This article was published as a part of the Data Science Blogathon.
Introduction
If you are working in the field of Machine Learning or Data science then you are definitely at the right place. Selecting the best model for your Machine Learning problem statement is one of the difficult tasks.
First, you have to import all the libraries then tune the parameters, then compare all the models, then check the model performance using different objectives. This process takes a lot of time. To avoid this problem, Lazy Predict comes into the picture.
What is Lazy Predict?
It is one of the best python libraries that helps you to semi-automate your Machine Learning Task. It builds a lot of basic models without much code and helps understand which models work better without any parameter tuning.
Suppose we have a problem statement and we really need to apply all the models on that particular dataset and we have to analyze that how our basic model is performing. Here basic model means “Model without parameters”. So we can do this task directly using Lazy Predict. After getting all accuracy we can choose the top 5 models and then apply hyperparameter tuning to them. It provides a Lazy Classifier to solve the classification problem and Lazy Regressor to solve the regression problem.
To dig deeper into this library you can refer to the documentation here.
Installation
pip install lazypredict
Usage :
### To use lazypredict in your problem statement. import lazypredict
Solving Breast Cancer Problem(Classification) Statement using Lazy Predict
Dataset Description: Here we are using Breast Cancer Dataset in which we have to predict whether a person suffering from cancer or not.
Attribute Information :
- radius (mean of distances from the center to points on the perimeter).
- texture (standard deviation of gray-scale values).
- perimeter.
- area.
- smoothness (local variation in radius lengths).
- compactness (perimeter^2 / area – 1.0).
- concavity (severity of concave portions of the contour).
- concave points (number of concave portions of the contour).
- symmetry.
- fractal dimension (“coastline approximation” – 1).
The mean, standard error, and “worst” or largest (mean of the three largest values) of these features were computed for each image, resulting in 30 features. For instance, field 3 is Mean Radius, field 13 is Radius SE, field 23 is Worst Radius. All feature values are recoded with four significant digits. Missing attribute values are none. Class distribution is 357 benign and 212 are malignant.
Benign means a person is not suffering from cancer, whereas malignant means a person is suffering from cancer.
Let’s start the coding part:
Let’s import the required library:
### importing lazypredict library import lazypredict ### importing LazyClassifier for classification problem from lazypredict.Supervised import LazyClassifier ### importing LazyClassifier for classification problem because here we are solving Classification use case. from lazypredict.Supervised import LazyClassifier ### importing breast Cancer Dataset from sklearn from sklearn.datasets import load_breast_cancer ### spliting dataset into training and testing part from sklearn.model_selection import train_test_split
Let’s load the dataset:
Here we are using Breast Cancer Dataset available in the sklearn library.
### storing dataset in data variable data = load_breast_cancer()
Let’s separate out dependent and independent features:
### separating dataset into dependent and independent features X = data.data y = data.target
Let’s split the dataset into the training and testing part:
### splitting dataset into training and testing part(50% training and 50% testing) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.5, random_state =123)
Let’s create an object of LazyClassifier class:
clf = LazyClassifier(verbose=0, ignore_warnings=True, custom_metric = None)
Let’s fit our training and testing data to the LazyClassifier object:
### fitting data in LazyClassifier models,predictions = clf.fit(X_train, X_test, y_train, y_test) ### lets check which model did better on Breast Cancer Dataset print(models)
Here “clf” is returning two values, Model and Prediction, whereas model means all the models and with some metrics and prediction means all the predicted value that is ŷ.
In the above code, you can check out the documentation of the LazyClassifier() function and play with the parameters.
Here clf.fit() is returning us two values one is model, which means how many models LazyClassifier being applied. Here Predictions mean all the parameters that it will give such as accuracy, f1 score, recall, or AUC. Suppose one of the models gives us an error then it will give us a warning.
From the above models, we can pick the top 10 models and train them or tune the parameters for better accuracy.
Solving Boston House Price Prediction(Regression) Problem using Lazy Predict :
Dataset Description: Here we are using the Boston House Price Prediction dataset which is actually a regression problem, where each record in the database describes a Boston suburb or Town. The data are drawn from the Boston Standard Metropolitan Statistical Area in 1970. The attribute is defined as follows (taken from the UCI Machine Learning Repository1): CRIM: per capita rate by town.
Attribute Information:
- ZN: proportion of residential land zoned for lots over 25,000 sq.ft.
- INDUS: proportion of non-retail business acres per town.
- CHAS: Charles River dummy variable (= 1 if tract bounds river; 0 otherwise).
- NOX: nitric oxide concentration (parts per 10 million).
- RM: average number of rooms per dwelling.
- AGE: proportion of owner-occupied units built prior to 1940.
- DIS: weighted distances to five Boston employment centers.
- RAD: index of accessibility to radial highways.
- TAX: full-value property-tax rate per $10,000.
- PTRATIO: pupil-teacher ratio by town.
- B: 1000(Bk−0.63)2 where Bk is the proportion of blacks by town.
