This article was published as a part of the Data Science Blogathon.

Introduction
In this article, we will introduce you to Apache Spark and its role in big data and the way it makes a big data ecosystem we will also explore Resilient Distributed Dataset (RDD) in spark.
As we all have seen the growth of data in today’s world, Growing data helps many companies to get insights into data and this information is used for the growth. Smart assistants like Siri, and Google Home, Alexa use Big Data, Machine learning, and IoT technologies to collect data and answer questions.
Due to the high growth of data-driven technologies, more data is being generated and we need to process petabytes of data. Processing petabytes of data is not easy for a single computer and this task is distributed among various computers and all performed together, this is the idea behind big data.
Processing of Big Data
Processing a high volume of data needs various computers to work parallelly and process it. Since we can’t load a high volume of data on a single computer. This is known as distributed computing. In other words, the processing task is divided and run independently with its computing resources. If any single computer or node gets failed or goes down other nodes take the remaining job.
A cluster is a distributed system ( a collection of multiple nodes) that works together in synchronization on a particular task. The big data ecosystem is made of up many open source tools. for example, Open-Source projects like Hadoop and big data tools like Apache Spark, and Hive complete the big data ecosystem. Since they are free to use and transparent.
Big Data EcoSystem
The big data ecosystem is consist of various open-source to paid tools. all are made for their specific purpose. Big data requires cloud computing, Data processing tools, Database management tools, and business intelligence to programming language.
Categorized tools required
- Programming Tools
- Business Intelligence tools
- Databases (NoSql and SQL )
- Analytics and visualization
- Data technologies
- Cloud Technologies
Hadoop Ecosystem
Hadoop Ecosystem is made up of various open-source tools that fall under the Hadoop project. All these components support one another.
- Ingest Data( Flume , Sqoop)
- Access Data ( Impala, Hue)
- Process and Analyze Data (Pig & Hive)
- Store Data (HDFS, HBase)
Why Apache Spark?
Big Tech Companies like Tencent, Uber, Netflix, Google, and Alibaba all run Apache spark operations.
Spark is a powerful replacement for Apache Map-Reduce. Spark is more powerful and faster than Hadoop in computation, it is highly accessible and capable of processing a high volume of data in the distributed system.
In-memory computation ( computation in ram instead of the disk) makes Spark run faster than Map-Reduce for distributed data processing.
Top Features of Apache Spark
These are the top features of apache spark that make it widely popular and superior.
1. Fast Processing
Spark processes data 100 times faster in memory and 10 times faster in the Hadoop cluster. Spark has already set the world record for fastest data sorting on disk.
2. Supports various APIs
Spark provides various programming language APIs which means spark applications can be written in any language for example SCALA, JAVA, PYTHON, R.
Spark is written on SCALA natively. Spark core performs large-scale distributed and parallel data processing. Spark Core is fault-tolerant which means if any node goes down processing will not stop.
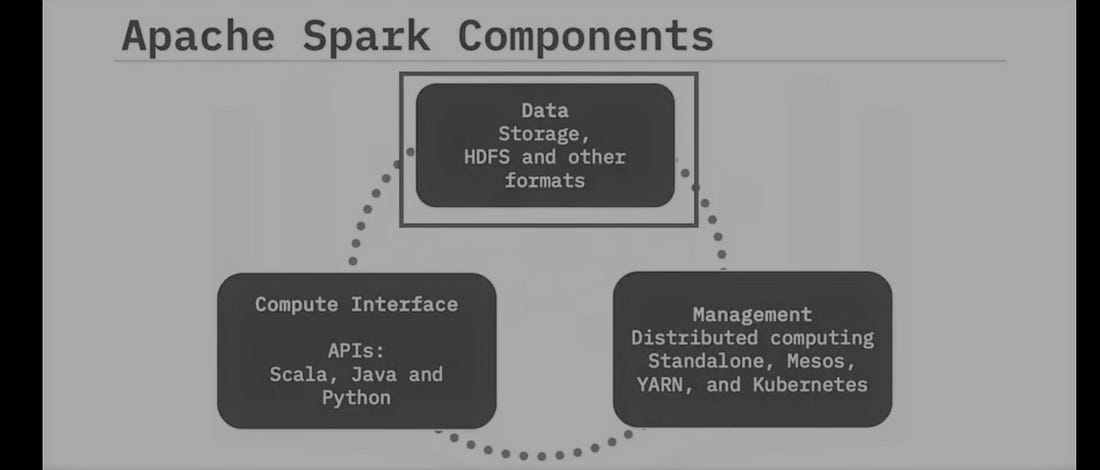
SPark also provides many built-in packages for Machine learning tasks.
3. PowerFul libraries
Spark also supports Map-Reduce functions. Spark works on Distributed dataframes and SQL.
ML-lib is a rich machine learning package that comes with spark. Spark Streaming makes real-time data processing and analysis possible.
4. Real-Time Processing
Spark supports also supports conventional MapReduce which is capable of processing data from Hadoop HDFS files. Spark can work on the HDFS cluster without any conflicts.
5. Deployment and Compatibility
Spark is able to run on any cloud notebook without needing many dependencies. Spark can run on Kubernetes, Mesos, Hadoop, and cloud notebooks.
Apache Spark Architecture
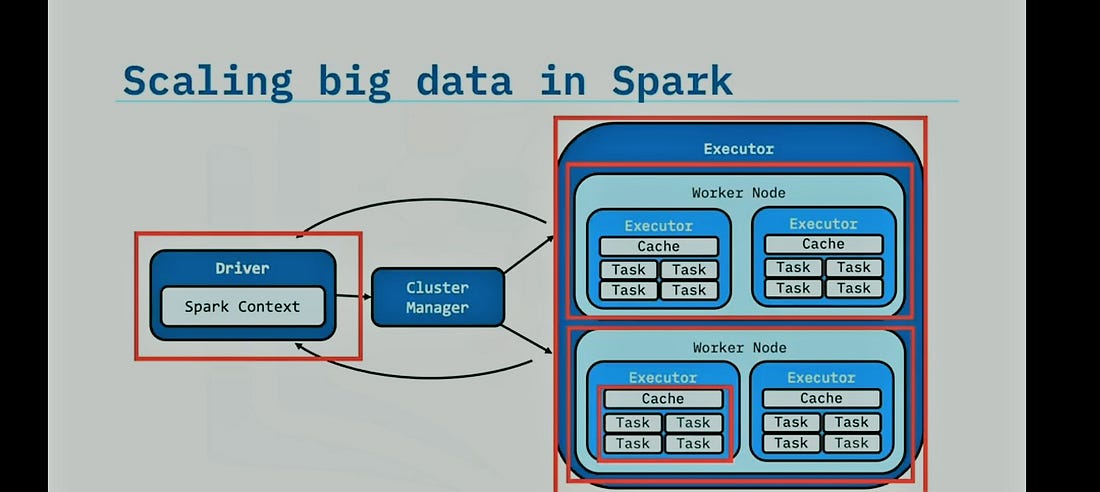
Any Spark Engine contains 3 high-level components:
- Spark Driver
- Cluster Manager
- Executors
Getting Started with Spark with Python
Spark is natively written in Scala programming language that compiles in java. We can communicate with JVM using py4j. This makes using Python to work on Spark Possible.
Hence we can create Spark applications in Python with ease. In the backend, it will be using py4j.
Objectives
- Setting Up Pyspark
- Context and Session
- Spark RDD
- Transformation and actions
For Running Spark, you need a python environment it could be any cloud notebook or local python environment, but I highly encourage you to create a data-bricks spark cluster, this is a guide on how to spin spark clusters on data-bricks for free.
PySpark It is a Spark API that lets us create applications in Spark. In this article, we will be using Pyspark to work on Spark.
Installing Required Packages
Setting up the spark in python needs the following libraries.
!pip install pyspark !pip install findspark
Findspark It adds a startup file to the current IPython profile and creates an environment ready for Spark in Python.
import findspark findspark.init()
Creating the Spark Context, and Spark Session.
Spark session It is needed for working on Spark dataframes and SQL.
SparkContextIt is the entry point for Spark applications and it also concludes functions to create RDDs(Resilient distributed databases) likeparallelize().
# Initialization spark context class
sc = SparkContext()
# Create spark session
spark = SparkSession
.builder
.appName("Python Spark DataFrames basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
getOrCreate It creates a new session if the session with the specified name doesn’t exist.
Spark Session
After the successful creation of the session, it can be verified by running the spark command. It will return the details for the running session.
spark

