This article was published as a part of the Data Science Blogathon.
Introduction
After reading the heading Apache Pig, the first question that hits every mind is, why the word Pig? Apache Pig is capable of working on any kind of data, similar to a pig who can eat anything. Pig is nothing but a high-level extensible programming language designed to analyze bulk data sets and to reduce the complexities of coding MapReduce programs. Yahoo developed Pig to analyze huge unstructured data sets and minimize the writing time of Mapper and Reducer functions.
What is Apache Pig?
Apache Pig is an abstraction over MapReduce that is used to handle structured, semi-structured, and unstructured data. It is a high-level data flow tool developed to execute queries on large datasets that are stored in HDFS. Pig Latin is the high-level scripting language used by Apache Pig to write data analysis programs. For reading, writing, and processing data, it provides multiple operators that can easily be used by developers. These pig scripts get internally converted to Map and Reduce tasks and get executed on data available in HDFS. Generally, a component of Apache Pig called Pig Engine is responsible for converting the scripts into MapReduce jobs.
Why do we Need Apache Pig?
Usually, programmers struggle while performing any MapReduce tasks, as they are not so good at Java to work with Hadoop. In such cases, Pig works as a situation booster to all such programmers. Here are some reasons that make Pig a must-use platform:
-
While using Pig Latin, programmers can skip typing the complex codes in Java and perform MapReduce tasks with ease.
-
The multi-query approach is used by Pig to reduce the length of codes. For example, Instead of typing 200 lines of code (LoC) in Java, programmers can use Apache Pig to write just 10 LoC.
-
Pig Latin is easy to understand as it is a SQL-like language.
-
Pig is also known as an operator-rich language because it offers multiple built-in operators like joins, filters, ordering, etc.
Features of Apache Pig
Following are the features of Apache Pig:-
-
Extensibility
Pig is an extensible language that means, with the help of its existing operators, users can build their own functions to read, write, and process data.
-
Optimization Opportunities
The tasks encoded in Apache Pig allow the system to optimize their execution automatically, so the users can focus only on the semantics of the language rather than efficiency.
-
UDFs
UDFs stand for user-defined functions; Pig provides the facility to create them in other programming languages like Java and embed them in Pig Scripts.
-
Ease of programming
It is difficult for non-programmers to write the complex java programs for map-reduce, but using Pig Latin, they can easily perform queries.
-
Rich operator set
Pig Latin has multiple operator support like join, sort, filter, etc.
Difference between Apache Pig and Map Reduce
Although Apache Pig is an abstraction over MapReduce, their overlapping functions make it difficult to differentiate them. Apache Pig is related to the MapReduce tasks but works in an entirely different manner. Here are some major differences:
-
Apache Pig is a user-friendly high-level data-flow language, while MapReduce is just a low-level paradigm for data processing.
-
Apache Pig doesn’t require any compilation process, but MapReduce operations need a significant compilation process.
-
Join task in Pig can be performed much more smoothly and efficiently than MapReduce.
-
The multi-query functionality of Apache Pig enables to write very few lines of code and makes the operation more efficient, while MapReduce doesn’t support this feature. In comparison to Pig, MapReduce needs to write 20 times more lines of code to perform the same operation.
-
Basic knowledge of SQL is enough for working with Pig, but a deep understanding of Java concepts is required to work with MapReduce.
Architecture and Components of Apache Pig
Firstly, we submit Pig scripts to the execution environment of Apache Pig which can be written in Pig Latin using in-built operators. The Pig scripts undergo various transformations in multiple stages to generate the desired output. Let’s discuss each phase separately.
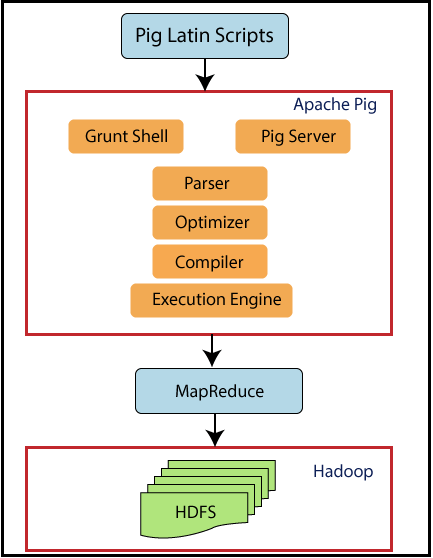
source: https://www.tutorialandexample.com/apache-pig-architecture
First Stage: Parser
At first, when a Pig Latin script is sent to Hadoop Pig, it is handled by the Parser. Basically, the parser is responsible for various types of checks on the script, like type checks, syntax checks, and other miscellaneous checks. Afterwards, Parser gives an output in the form of a Directed Acyclic Graph (DAG), which carries the logical operators and Pig Latin statements. In the logical plan(DAG), the logical operators of the script are represented as the nodes, and the data flows are represented as edges.
