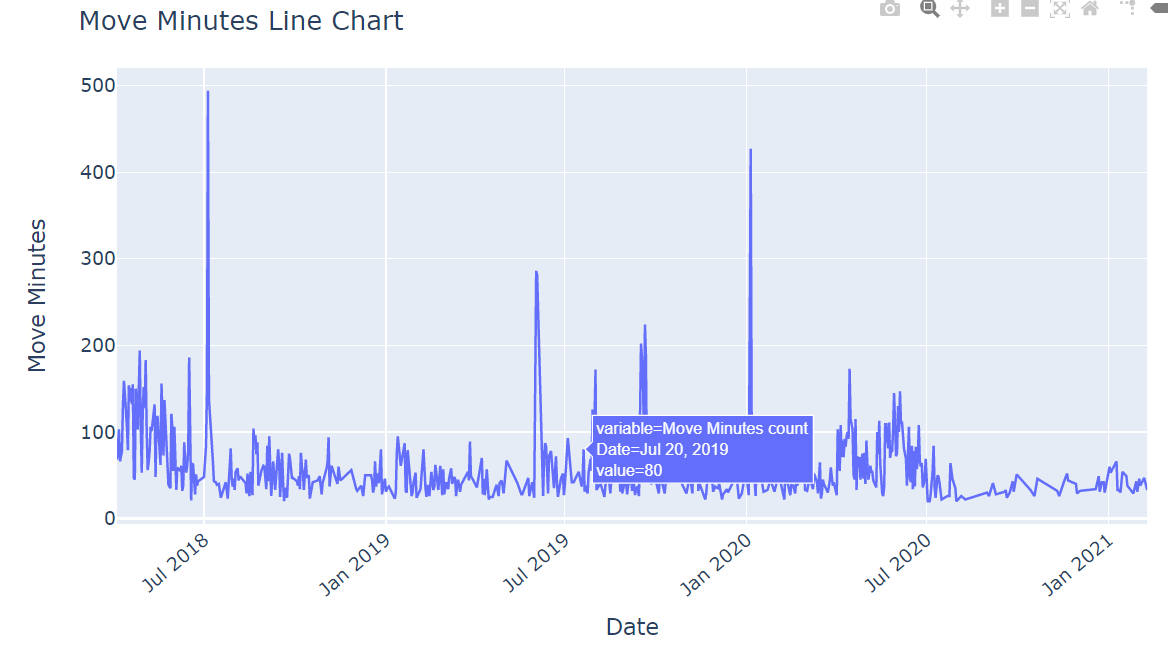
4. What is the activity in terms of Move Minutes (These represent the total moving time of the user)?
fig = px.line(df["Move Minutes count"])
fig.update_layout(
title = "Move Minutes Line Chart",
yaxis_title='Move Minutes',
xaxis_tickangle=-40,
font=dict(size=15),
showlegend=False
)
fig.show()
