Have you come across a hair-dresser in the saloon offering you to undergo a head massage or a hair coloring when you go for your hair-cut? How many times have you seen a more relevant product being recommended and offered at a discounted price when you make a checkout in an online store? It’s almost every time, right? And how many times have you converted the dealsto sales? Half of the times? Or even more?
Introduction – The World of Cross Selling
Hello Everyone!!! Welcome to the world of Cross selling –The Contemporary marketers most preferred way of generating more revenue from the existing clients. Wikipedia defines Cross-selling as “an action or practice of selling an additional product or service to an existing customer”. While acquiring new customers has become a costliest way (and often deadliest) to increase the revenues, it has become imperative for the businesses to enhance their growth potential from their existing clients.
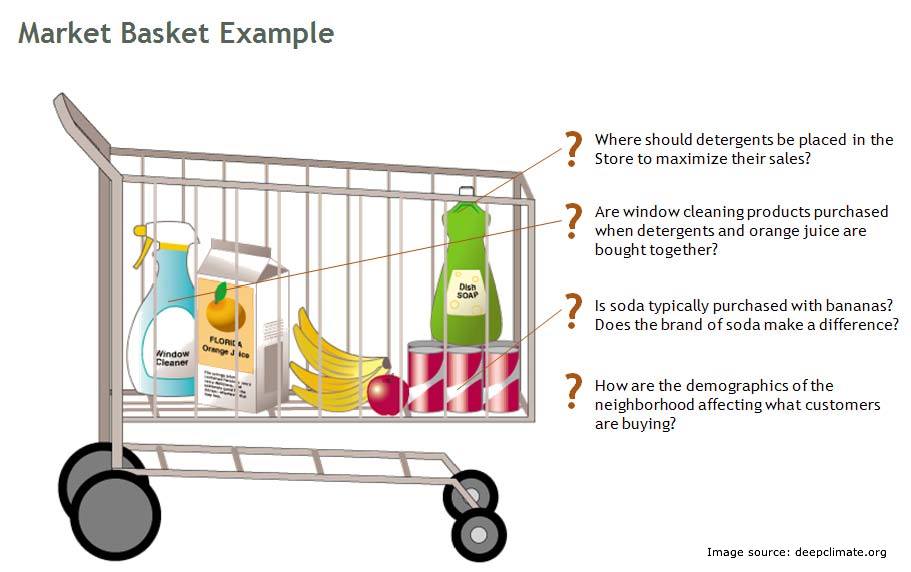
The Market Basket Analysis (MBA) Primer
Market Basket Analysis (also called as MBA) is a widely used technique among the Marketers to identify the best possible combinatory of the products or services which are frequently bought by the customers. This is also called product association analysis.Association analysis mostly done based on an algorithm named “Apriori Algorithm”. The Outcome of this analysis is called association rules. Marketers use these rules to strategize their recommendations.
To put simply Market Basket Analysis looks at the purchase coincidence with the items purchased among the transactions. i.e., what is purchased with what? For example, in a foot-wear store, a shoe is often purchased with a pair of socks. When two or more products are purchased, Market Basket Analysis is done to check whether the purchase of one product increases the likelihood of the purchase of other products. This knowledge is a tool for the marketers to bundle the products or strategize a product cross sell to a customer.
Decoding MBA with a Toy Example
In order to understand the concept better, let’s take a very simple dataset (let’s name it as Coffee dataset) consisting of very few hypothetical transactions. We will try to understand this in simple plain English.
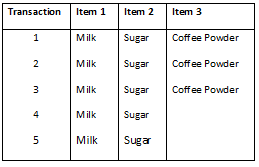
The Coffee dataset consisting of items purchased from a retail store.
Coffee dataset:
The Association Rules
For this dataset we can write the following association rules: (Rules are just for illustrations and understanding of the concept. They might not represent the actuals).
Rule 1: If Milk is purchased, Then Sugar is also purchased.
Rule 2: If Sugar is purchased, Then Milk is also purchased.
Rule 3: If Milk and Sugar is Purchased, Then Coffee powder is also purchased in 60% of the transactions.
