This article was published as a part of the Data Science Blogathon.
Introduction
Hello there, learners. I hope everyone is doing well. This pandemic provides us with more opportunities to learn new topics through the work-from-home concept, allowing us to devote more time to doing so. This prompted me to consider some mundane but intriguing topics. Yes, we will learn about Unsupervised Machine Learning algorithms in this article, specifically the Associated Rule-based – Apriori algorithm. So, before delving deeper into the subject, we’ll start at the beginning and work our way up to our main topic.
Table of contents
- Introduction
- Machine Learning Overview
- Types of Machine Learning
- Association Rule-based Machine Learning
- Apriori Algorithm – Introduction
- How Apriori algorithm work?
- Apriori algorithm – Python library
- Application of Apriori algorithm
- Python Implementation of Apriori – Association Rule Algorithm
- Conclusion
- Frequently Asked Questions
Machine Learning Overview
In today’s scenario, we have one trending technology called Machine Learning or its higher version right now, in whatever domain we move on. So, what exactly is Machine Learning?
Machine Learning is the field of study that gives computers the ability to learn without being explicitly programmed. —Arthur Samuel, 1959
To put it another way, most parents used to make their children learn some basic words like apple, ball, and cat before enrolling them in kindergarten school. They teach their children to understand the objects I mentioned above by either showing a picture on a flashcard or by demonstrating the object in person or by drawing on a board or in a notebook. The main idea behind all of these methods is to teach their children to understand the word and then read it correctly. Consider systems (any gadgets) as children and their various portrayals of objects as data. Machine learning is when a system understands or observes the different data and acts accordingly, either through classification, regression, clustering, association rule-based learning, or even reinforcement learning, depending on the application. I hope that by using this analogy, everyone will understand what Machine Learning is all about. Everything from Google Search prediction, Autocorrect, weather prediction, Google assistant (or Siri or Alexa), and facial recognition requires and uses machine learning in some way.

Image 1: https://medium.com/nybles/understanding-machine-learning-through-memes-4580b67527bf
Machine learning (ML) is the scientific study of algorithms and statistical models that computer systems use to perform a specific task without using explicit instructions, relying on patterns and inference instead. – Wikipedia
So, based on the Wikipedia definition, we can deduce that Machine Learning has some close ties to statistics. If you are a Machine Learning enthusiast, you can correlate equations to statistics when working with algorithms like regression and others

And the regression concept is explained in the statistics meme as below

Machine learning is not about libraries alone, it has more mathematics that we need to understand for the practical stuff,

Types of Machine Learning
Depending on the necessity or the application, machine learning can be classified into, three broad types,
- Supervised Machine Learning – learns from labels or targets
- Unsupervised Machine Learning – no training data is required
- Reinforcement Learning – learn by itself

Unsupervised Machine Learning
In unsupervised learning, the information used to train is neither classified nor labeled in the dataset. Unsupervised learning studies how systems can infer a function to describe a hidden structure from unlabelled data. The main task of unsupervised learning is to find patterns in the data.
Once a model learns to develop patterns, it can simply anticipate patterns in the form of clusters for any new dataset. The system does not determine the correct output, but it investigates the data and can make conclusions from datasets to characterize hidden structures in unlabelled data. To be more specific, when we first start college, we don’t know who is good and who is evil. As time goes, we learn more about the person and decide to form a gang called buddies, which includes a good person, a terrible person, and a studious person.
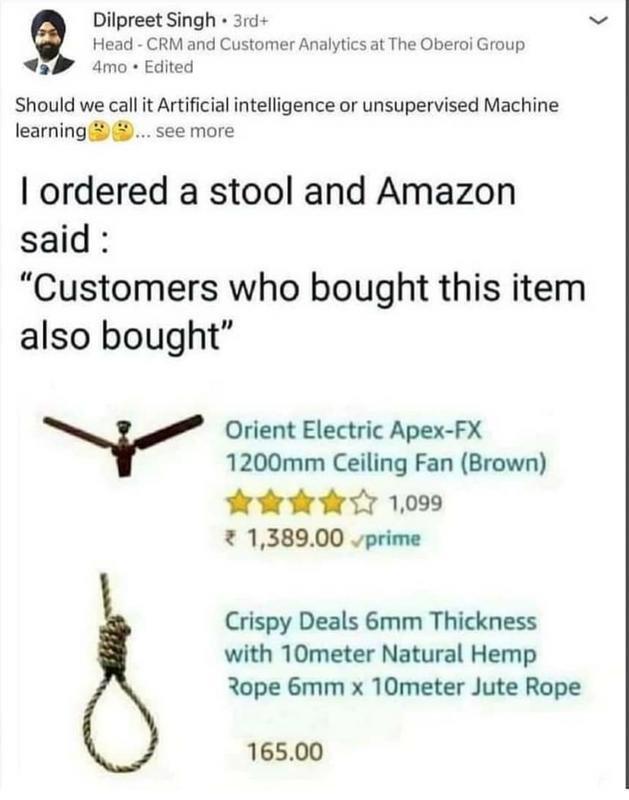
Image 6
Why is Unsupervised Machine Learning Important?