Spark RDDs
Spark RDDs are primitive distributed data abstraction in spark and we apply functional programming concepts to work with RDDs.
RDD accepts multiple types of files including :
- Sequence Files, Avro, Parquet, Text, Hadoop inputs, etc.
- Cassandra, HBase, Amazon S3, HDFS, etc.
Note: RDDs are immutable in nature in order to maintain data integrity. We can’t modify data in RDD we can only create a new one or replace it.
RDDs are works in a distributed system, which means the data in RDD will be distributed across the multiple nodes.
RDDs are lazily evaluated data systems. which means it won’t apply any transformation until the action is not called.
sc.parallelizeIt inputs a series and turns it into RDD.
Converting a list into an RDD using parallelize method.
data = range(1,20) # print first element of iterator print(data[0]) len(data) xRDD = sc.parallelize(data, 4)
Apache Spark RDD Transformation
As we know that RDDs are immutable in nature, when we perform a transformation it returns a new RDD. RDDs are lazy evaluated which means no calculation is performed until the action is not called explicitly.
Transformations are the set of rules to be applied to the RDDs and the actions are the command that applies the transformation of RDDs.
# Reduces each number by 1 sRDD = xrangeRDD.map(lambda x: x-1)
# selects all number less than 10 filteredRDD = sRDD.filter(lambda x : x<10)
Calling action
When we call an action, RDDs start it applying all the transformation that has already been specified on that particular RDD.
print(filteredRDD.collect()) filteredRDD.count()

Conclusion
In this article, we discussed how the Big data ecosystem is made, and what are the tools that make it.
We looked at the various category of tools that works in the big data ecosystem. We learned about Spark’s Core and its components. We discussed what makes Spark faster than MapReduce and how it replaces MapReduce.
We talked about Spark RDD and Transformations and actions:
- Spark RDDs are immutable that maintain data integrity.
- Spark RDDs are lazy evaluated, which makes data processing easier and simple.
- Spark also Supports Distributed SQL processing.
- Spark can run on any python environment.
- Spark Session and context must be created.
Thanks for reading this article!
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.







