This article was published as a part of the Data Science Blogathon.
Introduction
A key aspect of big data is data frames. Pandas and Spark are two of the most popular types. However, Spark is more suited to handling scaled distributed data, whereas Pandas is not. In contrast, Pandas’ APIs and syntax are easier to use. What if the user gets the most out of both worlds? A library called Koalas makes it possible for a user to take advantage of both worlds, thus saving them from having to choose from both. Hence, this article!
An article here describes the rationale behind using Koalas and then talks about the different library usage with different spark versions. It then discusses the differences between Koalas and Pandas and performs tests to verify those differences. The purpose is to help the reader establish a strong foundation in the former. As the foundation is established, the next chapter will discuss what data scientists should consider when using it and finally finish up with a summary and key takeaways. Let’s get started.
Why Koalas?
Koalas library got introduced because of the following issues in the current spark system [2].
- Several features frequently required in data science are missing in Apache Spark. Specifically, plotting and drawing charts is an essential feature that almost all data scientists use daily.
- Normally, data scientists prefer pandas’ APIs, but switching them to PySpark APIs is hard if they need to scale their workloads. This is because PySpark APIs are difficult to learn compared to pandas and contain many limitations.
Koalas Library Variants
To use Koalas in the spark notebook, you need to import the library. There are two options available in libraries. The first option is “databricks.koalas” and prior to PySpark version 3.2.x, this is the only option available. But post 3.2.x, another library named “pyspark.pandas” was introduced and this name aligns more realistic with Pandas API [3]. Spark suggests using the later one as the former will stop support soon.
Koalas vs. Pandas
Simply put, you can consider koalas as the PySpark data frame wrapped under pandas’ cover. You have all the advantages of the spark data frame in koalas and the pandas’ way of interaction. The Koalas API brings together both spark speed and pandas’ better usability to create a powerful and versatile API. The same concept is depicted pictorially in the diagram below.
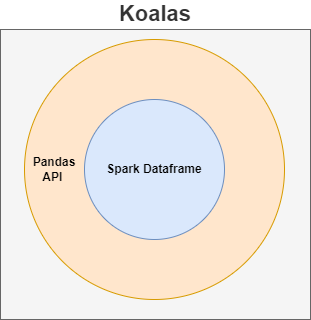
The key similarity between pandas and koalas is that the APIs used in both libraries are the same. That is if pandas use pd.DataFrame(), then in koalas also, the API use would be the same i.e., kl.DataFrame(). However, the difference between the two data frames (pandas & koalas) makes koalas really special. That is, the koala’s data frame is distributed – in a way similar to the spark data frame [1]. Unlike other spark libraries, Pandas runs in a single node on a driver rather than across all the worker nodes, so it cannot scale. Opposite to Pandas, the Pandas API (aka koalas) works exactly the way similar to the spark library.
To understand the two terms, let’s use a sample program (refer to GitHub) to conduct some tests that confirm the above differences mentioned.