Generally association rules are written in “IF-THEN” format. We can also use the term “antecedent” for IF and “Consequent” for THEN.
From the above rules, we understand the following explicitly:
- Whenever Milk is purchased, Sugar is also purchased or vice versa.
- If Milk and Sugar is purchased then coffee powder is also purchased. This is true in 3 out of the 5 transactions. In other words we can say that we have a support of 3 out of 5 transactions for this rule. (60% possibility).
And their insights
Based on the above insights the following marketing decisions can be made:
- A Marketer can build crossing selling strategies for wooing the remaining 40% of the customer (who did not buy coffee powder) to buy Coffee powder along with Milk and Sugar. He might bundle all these products and give at discounted price.
- A retail shop manager can stock same amount of sugar and coffee powder in his shop.
- He can place these items optimally in a store for the ease of picking by the customer.
- And much more…
Technocracy
Having said about the fundas, let us get to know about few terminologies that are using in association analysis before moving further.
The following terminologies defined are adapted from Data Mining for Business Intelligence, by GalitShmueli and others.
Frequent item set – Item set occurring in high frequency. For example in our Coffee dataset, Milk and sugar combinations occurred in 100% of the transactions.
Support – The support for the rule indicates its impact in terms of overall size. If only a small number of transactions are affected, the rule may be little use. For example, the support of “IF Milk & Sugar THEN Coffee powder” is 3/5 transactions or 60% of the total transactions.
Confidence – It determines the operational usefulness of a rule. Transactions with confidence with more than 50% will be selected. For example, the confidence of milk, sugar and coffee powder given milk, coffee can be written as
Number of transactions that include Milk & Sugar (Antecedent) and Coffee Powder (Consequent) is 3
Number of transactions that contains only Milk & Sugar (Antecedent)) is 5.
P(Milk & Sugar AND Coffee Powder)/P (Milk & Sugar) = 3/5 = 60%
Hence we can say that the association rule has a confidence of 60%. Higher the confidence , stronger the rule is.
Lift ratio – The lift ratio indicates how efficient in the rule is in finding consequences, compared to random selection of transaction. As a general rule, Lift ratio of greater than one suggests some usefulness in the rule.
Market Basket Analysis with XLMINER
Now let’s take a deep dive to understand the technicals that drive the Market Basket Analysis. Let us run through this with the help of a large open dataset. Let us use Groceries dataset. (Source: Dataset can also be downloaded from http://www.salemmarafi.com/wp-content/uploads/2014/03/groceries.csv)
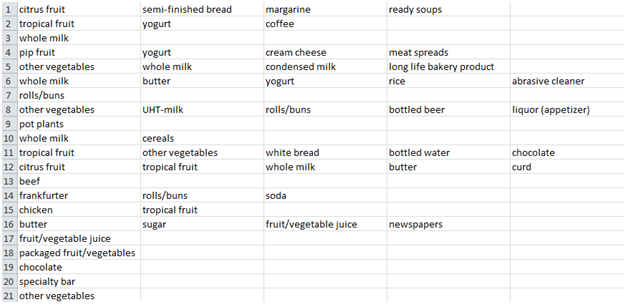
The groceries dataset consists of close to 10000 transaction records with each transaction record containing the items that were purchased in a single receipt. Please find the sample representation of the dataset.
Grocery Dataset Representation
How to read this? – Transaction 1 contains Citrus fruit, semi-finished bread, margarine, ready soups all purchased together in a single receipt.
Summary of Grocery Dataset
There are 9835 transaction records. There were atmost 32 items purchased on one of its transactions. The total number of unique items is 169.

(We can get this summary from XLMINER which will be explained later).
The problem Statement for the Grocery Dataset
Here is the problem statement that we would like to solve : A Marketer is interested in knowing what product is purchased with what product or if certain products are purchased together as a group of items which they can use to strategize on the cross selling activities.
