Classifying Malawi News articles into 19 different classes using SMOTE and SGDClassifier.

Introduction
Text classification is common among the application that we use on daily basis. For example, email providers use text classification to filter out spam emails from your inbox. The other most common use of text classification is in customer care where they use sentimental analysis to differentiate bad reviews from good reviews ADDI AI 2050. The modern use of text classification list goes on as we have excelled to more advanced formed of classification which includes multilanguage and multilabel classification
In recent years the English language text classification has come a long way, but training classification models on low resource language and varying lengths still pose difficulties. In this Zindi competition, we are provided with news articles written in the Chichewa language and we have to train our model on multi-label classification as there are 19 categories of news. The texts are made up of news articles of varying lengths so figuring out a better model will be the biggest challenge. – Zindi.

In this project, we will be classifying news articles in Chichewa by using the SGD classifier and SMOTE to balance our datasets. The code is simple and effective on competitive grounds. I have experimented with Vectorizer, Porter stemmer for test preprocessing. I have also used multiple methods to clean my text to improved overall model performance. In the end, I have used SKlearn SGDclassifier for predicting news classes. I have also experimented with various neural networks and gradient boosting models, but they all failed as simple logistics regression with minimum hyperparameter tunning works quite well on this data.
Code
Deepnote environment was used to train the model.
Import Libraries
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
from sklearn.model_selection import train_test_split
from sklearn.linear_model import SGDClassifier
from sklearn.preprocessing import LabelEncoder
from nltk.stem import WordNetLemmatizer
from imblearn.over_sampling import SMOTE
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
import re
import warnings
warnings.filterwarnings("ignore")
Read Train/ Test Dataset
Reading both Test and Train datasets.
The data was collected from various news publishing companies in Malawi. tNyasa Ltd Data Science Lab has used three main broadcasters: the Nation Online newspaper, Radio Maria and the Malawi Broadcasting Corporation – Zindi.
The Training Data contains three columns ID, Text: news articles, Label: classifications of news articles. The task is to classify the news articles into one of 19 classes.
As you can see train data have 1436 samples whereas the test data set to have 620 samples.
train_data = pd.read_csv("../input/malawi-news-classification-challenge/Train.csv")
test_data = pd.read_csv("../input/malawi-news-classification-challenge/Test.csv")
print(train_data.shape)
print(test_data.shape)
>> (1436, 3) >> (620, 2)
Let’s see the top two columns
train_data.head(2)
ID Text Label
0 ID_AASHwXxg Mwangonde: Khansala wachinyamata Akamati achi… POLITICS
1 ID_AGoFySzn MCP siidakhutire ndi kalembera Chipani cha Ma… POLITICS
Let’s see the bottom two columns
train_data.tail(2)
ID Text Label
1434 ID_ztdsmmva Tame Mwawa: Phwete ndiye kudya kwake Sewero l… SOCIAL ISSUES
1435 ID_zteydTpN PAC iunguza za boma la chifedulo Nthumwi zomw… POLITICS
Let’s see the Train Dataset label distribution
train_data.Label.value_counts().plot(kind='bar');
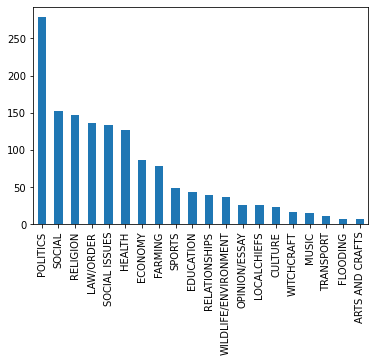
Image by Author | Figure 1
Cleaning Text
- Removing special characters improves the overall performance of the classification
model. - Lowering the text improves training time and performance metrics (analyticsvidhya.com).
- Lemmatization groups together the inflected forms of a word so they can be analyzed as a single item Lemmatisation – Wikipedia.
wn = WordNetLemmatizer()
def text_preprocessing(review):
review = re.sub('[^a-zA-Z]', ' ', review)
review = review.lower()
review = review.split()
review = [wn.lemmatize(word) for word in review if not word in chichewa]
review = ' '.join(review)
return review
Applying the text preprocessing
train_data['Text'] = train_data['Text'].apply(text_preprocessing) test_data['Text'] = test_data['Text'].apply(text_preprocessing) print(train_data.head()) print(test_data.head())
View Output
As you can see, we have much cleaner text, which is ready to be trained on our model.
ID Text Label
0 ID_AASHwXxg mwangonde khansala wachinyamata akamati achiny... POLITICS
1 ID_AGoFySzn mcp siidakhutire kalembera chipani cha malawi ... POLITICS
2 ID_AGrrkBGP bungwe la manepo lapempha boma liganizire anth... HEALTH
3 ID_AIJeigeG ndale zogawanitsa miyambo zanyanya zachilendon... POLITICS
4 ID_APMprMbV nanga wapolisi ataphofomoka masiku ano sichikh... LAW/ORDER
ID Text
0 ID_ADHEtjTi abambo odzikhweza akuchuluka kafukufuku apolis...
1 ID_AHfJktdQ ambuye ziyaye ayamikira aphunzitsi tilitonse a...
2 ID_AUJIHpZr anatcheleza akundiopseza gogo akundiopseza gog...
3 ID_AUKYBbIM ulova wafika posauzana adatenga digiri ya uphu...
4 ID_AZnsVPEi dzombe kukoma kuyambira makedzana panthawi ya ...
Text Vectorization
Term Frequency Inverse Document Frequency (TFIDF). The algorithm converts text data into a meaningful representation of numbers Medium. The transformation is necessary as the machine learning model doesn’t understand text data so we need to convert the data into a numerical format so that our model can understand. We will be converting our text data into vectors using Sklearn TFIDF transformation and our final data shape will have 49480 columns.