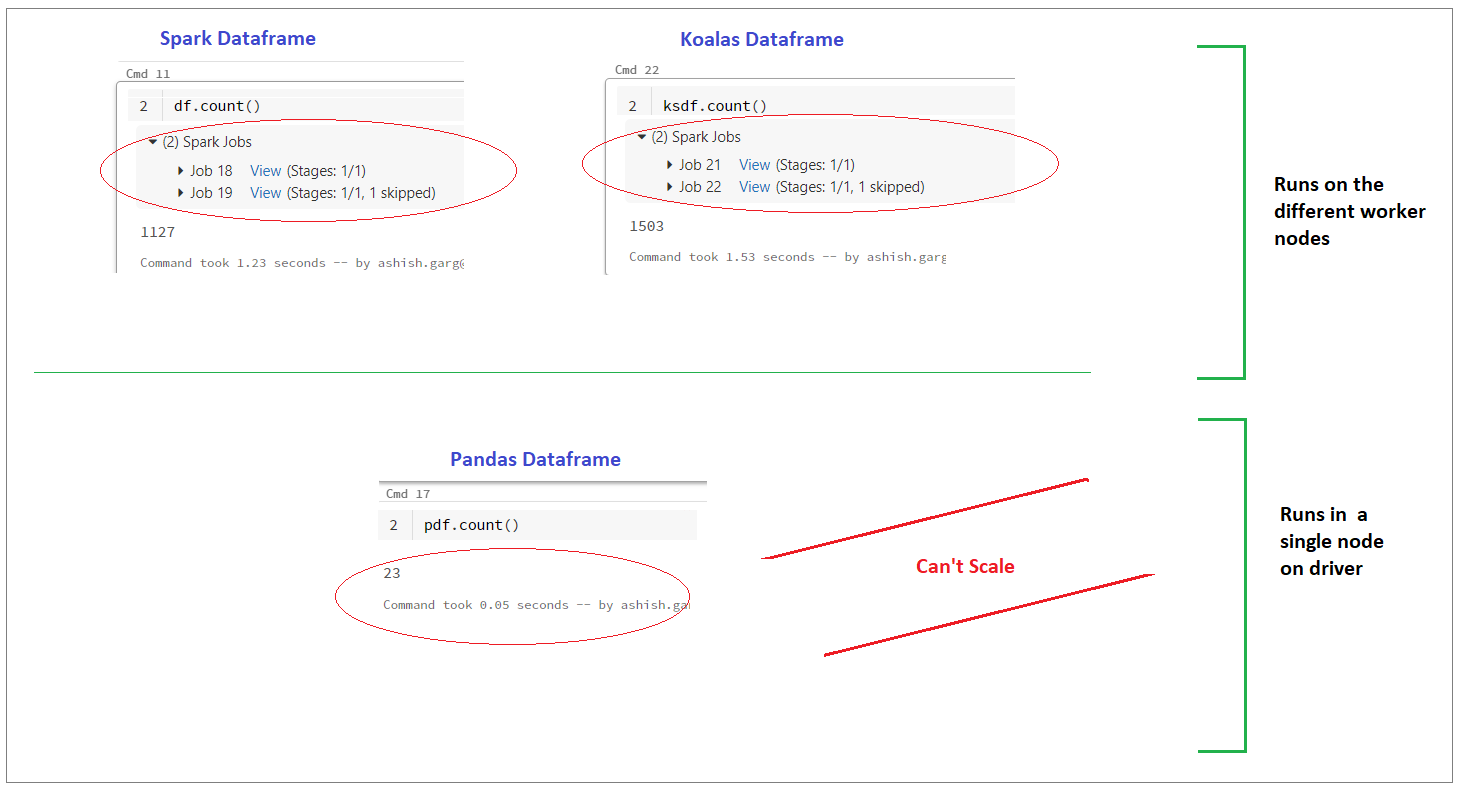
The first test conducted was to check how count operations execute in the data bricks environment. Also, to check if anything different is been observed if the three counts operations are compared for spark, koalas, and pandas data frames, respectively. The output has depicted pictorially in the diagram below. It confirms that the pandas’ data frame doesn’t use a worker thread. This is because you won’t see any spark job runs when performing an operation on the pandas’ data frame (refer to the diagram shown below). On to this, the spark and koalas data frames work differently. Their spark has created jobs to accomplish the count operation. These jobs are created over two separate workers (aka machines). This test confirms two things:
- Firstly spark and koalas are no different in terms of working.
- Secondly, Pandas are not scalable when the data load increases (i.e. it always works under a single node on the driver irrespective of data size). On the other hand, “koalas” is found distributed in nature and can be scaled as and when data size varies.
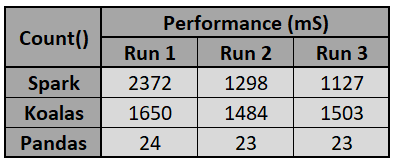
The second test performed in the sample program is the performance check for different data frames. Here the count operation execution time was calculated. The table below shows clearly the record count operations take a good amount of time in spark and koalas as opposed to the pandas. This justifies that underneath they are nothing but the spark data frame. Another important point to note here is the panda’s count performance is way ahead of the other two.