In order to perform a Market Basket Analysis for a typical large datasets like this, we can use tools like R,SAS, MEXL, XLMINER etc. R is open source software. Market basket analysis with R has been well explained in many blogs. Hence let us take XLMINER to do our analysis (Instructions for using trial version of XLMINER is provided at the bottom).
Association Analysis with XLMINER
As a first step we need to understand what is purchased with what with the help of Association analysis.
Step 1:
After installing the XLMINER you should be able to find it as an Add-in in your MS Excel.
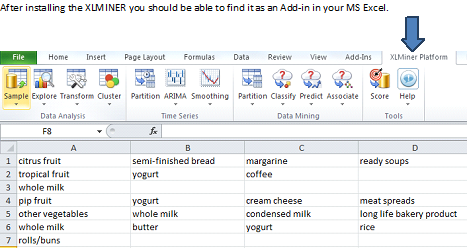
Step 2:
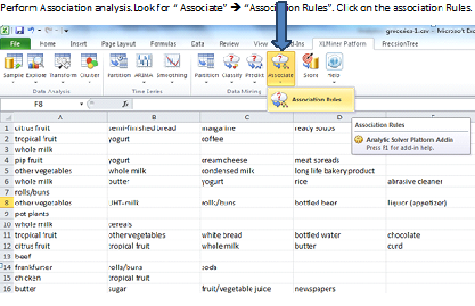
Perform Association analysis.Look for “ Associate” è “Association Rules”. Click on the association Rules.
Step 3:
You would see “Association Rules” window opened.
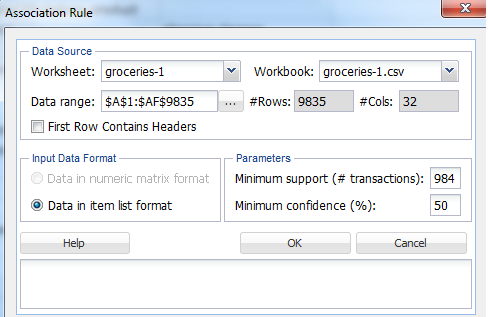
Terminologies used in “Association Rule” Window:
The two important terminologies that we should know to perform this analysis are Minimum Support and Confidence. Let’s understand what those are.
Minimum Support (#transactions) – The minimum support of the rule is defined as the minimum number of transactions that include both the antecedent and consequent parts in order to qualify to be part of frequent item set. The default minimum support would be 10% of the total number of transactions taken for analysis.
Minimum Confidence – The minimum confidence of the rule is defined as the minimum number of transaction that has consequent will also have antecedent. The default minimum confidence would be 50%.
The other terminologies that we should be aware of:
Data Range – Data Range is the data to which we want to run the Association analysis. Default is the complete dataset in the chosen worksheet. You can leave it default, unless until there is a specific requirement.
#Rows – The default number of rows would be the number of records present in the worksheet.
#Cols – The default number of columns would be the number of columns on which the records are present in the worksheet.
First Row contains header – Check it if the first row of the excel sheet contains header. We are not using it as we don’t have a header field.
Data in the item list format – Leave it default as most of the association analysis carried out for the list items.
Step 4:
From the summary of the data (mentioned before step 1) we know that the number of unique items are 169 and number of transactions are 9835. As the number of unique items is huge, there would be huge variations between the co-occurrence of the frequent items. Hence we will consider the minimum support to be 0.1% of the total number of records. In order to have a better confidence and less error prone on the rules generated we will give the minimum confidence to be 90%. Click OK.
Note: This is not a thumb rule. We are taking in order to get a better result. A Marketer may analyze with different combination of support and confidence and see what works best for his business.
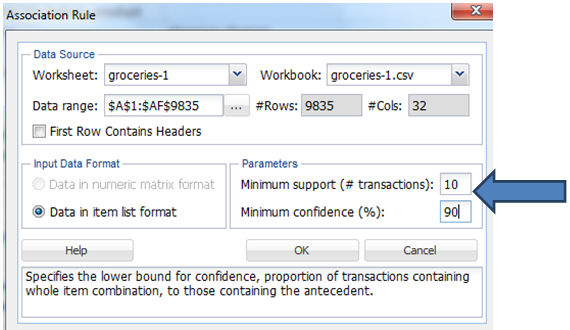
And here the Output is
A new tab with in the excel sheet will be created named “AssoRules_Output” as shown below.