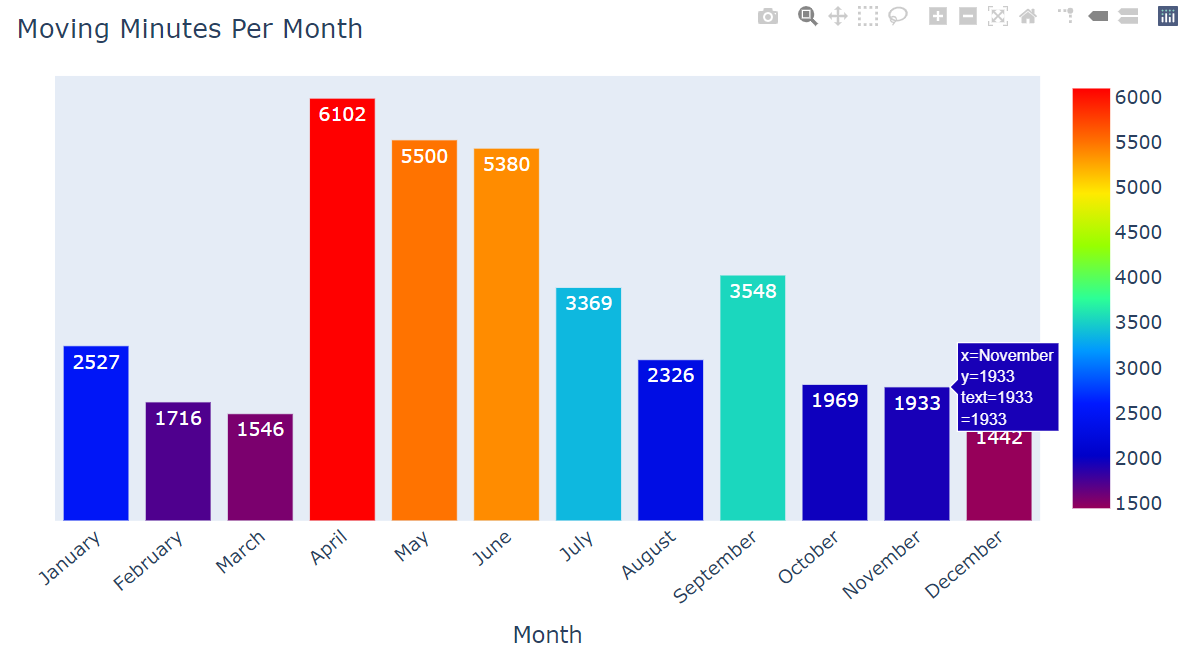
5. Which Month contributed the maximum to moving minutes?
temp3 = df.groupby("workoutMonth")['Move Minutes count'].sum()
months = ('January', 'February', 'March', 'April', 'May', 'June', 'July', 'August', 'September', 'October', 'November', 'December')
month_value = tuple(temp3[i] for i in months)
fig = px.bar(temp3,
x=months,
y=month_value,
color=month_value,
text=month_value,
color_continuous_scale='Rainbow',
labels={'color':''}
)
fig.update_layout(
title = "Moving Minutes Per Month",
xaxis_title='Month',
yaxis_title='Moving Minutes',
xaxis_tickangle=-40,
yaxis={'visible': False, 'showticklabels': False},
font=dict(size=15)
)
fig.show()
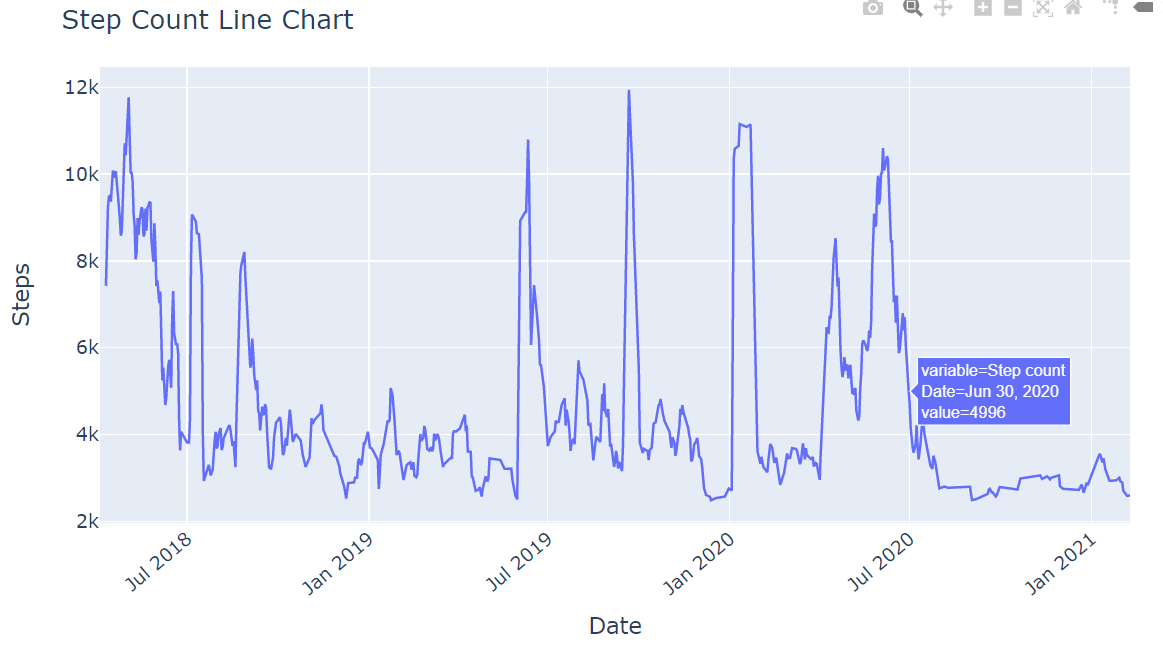
6. What does the step count plot look like?
In this approach, I have used rolling mean over a window size of 7. This is done to smoothen the short variations in the curve and highlight the trend in the data.
fig = px.line(df["Step count"].rolling(window=7).mean())
fig.update_layout(
title = "Step Count Line Chart",
yaxis_title='Steps',
xaxis_tickangle=-40,
font=dict(size=15),
showlegend=False
)
fig.show()
An Extra Step
In my previous blog in Analytics Vidhya, I have introduced 8 Python libraries that you should not miss and try them at least one time.
Article Link: You Cannot Miss These 8 Python Libraries
Now it’s time to use one of them, Voila. It converts the standard Jupyter Notebooks into a standalone web app. I have made all the graphs in dark mode by adding a small code in every plot:
fig.layout.template = 'plotly_dark'
And the output for this looks like this:
You can run this notebook here (mybinder deployment) and you can find all the codes discussed in this article at this repository.
Conclusion
There could be many possible visualizations from the dataset available but I found these interesting. Let me know in the comment section about this and If you have any doubts, queries, or potential opportunities, then you can reach out to me via
1. Linkedin – in/kaustubh-gupta/
2. Twitter – @Kaustubh1828
3. GitHub – kaustubhgupta
4. Medium – @kaustubhgupta1828
The media shown in this article on Google Fit Data Analysis are not owned by Analytics Vidhya and is used at the Author’s discretion.
Kaustubh Gupta is a skilled engineer with a B.Tech in Information Technology from Maharaja Agrasen Institute of Technology. With experience as a CS Analyst and Analyst Intern at Prodigal Technologies, Kaustubh excels in Python, SQL, Libraries, and various engineering tools. He has developed core components of product intent engines, created gold tables in Databricks, and built internal tools and dashboards using Streamlit and Tableau. Recognized as India’s Top 5 Community Contributor 2023 by Analytics Vidhya, Kaustubh is also a prolific writer and mentor, contributing significantly to the tech community through speaking sessions and workshops.