The ability of a machine to solve issues that people may think are unsolvable owing to a lack of capacity or prejudice. Exploration of raw and unknown data is ideal. It is useful for a data scientist who does not know exactly what he or she is looking for. When given data, an unsupervised machine will look for similarities between the data, namely photos, and divide them into different groups, assigning its own labels to each group. This type of algorithmic behavior is highly valuable when it comes to segmenting consumers since it can simply split data into groups without any bias that a person would have due to prior information about the nature of the data on the customers.
Types of Unsupervised Machine Learning
So, under Unsupervised Machine Learning, we have,
- Clustering
- Anomaly Detection
- Dimensionality Reduction
- Association Rules
Association Rule-based Machine Learning
The idea is to sift through massive volumes of data and find intriguing relationships between features. Consider the following scenario: you own a supermarket. An association rule applied to your sales records may disclose that consumers who buy basmati rice and chicken masala powder also buy ghee (biryani combination).
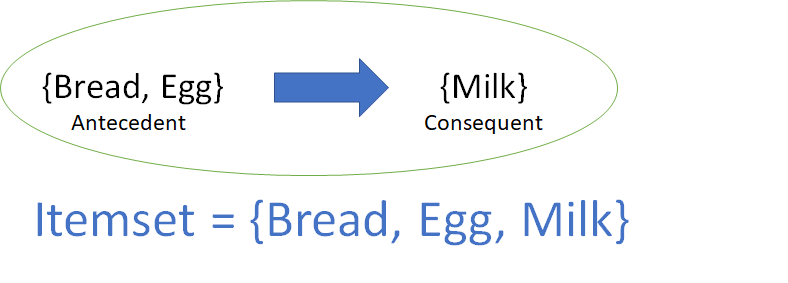
Image 7
Some algorithms are as follows:
- EcLat Algorithm
- Apriori Algorithm
Apriori Algorithm – Introduction
The main idea for the Apriori algorithm is,
All non-empty subsets of a frequent itemset must also be frequent.
Rakesh Agrawal and Ramakrishnan Srikant introduced the method originally in 1994. The Apriori algorithm, like the preceding example, detects the most frequent itemsets or elements in a transaction database and establishes association rules between the items. The method employs a “bottom-up” strategy, in which frequent subsets are expanded one item at a time (candidate generation), and groups of candidates are checked against the data. When no more successful rules can be obtained from the data, the algorithm stops.
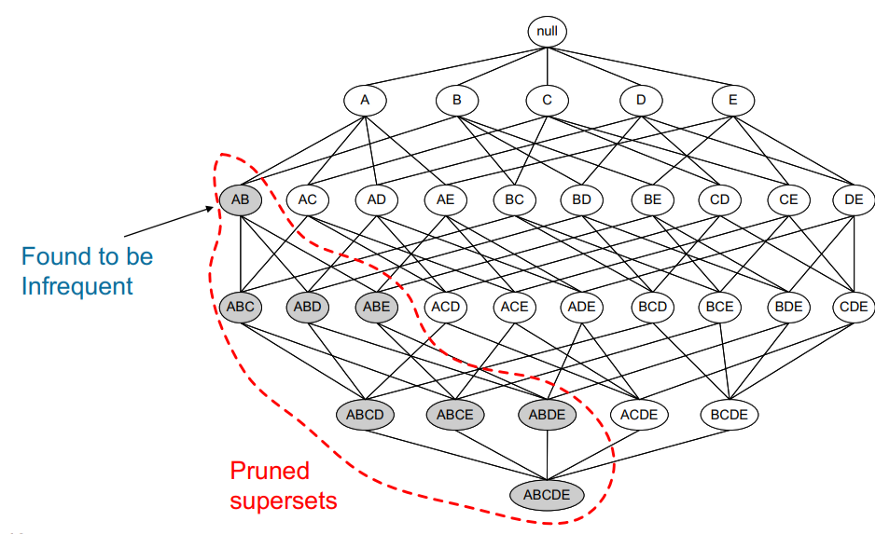
Image 8
How Apriori algorithm work?
The algorithm examines three crucial aspects while constructing association rules between components or items: support, confidence, and lift. Each of these elements is discussed below:
- Association rule: For example, X Y is a depiction of discovering Y on a basket that contains X.
- Itemset: For example, X,Y is a representation of the list of all objects that comprise the association rule.
- Support: Transactions containing the itemset as a percentage of total transactions
- Confidence: Given X, what is the likelihood of Y occurring?