Let us have a look on the” inputs” and analyze the “list of rules” that we got as part of the output.

Input shows the metrics of the input data including the minimum support and confidence that we have given.
One thing that is new to us here is the “#Association rules” which is nothing but the number of association rules that was generated as an output.
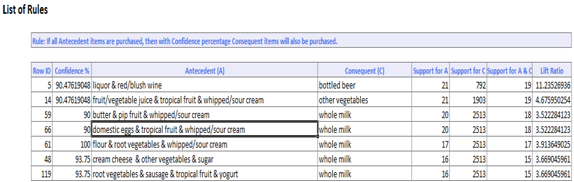
Here above is sample output of list of rules (filtered to show various representations).
Interpretation of the output:
As we can see there are 14 association rules were generated for the given input. A very efficient rule should satisfy the following conditions:
- The item set should exceed minimum support determined based on the business need.
- Should exceed the minimum confidence.
- Should have greater Lift Ratio.
A Marketer would consider rules with high Lift ratio, high Confidence and good support. For example,
IF flour, root vegetables & whipped/sour cream are purchased THEN whole milk is also purchased. This rule has 100% confidence. The confidence of 100% tells us that this rule appears to be a very promising rule for the business.
IF Liquor & red blush wine is purchased THEN bottled beer also purchased. This rule has a confidence of 90%.
Based on these results the marketer would be able to answer questions like:
- How one can cross sell categories so that the business can increase the basket size of the customers.
- How to identify the right customers to whom the products can be cross sold
- The right bundle for the right group
- And many more.
POSTSCRIPTS
A Brief intro to XLMINER:
XLMINER is a Excel Add-in which can be used for performing data mining works like neural nets, classification, regression and much more. All the screen prints used in this article are taken using the 15 days trial version of the XLMINER. Reference: http://www.solver.com/xlminer-data-mining
References:
- Data Mining for Business Intelligence by GalitShmueli, et. al. First edition published by Wiley.
- Groceries data set is an open sources dataset referred from www.salemmarafi.com/code/market-basket-analysis-with-r
- Data Mining and Business Analytics with R by Johannes Ledolter . Published by John Wiley & Sons, year 2013.
This article was received from Karthikeyan Palanisamy as part of application for Analytics Vidhya Apprentice Programme. A Mechanical Engineer by graduation – A Software Engineer by profession – A Analytic modeller by passion – Karthikeyan spends most of his time thinking on how to connect the dot between these three vertices and ending up only to find that his talent (?!!) mostly lies in the intersection of all these and not in one single area. He loves problem solving as good as he creates problems for himself. When he is not thinking, he loves to read anything from Politics to Poetry and from geography to gossiping.
His Linkedin profile : in.linkedin.com/in/karthekeyan. He can be reached out at [email protected]






Good job, explaining the concepts of Market Basket Analysis. I would like to share some feedback which I hope is useful to you. 1. I suggest you do a follow up on Collaborative Filtering, to compliment this post on product affinity or Content filtering. Recommendation systems are either based on either one or a hybrid of both like the one used at Netflix. It would be great to expose the audience to both. 2. You could outline the steps to do an MBA in R, SPSS or SAS which provide excellent visualizations of the rules generated. For R you can check out the arules and arulesViz packages. All the best and keep blogging!
Dear Clarence, Thank you so much for your wonderful comments. 1. Sure, Thank you. I will take it up as suggested. 2. I have given reference for MBA in R in the above article itself. (www.salemmarafi.com/code/market-basket-analysis-with-r). For SAS i can try working on the other post. Thank you again. Regards, Karthikeyan P
Hi Karthik, Really Good show and loads of information. Thanks for this write up. Regards Sswayam
Dear Swayam, Thank you very much. Regards, Karthikeyan P
Very nice article.informative.thanks Karthik