Second Stage: Optimizer
After retrieving the output from the parser, a logical plan for DAG is submitted to a logical optimizer. The logical optimizations are carried out by the optimizer, which includes activities like transform, split, merge, reorder operators, etc. The optimizer basically aims to reduce the quantity of data in the pipeline when it processes the extracted data. This optimizer performs automatic optimization of the data and uses various functions like
-
PushUpFilter: If multiple conditions are available in a filter and the filter can be split, then Pig pushes up each condition individually and splits those conditions. An earlier selection of these conditions is helpful by resulting in the reduction of the number of records left in the pipeline.
-
LimitOptimizer: If the limit operator is applied just after a load or sort operator, then Pig converts these operators into a limit-sensitive implementation, which omits the processing of the whole data set.
-
ColumnPruner: This function will omit the columns that are never used; hence, it reduces the size of the record. This function can be applied after each operator to prune the fields aggressively and frequently.
-
MapKeyPruner: This function will omit the map keys that are never used, hence, reducing the size of the record.
Third Stage: Compiler
After receiving the optimizer’s output, the Compiler compiles the resultant code into a series of MapReduce tasks. The Compiler is responsible for the conversion of Pig Script into MapReduce jobs.
Fourth Stage: Execution Engine
At last, come to the Execution Engine, where the MapReduce jobs are transferred for execution to the Hadoop. Then the MapReduce jobs get executed, and Hadoop provides the required results. Output can be displayed on the screen by using the ‘DUMP’ statement and can be stored in the HDFS by the ‘STORE’ statement.
Pig Latin Data Model
The data model of Pig Latin allows it to handle a variety of data. Pig Latin can handle simple atomic data types such as int, float, long, double, etc., as well as complex non-atomic data types such as map, tuple, and bag.
Example Data set:

Atom
Atom is a scaler primitive data type that can be any single value in Pig Latin, irrespective of their data type. The atomic values of Pig can be string, int, long, float, double, char array, and byte array. A simple atomic value or a byte of data is known as a field.
Example of an atom − ‘2’, ‘Kiran,’ ‘25’, ‘Kolkata,’ etc.
Tuple
A tuple is a record that is formed by an ordered set of fields that may carry different data types for each field. A tuple can be compared with the records stored in a row in an RDBMS. It is not mandatory to have a schema attached with the elements present inside a tuple. Small brackets ‘()’ are used to represent the tuples.
Example of tuple − (2, Kiran, 25, Kolkata)
Bag
An unordered set of tuples is known as a bag. Basically, a bag is a collection of tuples that are not mandatory to be unique. Curly braces ‘{}’ are used to represent the bag in a data model. Bag supports a flexible schema, i.e., each tuple can have any number of fields. A bag is much more similar to a table in RDBMS, but unlike a table in RDBMS, it is not mandatory that the same number of fields are present in a tuple or that the fields in the same position have the same data type.
Example of a bag − {(Kiran, 25, Kolkata), (Aisha, 20), (Ketki, Agra)}
Map
A map is nothing but a set of key-value pairs used to represent the data elements. The key should be unique and must be of the type char array, whereas the value can be of any type. Square brackets ‘[]’ are used to represent the Map, and the hash ‘#’ symbol is used to separate the key-value pair.
Example of maps− [name#Kiran, age#25 ], [name#Aisha, age#20 ]
Introduction to Pig Latin commands
To communicate with Pig, a very powerful tool is used called Grunt Shell. A grunt shell is an interactive shell that establishes an interaction of the shell with HDFS and the local file system. We can open any remote client access software like putty to start the Cloudera and type Pig to enter in the Grunt Shell. Grunt Shell allows you to write Pig Latin statements and queries the structured/unstructured data.
To start Pig Grunt type:
Pig

Following are the basic and intermediate Pig Latin operations:
Reading Data
To read data in Pig, we need to put the data from the local file system to Hadoop. Let’s see the steps:
Step 1:- Create a file using the cat command in the local file system.
Step 2:- Transfer the file into the HDFS using the put command.
Step 3:- Read the data from the Hadoop to the Pig Latin using the load command.
Syntax:-
Relation = LOAD 'Input file path information' USING load_function AS schema;
Where,
-
Relation − We have to provide the relation name where we want to load the file content.
-
Input file path information − We have to provide the path of the Hadoop directory where the file is stored.
-
load_function − Apache Pig provides a variety of load functions like BinStorage, JsonLoader, PigStorage, TextLoader. Here, we need to choose a function from this set. PigStorage is the commonly used function as it is suited for loading structured text files.
-
Schema − We need to define the schema of the data or the passing files in parenthesis.