- Lift: Confidence ratio to baseline likelihood of occurrence of Y
Improvements for Apriori algorithm
There are several other approaches that may be used Apriori to increase efficiency. Some of them are included in the table below.
- Reduce database scans by hashing.
- Transaction minimization entails eliminating infrequent transactions from further examination.
- Partitioning must be frequent in one of the divisions
- Reduce the number of runs through the data with Dynamic Itemset Counting.
- Sampling is the process of selecting random samples.
Apriori algorithm – Python library
Because the Apriori algorithm is not included in scikit learn, we must install it externally using the pip install apyori command. There will be two options for installation: from the command prompt or from the notebook; if you are using the notebook, simply put the! the symbol in front of the command as !pip install apyori.
Advantage of Apriori algorithm
Among association rule learning algorithms, this is the simplest and most straightforward algorithm. The resulting rules are simple to understand and express to the end-user.
Disadvantage of Apriori algorithm
The anti-monotonicity of the support measure is a crucial notion in the Apriori algorithm. It asserts that all subsets of a frequent itemset must also be frequent and that all supersets of an infrequent itemset must also be uncommon. And the main disadvantage is the slow process, to create candidates, the algorithm must continually search the database; this operation consumes a significant amount of time and memory, particularly if the pattern is very many and lengthy.
Application of Apriori algorithm
There are in many sectors, Apriori algorithms are used,
- Education sector
- Medical sector
- Forest sector
- E-Commerce sector
- Office sector
Python Implementation of Apriori – Association Rule Algorithm
Dataset: https://www.kaggle.com/devchauhan1/market-basket-optimisationcsv
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd#importing libraries
dataset = pd.read_csv('Market_Basket_Optimisation.csv', low_memory=False, header=None)
#viewing dataset
datasetdataset.head()
Image Source: Authors
dataset.shape#basic information of dataset
dataset.info()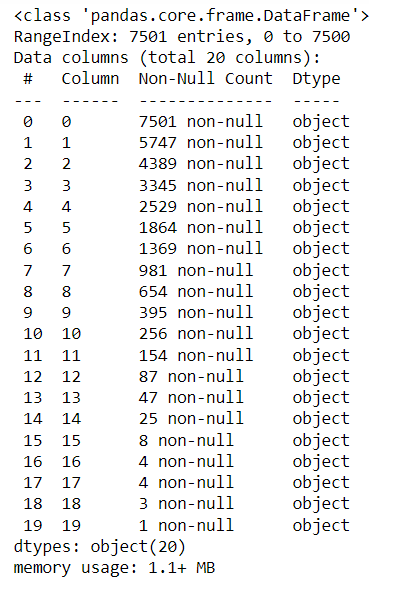
Image Source: Authors
#basic info of statistics
dataset.describe()
#viewing the uniqueness in dataset
dataset.nunique()#missing values any from the dataset
print(str('Any missing data or NaN in the dataset:'), dataset.isnull().values.any())#install APRIORI algorithm
!pip install apyori#Let's create an empty list here
list_of_transactions = []#Append the list
for i in range(0, 7501):
list_of_transactions.append([str(dataset.values[i,j]) for j in range(0, 20)])#Let's see the first element from our list of transactions. We should indicate 0 here because index in Pythn starts with 0
list_of_transactions[0]
# Training apiori algorithm on our list_of_transactions
from apyori import apriori
rules = apriori(list_of_transactions, min_support = 0.004, min_confidence = 0.2, min_lift = 3, min_length = 2)# Create a list of rules and print the results
results = list(rules)
#Here is the first rule in list or results
results[0]
#In order to visualize our rules better we need to extract elements from our results list, convert it to pd.data frame and sort strong rules by lift value.
