Introduction
Support vector machines are one of the most widely used machine learning algorithms known for their accuracy and excellent performance on any dataset. SVM is one of the algorithms that people try on almost any kind of dataset, and due to the nature and working mechanism of the algorithm, it learns from the data as well, no matter how the data is and what type it is.
This article will discuss and answer the intervention on support vector machines with proper explanations and reasons behind them. This will help one to answer these questions efficiently and accurately in the interview and will also enhance the knowledge on the same.
Learning Objectives
After going through this article, you will learn.
- Kernal tricks and margin concepts in SVM
- A proper answer to why SVM needs longer training duration and why it is nonparametric
- An efficient way to answer questions related to SVM
- How interview questions can be tackled in an appropriate manner
This article was published as a part of the Data Science Blogathon.
Table of Contents
- How would you explain SVM to a nontechnical person?
- What are the Assumptions of SVM?
- Why is SVM a nonparametric algorithm?
- When do we consider SVM as a Parametric algorithm?
- What are Support vectors in SVM?
- What are hard and soft-margin SVMs?
- What are Slack variables in SVM?
- What could be the minimum number of support vectors in N-dimensional data?
- Why SVM needs a long training duration?
- What is the kernel trick in SVM?
- Conclusion
Q1. How Would You Explain SVM to a Nontechnical Person?
To explain the intuition and working mechanism of the support vector machine to a nontechnical person, I would take the example of roads.

As we can see in the above image, there are a total of three lines that are present on the road; the middle line divides the route into two parts, which can be understood as a line dividing for positive and negative values, and the left and right bar are them which signifies the limit of the road, means that after this line, there will be no driving area.
Same way, the support vector machine classifies the data points which the help of regression and support vector lines, here the upper and lower or the left and suitable vectors are limited for the positive and negative values, and any data point lying after these lines are considered as a positive and negative data point.
Q2. What are the Assumptions of SVM?
There are no certain assumptions about the SVM algorithm. Instead, the algorithm learns from the data and its patterns. If any data is fed to the algorithm, the algorithm will take time to learn the patterns of the data, and then it will result accordingly to the data and its behavior.
Q3. Why Support Vector Machine is a Nonparametric Algorithm?
Nonparametric machine learning algorithms assume any assumption during the model’s training. In these types of algorithms, the model does not rely on and function that will be used during the training and testing phase of the model; instead, the model trains on the patterns of the. Instead returns an output.
In the same way, the SVM algorithm also does not assume any assumptions from the data and learns from the data observations that are fed to the algorithm. That is why the SVM is known as a nonparametric, That learning algorithm. Although due to this, there is a great advantage associated with algorithms that are the learning of the algorithm is not limited as any data can be fed to the algorithm, and the a can learn from it, unlike parametric algorithm, which can only learn from the data which satisfies, s its assumptions.
Q4. When do we consider SVM as a Parametric Algorithm?
In the case of linear SVM, the algorithm tries to fit the data linearly and produces a linear boundary to split the data; here, as the regression line or the boundary line is linear, its principle is the same as the linear regression, and hence the direct function can be applied to solve the problem, which makes the algorithm parametric.
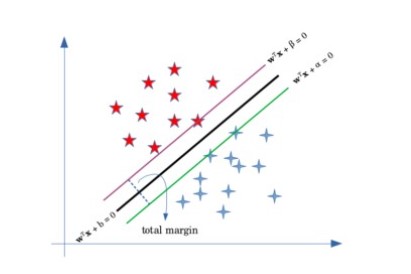
Q5. What are Support Vectors in SVM
Support vectors in SVM are data points, or we can call them regression line, which divides or classifies the data. The data points or the observations that fall below or above the support vectors are then classified accordingly to their category.
In SVMs, the support vector is considered for classifying the data observations, and they are only responsible for the accuracy and,d the performance of the model. Here the distance between the vectors should be maximized to increase the model’s accuracy. The points should fall after the support vector; some data points can lie before or between support vectors.
Q6. What is Hard and Soft margin SVMs?
As shown in the below image, some of the data points in soft margin SVM are not precisely lying inside their margin limits. Instead, they are crossing the boundary and lying a. Instead. Rather, instead. Instead, such a distance from their respective vector line.