- LSAT: % lower status of the population.
- MEDV: Median value of owner-occupied homes in $1000s.
We can see that the input attributes have a mixture of units.
Let’s start the coding part:
Let’s import all required library:
### Importing LazyRegressor from lazypredict.Supervised import LazyRegressor ### Importing dataset available in sklearn from sklearn import datasets from sklearn.utils import shuffle import numpy as np
Let’s load the dataset:
### storing the Boston dataset in variable boston = datasets.load_boston()
Let’s separate out dependent and independent features:
### loading and shuffling the dataset X, y = shuffle(boston.data, boston.target, random_state=13) offset = int(X.shape[0] * 0.9)
Let’s split the dataset into the training and testing part:
### splitting dataset into training and testing part. X_train, y_train = X[:offset], y[:offset] X_test, y_test = X[offset:], y[offset:]
Let’s create an object of LazyRegressor class:
### fitting data in LazyRegressor because here we are solving Regression use case. reg = LazyRegressor(verbose=0, ignore_warnings=False, custom_metric=None)
Let’s fit our training and testing data to the LazyClassifier object:
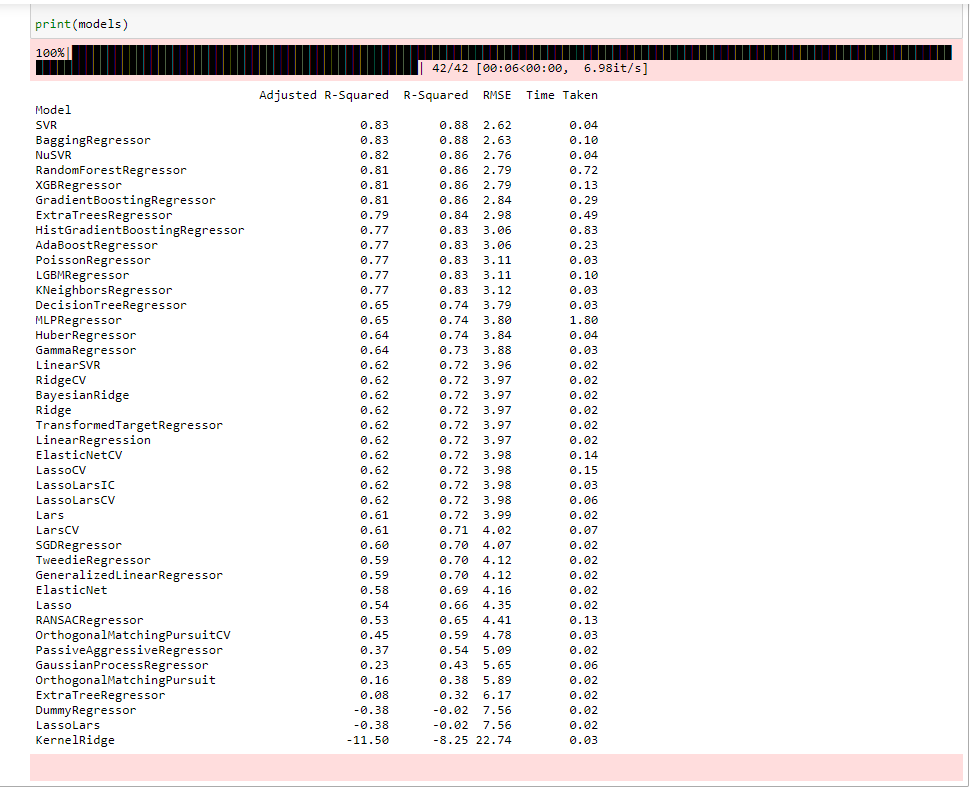
### fitting data in LazyClassifier models, predictions = reg.fit(X_train, X_test, y_train, y_test) ### lets check which model did better on Breast Cancer Dataset print(models)
Here “reg” is returning two values, Model and Prediction, whereas model means all the models and with some metrics and prediction means all the predicted value that is ŷ.
This library will fit our data on different base models. From that base models, we will select the top 10 or top 5 models then tune the parameters and get higher accuracy. Use this library in the first iteration it means before hypertuning parameters. It also works for python version > 3.6. It may take a lot of computational power that’s why use Google Colab for it.
I hope you learn something new from this article, If you really like this article, share it with your friends because “Sharing is Caring😊”.
About the Author
I am Ronil Patil, a lifelong learner. Passionate about Deep Learning, NLP, and IoT. If you have any queries or if you want any suggestions then don’t hesitate to ping me on LinkedIn, I will be happy to help you out!
And finally,… it doesn’t go without saying:
Thank you for reading!







Nice description of lazypredict. Can I request that you could explain what would be an ideal RMSE for this study or for any studies? What if your adjusted R2 and R2 are above 0.8 and if your RMSE is more than 0.6 or 0.7? Is it a good model capable of good prediction though highly accurate?