#Here is the code for this. We have extracted left hand side and right hand side items from our rules above, also their support, confidence and lift value
def inspect(results):
lhs = [tuple(result [2] [0] [0]) [0] for result in results]
rhs = [tuple(result [2] [0] [1]) [0] for result in results]
supports = [result [1] for result in results]
confidences = [result [2] [0] [2] for result in results]
lifts = [result [2] [0] [3] for result in results]
return list(zip(lhs,rhs,supports,confidences, lifts))
resultsinDataFrame = pd.DataFrame(inspect(results),columns = ['Left Hand Side', 'Right Hand Side', 'Support', 'Confidence', 'Lift'] )
resultsinDataFrame.head(10)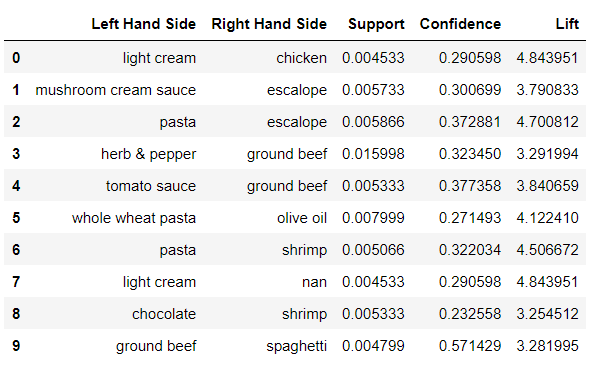
#As we have our rules in pd.dataframe we can sort it by lift value using nlargest command. Here we are saying that we need top 6 rule by lift value resultsinDataFrame.nlargest(n=10, columns='Lift')
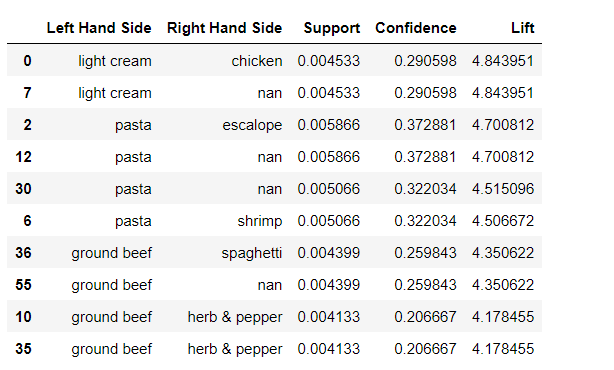
Conclusion
So, from this article, we have seen from scratch what is machine learning and its types, then a detailed study about unsupervised machine learning. Then we started with the Apriori algorithm and its necessity, how it works some theory behind the concept of association, and lastly how to improve the algorithm. I hope I have justified the topic.
Master the Art of Unsupervised Learning: Enroll in our comprehensive course and unlock the power of techniques like Apriori to transform raw data into actionable insights!
Please leave your thoughts/opinions in the comments area below. Learning from your mistakes is my favorite quote; if you find something incorrect, highlight it; I am eager to learn from students like you.
About me, in short, I am Premanand. S, Assistant Professor Jr and a researcher in Machine Learning. I love to teach and love to learn new things in Data Science. Please mail me for any doubt or mistake, [email protected], and my LinkedIn https://www.linkedin.com/in/premsanand/.
Frequently Asked Questions
Q1.Which algorithm is better than the Apriori algorithm?
FP-Growth algorithm is often considered better than Apriori for large datasets due to its efficiency
Q2.Which is better, Apriori or FP-Growth?
FP-Growth is faster and more scalable than Apriori, making it a preferred choice for mining frequent itemsets.
Q3.What is the complexity of the Apriori algorithm?
Apriori algorithm’s time complexity depends on data size, but optimizations help, and it’s practical for frequent itemset mining.
Image Sources-
- Image 1: https://medium.com/nybles/understanding-machine-learning-through-memes-4580b67527bf
- Image 2: https://www.reddit.com/r/StatisticsZone/comments/fssrnt/statistics_meme/
- Image 3: https://medium.com/nybles/understanding-machine-learning-through-memes-4580b67527bf
- Image 4: https://medium.com/nybles/understanding-machine-learning-through-memes-4580b67527bf
- Image 5: https://forum.onefourthlabs.com/t/supervised-vs-unsupervised-vs-reinforment-learning/4269
- Image 6: https://www.reddit.com/r/memes/comments/da3mi7/wondering_if_it_is_artificial_intelligence_or/
- Image 7: https://towardsdatascience.com/association-rules-2-aa9a77241654
- Image 8: https://towardsdatascience.com/apriori-association-rule-mining-explanation-and-python-implementation-290b42afdfc6
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.
Premanand S is a dedicated academic with over a decade of research experience specializing in Bio-signal Processing, Machine Learning, and Deep Learning. He earned his B.Tech in 2009 from Amrita Vishwa Vidyapeetham, Bangalore, and completed his M.E. in 2011 from Rajalakshmi Engineering College, Chennai, where his thesis focused on Deep Learning for ECG Signal Processing.
Currently pursuing his Ph.D. at VIT-Chennai, his research, titled "Deep Learning Approaches for Enhanced ECG Signal Processing and Arrhythmia Classification," aims to leverage cutting-edge deep learning techniques to improve the accuracy and efficiency of ECG signal analysis, contributing significantly to advancements in cardiac health monitoring.
A recipient of the prestigious TCS-RSP (Research Scholarship) in 2014, Cycle 9, Premanand has established himself as a recognized figure in the academic community. He has been invited to deliver talks on Data Science, Machine Learning, and Deep Learning at prominent institutions across India, sharing his expertise and insights with researchers and students alike.
As an Assistant Professor at VIT-Chennai, he continues to mentor and inspire the next generation of researchers while pushing the boundaries of knowledge in his field.






