In previous article, we discussed the Hadoop ecosystem ( link ). We also spoke about two most heavily used Hadoop tools i.e. PIG and HIVE. Both the languages have their followers and there is no specific preference between the two, in general. However, in cases where the team using these tools is more programming oriented, PIG is sometimes chosen above HIVE as it gives them more freedom while coding. In cases where the team is not very programming savvy, HIVE probably is a better option, given its similarity to SQL queries. Queries on PIG are written on PIG latin. In this article we will introduce you to PIG Latin using a simple practical example.
Installation of PIG
PIG engine operates on client server. It is simply an interpreter which converts your simple code into complex map-reduce operations. This mapreduce is now handled on distributed network of Hadoop. Note that the entire network will not even know that the query was executed from a PIG engine. PIG only remains at the user interface and is meant to make it easier for the user to code.

Follow the following steps in your shell to install PIG :
[stextbox id=”grey”]
To install Pig On Red Hat-compatible systems:
$ sudo yum install pig
To install Pig on SLES systems:
$ sudo zypper install pig
To install Pig on Ubuntu and other Debian systems:
$ sudo apt-get install pig[/stextbox]
If you are thinking of running Pig on Windows, you should just get a virtual machine running on Linux and then work on it. You can use VMWare Player or Oracle VirtualBox to start one.
After installing the PIG package, you can start with the grunt shell.
[stextbox id=”grey”]
To start the Grunt Shell (MRv1):
$ export PIG_CONF_DIR=/usr/lib/pig/conf $ export PIG_CLASSPATH=/usr/lib/hbase/hbase-0.94.2-cdh4.2.1-security.jar:/usr/lib/ zookeeper/zookeeper-3.4.5-cdh4.2.1.jar $ pig 2012-02-08 23:39:41,819 [main] INFO org.apache.pig.Main - Logging error messages to: /home/arvind/pig-0.9.2-cdh4b1/bin/pig_1328773181817.log 2012-02-08 23:39:41,994 [main] INFO org.apache.pig.backend.hadoop.executionengine.HExecutionEngine - Connecting to hadoop file system at: hdfs://localhost/ ... grunt> To start the Grunt Shell (YARN):
$ export PIG_CONF_DIR=/usr/lib/pig/conf
$ export PIG_CLASSPATH=/usr/lib/hbase/hbase-0.94.2-cdh4.2.1 -security.jar:/usr/lib/zookeeper/zookeeper-3.4.5-cdh4.2.1.jar
$ pig ... grunt>
[/stextbox]
Once you see “grunt>”, you can start coding on PIG.
Case Background
You are the lead of analytics in Retail store named XYZ. XYZ maintains a record of all customers who shop at this store. Your task for this exercise is to create a new column called tax on Sale which is 5% of the sale. Then filter out people for whom the tax amount is less than $35. Once this subsetting is done, choose the top 2 customers with least customer number. Following is sample table for the Retail store which is saved in form of a .csv .
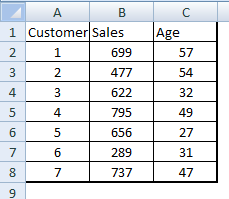
Writing a query in PIG Latin
Let’s build this query step by step. Following are the steps you need to follow :
Step 1 : Load dataset in the PIG understandable format and temporary storage from where PIG query can directly reference the table
[stextbox id=”grey”]Sales = LOAD 'dataset.csv' USING PigStorage (',') AS (Customer,Sales);
[/stextbox]
Note that the above command does not load the variable age. While working with Big Data, you need to be very specific about the variables you need to use and hence make sure you pick only those variables which are of importance to you in the code.
Step 2 : Create a new table with tax values.
[stextbox id=”grey”]Tax = FOREACH Sales GENERATE Customer,Sales,Sales*0.05 as Tax : float;[/stextbox]
Above command generates a new table called tax which has all the three columns. The table will now look something like below :
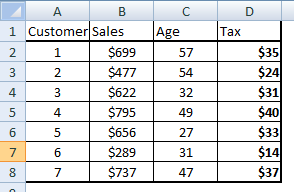 Step 3 : Subset the entire table on customer with Tax value below $35.
Step 3 : Subset the entire table on customer with Tax value below $35.
Lowtax = FILTER Tax BY Tax < $35;[/stextbox]
The output to this command will look choose the yellow cells in the following table :
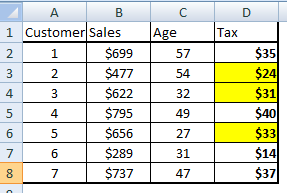 Step 4 : Now we need to sort the subset table on Customer (ID) and choose the top two Customers.
Step 4 : Now we need to sort the subset table on Customer (ID) and choose the top two Customers.
sortedcust = ORDER Lowtax BY Customer;
top_two = LIMIT sortedcust 2;[/stextbox]
Step 5 : Store the temporary file into a permanent csv file
[stextbox id=”grey”]STORE sortedcust INTO 'salesreport' USING PIGSTORAGE (',');
[/stextbox]
On this step our task is completed and you will get the required customer numbers with all the details.Following is the complete code which can be executed at once :
[stextbox id=”grey”]Sales = LOAD 'dataset.csv' USING PigStorage (',') AS (Customer,Sales);
Tax = FOREACH Sales GENERATE Customer,Sales,Sales*0.05 as Tax : float;
Lowtax = FILTER Tax BY Tax < $35;
sortedcust = ORDER Lowtax BY Customer;
top_two = LIMIT sortedcust 2;
STORE sortedcust INTO 'salesreport' USING PIGSTORAGE (',');
[/stextbox]
End Notes
In this article, we learned how to write basic codes in PIG Latin. However, we have restricted this article to simple filter and sort statements, we will also talk about more complex merge and other statements in few of the coming articles.
Did you find the article useful? Share with us any practical application of PIG you encountered in your work . Do let us know your thoughts about this article in the box below.
If you like what you just read & want to continue your analytics learning, subscribe to our emails, follow us on twitter or like our facebook page.
Tavish Srivastava, co-founder and Chief Strategy Officer of Analytics Vidhya, is an IIT Madras graduate and a passionate data-science professional with 8+ years of diverse experience in markets including the US, India and Singapore, domains including Digital Acquisitions, Customer Servicing and Customer Management, and industry including Retail Banking, Credit Cards and Insurance. He is fascinated by the idea of artificial intelligence inspired by human intelligence and enjoys every discussion, theory or even movie related to this idea.







In the 2nd step of the case it is said that we do not load "Age" then how we got age also in the output of the 3rd step?