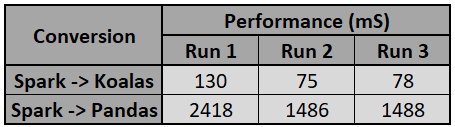
The third test confirms again that both are similar as there are not many operations that need to be performed by the data bricks if underneath two entities are the same. To test this, a performance test was conducted in a data bricks notebook, which tested the completion time of operations when converting spark data frames to koalas and pandas, respectively. The output shown here shows that the koalas’ conversion time is negligible compared to the pandas’ conversion time. This is because there is not much to do for spark because of the same structure of koalas’ data frame.
Evaluate Koalas Read API with the Complex Data Structure in Delta Table
The most common way of persisting data in modern delta lake is in the form of delta format. Azure Databricks delta table supports ACID properties similar to the transactional database tables. It is worth checking how the koalas (pandas API) work with the delta table that contains a complex JSON nested structure. So let’s begin.
Sample data structure
The sample data shown here contains two columns. First, the bank branch id (simple data) and second the department details (a complex nested JSON structure). This data is stored as the delta table.

Sample data – code
The sample data can be created by using the code below. The complete codebase is available on GitHub.
# create payloads
payload_data1 = {"EmpId": "A01", "IsPermanent": True, "Department": [{"DepartmentID": "D1", "DepartmentName": "Data Science"}]}
payload_data2 = {"EmpId": "A02", "IsPermanent": False, "Department": [{"DepartmentID": "D2", "DepartmentName": "Application"}]}
payload_data3 = {"EmpId": "A03", "IsPermanent": True, "Department": [{"DepartmentID": "D1", "DepartmentName": "Data Science"}]}
payload_data4 = {"EmpId": "A04", "IsPermanent": False, "Department": [{"DepartmentID": "D2", "DepartmentName": "Application"}]}
# create data structure
data =[
{"BranchId": 1, "Payload": payload_data1},
{"BranchId": 2, "Payload": payload_data2},
{"BranchId": 3, "Payload": payload_data3},
{"BranchId": 4, "Payload": payload_data4}
]
# dump data to json
jsonData = json.dumps(data)
# append json data to list
jsonDataList = []
jsonDataList.append(jsonData)
# parallelize json data
jsonRDD = sc.parallelize(jsonDataList)
# store data to spark dataframe
df = spark.read.json(jsonRDD)
Store temporary data to the delta table
Now persist above created temporary employee data to the delta table by using the code shown here.
table_name = "/testautomation/EmployeeTbl"
(df.write
.mode("overwrite")
.format("delta")
.option("overwriteSchema", "true")
.save(table_name))
dbutils.fs.ls("./testautomation/")
Read complex nested data using the koalas’ data frame
import pyspark.pandas as ps pdf = ps.read_delta(table_name) pdf.head()
On executing the above code the below output appeared.
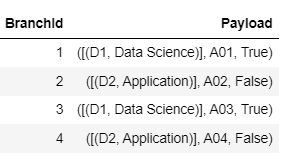
Read complex nested data using the Spark data frame
df = spark.read.load(table_name) display(df)
On executing the above code the output that appears is here.

Fig. 7: Complex JSON data – show via Display function
The above result suggests Pandas API (Koalas) doesn’t work well when calling the HEAD function to display the complex JSON Nested structure. This is against the main principle of using the Koalas library as its ultimate intention is to provide the distributed mechanism in the pandas’ library using the pandas’ functions. However, this can be achieved via a workaround where you can use the DISPLAY function in koalas’ data frame.
Conclusion
This article has set a strong foundation on the Koalas library for the readers. Furthermore, the different tests performed to verify the differences between pandas and koalas have indicated that koalas are nothing but spark data frames added to them with pandas’ APIs. In this post, we discussed the limitation that prevented Panda’s “head” function from properly displaying the nested JSON data. In summary, it is not wrong to say that as a primary method for analyzing and transforming big data, Koalas is a good choice, but be aware of its limitations so you have a fallback plan in case certain APIs may not work properly.
Key Takeaways
- By allowing data engineers and data scientists to interact with big data more efficiently, Koalas improved productivity.
- Make sure you do some research before using Koalas for complex nested JSON structures since its API may not produce the desired results.
- Koalas bridges the gap between the usage of Pandas API with the single node and distributed data to a great extent.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.