vectorizer = TfidfVectorizer() X = vectorizer.fit_transform(train_data['Text']).toarray() training = pd.DataFrame(X, columns=vectorizer.get_feature_names()) print(training.shape) X_test_final = vectorizer.transform(test_data['Text']).toarray() test_new = pd.DataFrame(X_test_final, columns=vectorizer.get_feature_names()) print(test_new.shape)
>> (1436, 49480) >> (620, 49480)
Preparing Data for Training
Using our train data to get X (training features) and y(Target). We will be using Label encoding to convert string labels into numerical labels such as [1,2,3….]
X = training y = train_data['Label']
Label Encoding
label_encoder = LabelEncoder() y_label = label_encoder.fit_transform(y)
Oversampling
Our data is quite unbalanced as shown in Figure 1. Politics categories have the highest number of samples, after that social and religion. This imbalance of data will cause our model to perform worst, so in order to improve model performance, we have to balance our data by either removing extra samples or using the Synthetic Minority Over-sampling Technique (SMOTE). SMOTE is an oversampling technique where the synthetic samples are generated for the minority class (analyticsvidhya.com).
In our case all the minority classes as synthesized to match majority class Politics. As you can see, all of the classes have the same number of samples, which is perfectly balanced.
smote = SMOTE() X, y_label = smote.fit_resample(X,y_label) np.bincount(y_label)
>> array([279, 279, 279, 279, 279, 279, 279, 279, 279, 279, 279, 279, 279,
279, 279, 279, 279, 279, 279, 279])
Training Model
I have used:
- Neural networks
- XGBoost
- LGBM classifiers
- Catboost
- Automl
- Logistic Regression
- Tabnet
- Random Forest Classifier
but they all failed in comparing to SGD. In short, using SGDclassification with simple hyperparameter tuning will give you the best results.
This estimator implements regularized linear models with stochastic gradient descent (SGD) learning sklearn.linear_model.SGDClassifier.
Splitting Into Train and Test: 10%Testing dataset
Using SGDClassifier: Use loss function as a hinge with alpha=0.0004, max_iter=20
X_train, X_test, y_train, y_test = train_test_split(X, y_label, test_size=0.1, random_state=0)
model = SGDClassifier(loss='hinge',
alpha=4e-4,
max_iter=20,
verbose=False)
model.fit(X_train, y_train)
SGDClassifier(alpha=0.0004, max_iter=20, verbose=False)
Evaluation
Our model performed quite well with oversampling technique. The training model without SMOTE got the highest accuracy of 55%.
pred = model.predict(X_test)
print("Train Accuracy Score:",round(model.score(X_train, y_train),2))
print("Test Accuracy Score:",round(accuracy_score(y_test, pred),2))
Train Accuracy Score: 0.99
Test Accuracy Score: 0.95
Classification Report
The classification report for every class is also amazing as the majority of the f1-score is in between 90 to 100 percentages.
print(classification_report(y_test, pred))
precision recall f1-score support
0 1.00 1.00 1.00 30
1 1.00 1.00 1.00 25
2 0.96 0.83 0.89 29
3 0.92 1.00 0.96 22
4 0.97 1.00 0.98 29
5 1.00 1.00 1.00 29
6 0.87 0.90 0.89 30
7 0.90 0.93 0.92 30
8 0.95 1.00 0.98 20
9 1.00 1.00 1.00 37
10 1.00 1.00 1.00 25
11 0.90 0.75 0.82 24
12 1.00 1.00 1.00 31
13 0.79 0.92 0.85 25
14 0.82 0.62 0.71 29
15 0.95 0.95 0.95 19
16 1.00 1.00 1.00 30
17 0.94 1.00 0.97 32
18 0.91 1.00 0.95 30
19 1.00 1.00 1.00 32
accuracy 0.95 558
macro avg 0.94 0.94 0.94 558
weighted avg 0.95 0.95 0.94 558
Confusion Matrix
We have an almost perfect confusion matric on the test dataset as you can see in Figure 2.
test_pred = label_encoder.inverse_transform(pred) test_label = label_encoder.inverse_transform(y_test) cf_matrix = confusion_matrix(test_pred, test_label) sns.heatmap(cf_matrix, annot=True);
.png)
Confusion Matrix by Author | Figure 2
Submission
It’s time to predict on the test database and create our CVS file. This file will be uploaded on Zindi serve for the final score on the hidden test dataset.
sub_pred = model.predict(test_new)
submission = pd.DataFrame()
submission['ID'] = test_data['ID']
submission['Label'] = label_encoder.inverse_transform(sub_pred)
submission.to_csv('submission.csv', index=False)

Zindi Leaderboard
Final thoughts
We got a white bad score on the test dataset. It seems my model is overfitting on both train and validation. This is the best score I got with oversampling, even though my model is overfitting, I got the best result by using SMOTE and SGDClassifier. I had fun experimenting with various machine learning models from Nural networks to Automl, but the dataset was quite small and imbalanced to get a better score and the winning solution got a 0.7 score which is not good if you want to deploy these models into production. In my opinion, focusing on data should be first priority of getting better results. This article was quite simple and beginner-friendly so that anyone can get top 50 using my code.
Unlock the power of Natural Language Processing with our comprehensive course on ‘Text Classification Model with NLP‘. Enroll now and master the skills to transform data into actionable insights!
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.
I am a technology manager turned data scientist who loves building machine learning models and research on various AI technologies. My vision is to build an AI product that will help identify students who are struggling with mental illness.