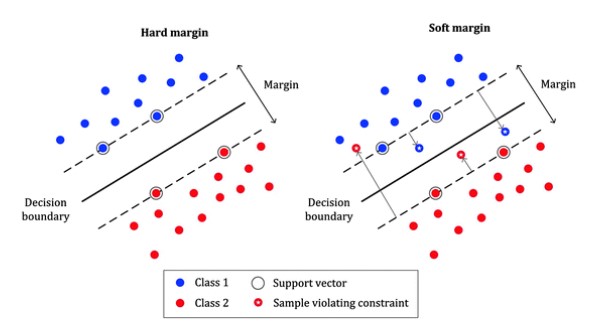
Whereas the hard margin SVM are those in which the data points are restricted to lie after their respective vector and are not allowed to cross the margin limit, which can be seen in the above image.
Q7. What are Slack Variables in SVM?
Slack variables in SVM are defined in so if margin algorithm that how much a particular data observation is allowed to violet the limit of the support vector and go beyond or above it. Here note that the more the slack variable, the violation of the support vector. To get an optimum model, we need to reduce the slack variable as much as possible.
Q8. What Could be the Minimum Number of Support Vectors in “N” Dimensional Data?
To classify the data points into their respective classes, there could be a minimum of two support vectors in the algorithm. Here, the data’s time or size will not affect the number of vectors, as per the general understanding of the algorithm. Theds a minimum of two support vectors to classify the data (in case of binary classification).
Q9. Why SVM needs a Longer Training Duration?
As we mentioned, SVMs are a nonparametric machine learning algorithm that does not rely on any specified function; instead, they learn the data patterns and then return an output. Due to this, the model needs time to analyze and sklearn from the data, unlike the parametric model, which implements the function to train on data.
The SVM provides one of the best advantages due to this, as the SVM knows to learn from the data, the learning of the algorithm is not limited, and the model can be implemented on almost any kind of data. At a given time and space complexity, the model can learn nearly any type of data pattern, unlike those parametric models whose knowledge a5re limited as they only get trained on the data, which satisfies their assumptions.
Q10. What are Kernel Tricks in SVMs?
The support vectors in SVMs are one of the best approaches to solving data patterns and can classify the linearly separable data set. Still, in the case of nonlinear data, the same decision boundary can not be used as it will perform inferior, and that is where the kernel trick comes into action.
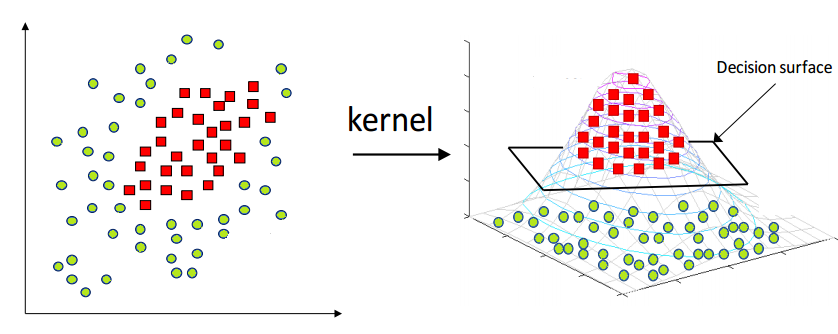
The kernel trick allows the support vector to separate between nonlinear data classes and classify nonlinear data with the exact working mechanism.
Here, several functions are kernel tricks, and some popular kernel functions are linear, nonfunctions linear, polynomial, and sigmoid.
Conclusion
In this article, we discussed the support vector machine and some interview questions related to the same. This will help one answer these questions efficiently and correctly and enhance knowledge about this algorithm.
Some of the Key Takeaways from this article are:
- Support Vector Machines are one of the best-performing machine learning algorithms which use its support vector to classify the data and its classes.
- Complex margin support vectors do not allow data points to cross their respective vectors, whereas, in soft margin SVM, there are no complicated rules, and some of the data points travel the margin.
- A support vector machine is a nonparametric model that takes more time for training, but the algorithm’s learning is not limited.
- In the case of nonlinear data, the kernel function can be used in SVM to solve the data patterns.
Wants to contact the author?
Follow Parth Shukla @AnalyticsVidhya, LinkedIn for more content. Contact Parth Shukla @ Parth Shukla | Email to contact me.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Parth Shukla
14 Feb, 2023
UG (PE) @PDEU | 25+ Published Articles on Data Science | Data Science Intern & Freelancer | Amazon ML Summer School '22 | AI/ML/DL Enthusiast | Reach Out @portfolio.parthshukla.live