Running Pig Statements
To run the Pig Latin statements, we use the Dump operator. It will display the results on the screen and can be used for debugging purposes.
Syntax:
grunt> Dump Relation_Name
Describe Operator
To display the schema of the relation, describe operator is used.
Syntax:
grunt> Describe Relation_name
Illustrate Operator
To get the step-by-step execution of a sequence of statements in Pig command, illustrate operator is used.
Syntax:
grunt> illustrate Relation_name;
Explain
To review the logical, physical, and map-reduce execution plans of a relation, explain operator is used.
Syntax:
grunt> explain Relation_name;
Filter
To select the required tuples from a relation depending upon a condition, the FILTER operator is used.
Syntax:
grunt> Relation2 = FILTER Relation1 BY (condition);
Limit
To get a limited number of tuples from a relation, Pig supports the limit operator.
Syntax:
grunt> Output = LIMIT Relation_name number of tuples required ;
Distinct
To remove duplicate tuples from a relation, the distinct operator is used.
Syntax:-
grunt> Relation2 = DISTINCT Relation1;
Foreach
To generate specified data transformations based on the column data, the Foreach operator is required.
Syntax:
grunt> Relation2 = FOREACH Relation1 GENERATE (required data);
Group
To group the data in one or more relations, the Group operator is used. It groups the data with the same key.
Syntax:
grunt> Group_data = GROUP Relation_name BY key_column;
Grouping by multiple columns
Group operators can also group the data in one or more relations using multiple columns.
Syntax:
grunt> Group_data = GROUP Relation_name BY (column1, column2,column3,..);
Group All
To group a relation by all the columns, the Group All operator is used.
Syntax:
grunt> group_all_data = GROUP Relation_name All;
Cogroup
The Cogroup operator is much more similar to the group operator. The major difference is the cogroup is more suited for multiple relations, whereas the group is more suitable for single relations.
Syntax:
grunt> cogroup_data = COGROUP Relation1 by column1, Relation2 by column2;
Join
The purpose of the Join operator is to combine data from two or more relations. Firstly, we have two declare the keys, which are nothing but a tuple from each relation. If the keys are matched with each other, then we consider that two particular tuples are matched and can be displayed in the output; otherwise, the unmatched records are dropped. Following are the types of Joins−
-
Self Join
-
Inner Join
-
Left outer join
-
Right outer join
-
Full outer join
Let’s understand each type of join.
Self Join
When we have to join a table with itself, or we treat a single table as two separate relations, then self-join is used. We load the same data multiple times with different alias names to perform the join operation.
Syntax:
grunt> Relation3 = JOIN Relation1 BY key, Relation2 BY key;
Inner Join
The most commonly used join is the inner join(also known as equijoin). An inner join compares both the tables(say A and B) and returns rows when there is a match. Using the join predicate combines the column values and creates a new relation.
Syntax:
grunt> Output = JOIN Relation1 BY column1, Relation2 BY column2;
Left Outer Join
The left outer join compares two relations, the left and the right relation, and returns all the rows from the left relation, even if doesn’t match with the right relation.
Syntax:
grunt> Relation3 = JOIN Relation1 BY id LEFT OUTER, Relation2 BY column;
Right Outer Join
The right outer join compares two relations, the left and the right relations, and returns all the rows from the right relation, even if doesn’t match with the left relation.
Syntax:
grunt> Relation3 = JOIN Relation1 BY id RIGHT OUTER, Relation2 BY column;
Full Outer Join
The full outer Join compares two relations, the left and the right relation, and returns rows when there is a match in one of the relations.
Syntax:
grunt> Relation3 = JOIN Relation1 BY id FULL OUTER, Relation2 BY column;
Cross
To calculate the cross-product of two or more relations, the cross operator is used.
Syntax:
grunt> Relation3 = CROSS Relation1, Relation2;
Union
To merge the content of two relations, a union operator is used. The necessary condition to perform merging is the columns and domains of both the relations must be identical.
Syntax:
grunt> Relation3 = UNION Relation1, Relation2;
Split
To divide a relation into two or more relations, the split operator is required.
Syntax:
grunt> SPLIT Relation1 INTO Relation2 IF (condition1), Relation2 (condition2);
Conclusion
In this guide, we learned about the Apache Pig, which analyzes any type of data present in HDFS.
-
We discussed Pig, its features, architecture, and its components.
-
In this guide, we also discussed how to interact with the Grunt shell and perform various Linux-based commands.
-
We also made a comparison of Pig with MapReduce.
-
We don’t have to install the Grunt shell explicitly. Instead, we can open the Cloudera to run these Linux-based Pig commands.
I hope this guide on Pig has helped you to gain a better understanding of how Pig works. If you have any queries, let me know in the comment section.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Shikha Gupta
13 Jul, 2022







