Introduction
The Hadoop Distributed File System (HDFS) is a Java-based file system that is Distributed, Scalable, and Portable. Due to its lack of POSIX conformance, some believe it to be data storage instead. Still, it does include shell commands and Java Application Programming Interface (API) functions that are similar to other file systems. HDFS and MapReduce are the two elements of a Hadoop. HDFS is used for data storage, while MapReduce is used for data processing.

Source: techtarget
HDFS provides the following Five Services:
- Name Node: HDFS has just one Name Node named Master Node. The master node can monitor files, operate the file system, and contain all stored data metadata. The name node, in particular, carries information like the number of blocks, the location of the data node where the data is kept, where the replications are saved, and other characteristics. The client has direct communication with the name node.
- Secondary Name Node: This is just for taking care of the file system metadata checkpoints that are in the Name Node. This is called the checkpoint node too. It is the Name Node’s helper Node. The Secondary Name Node orders the name node to generate and deliver the fsimage and editlog files, after which the Secondary Name node creates the compacted fsimage file.
- Job Tracker: Job Tracker accepts users’ seek for Map Reduce processing. The Job Tracker interacts with the Name Node to determine the location of the data that will be desired in processing. The Name Node responds with the necessary processing data information.
- Data Node: A Data Node holds data in the form of blocks. This is named the slave node too, and it is in charge of storing the real data in HDFS, which the client may read and write to. These are daemon slaves. Every 3 seconds, each Data node sends a Heartbeat message to the Name node, indicating that it is alive. When a Name Node does not get a heartbeat from a data node for 2 minutes, it considers that data node to be dead and begins the block replication process on another Data node.
- Task Tracker: It is the Job Tracker’s Slave Node, and it will accept the job from the Job Tracker. It gets information from the Job Tracker too. Task Tracker will apply the code to the file. Mapper is the process of applying that code to the file.
This article was published as a part of the Data Science Blogathon.
Table of Contents
Q1. How is HDFS Fault Tolerant?
Q2. Write the Features of HDFS.
Q3. Differentiate Between Regular FileSystem and HDFS?
Q4. What are The Most Important Parameters for Configuring a MapReduce Program?
Q5. Name the Three Different Modes in Which Hadoop May Operate.
Q6. What are the Functions of RecordReader, Combiner, and Partitioner in a MapReduce operation?
Q7. How Do You Restart NameNode and all of Hadoop’s Daemons?
Q9. Contrast HDFS with Network Attached Storage (NAS).
Q10. What Will You do if NameNode Fails?
Q1. How is HDFS Fault Tolerant?
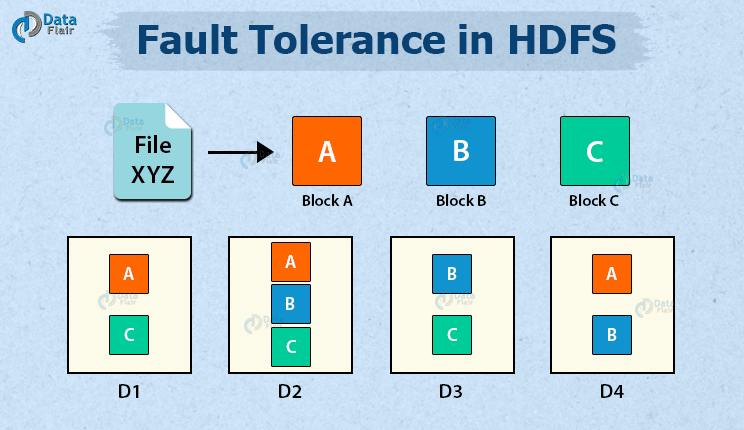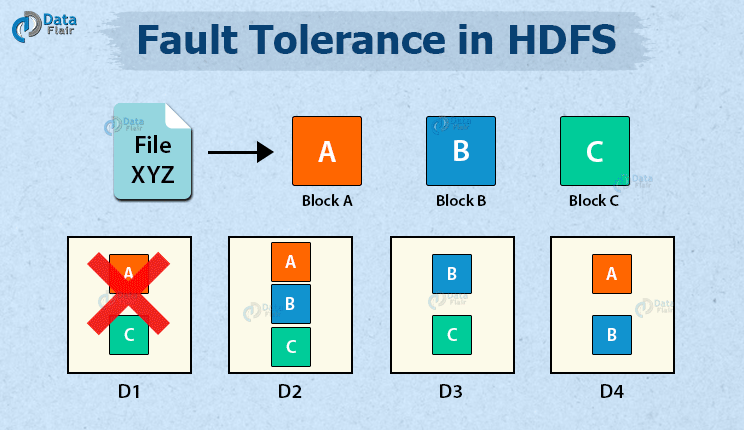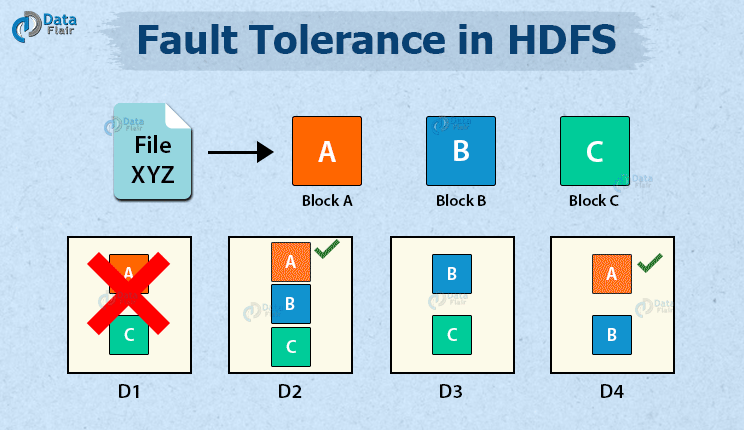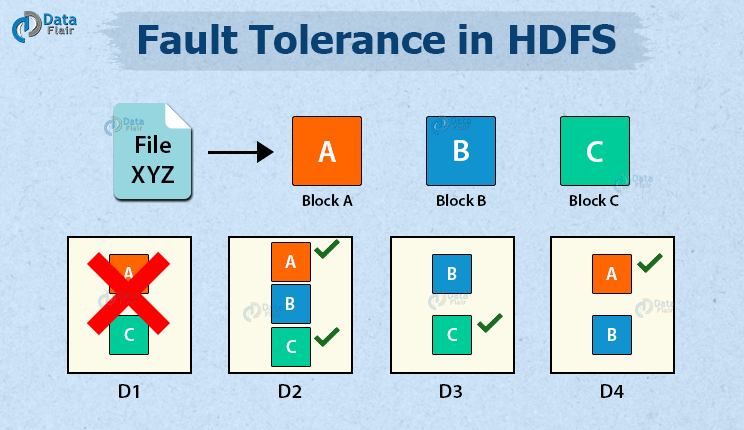
When data is saved on HDFS, NameNode replicates it to several DataNodes. The default replication factor value is 3. You can alter the configuration factor to suit your needs. If a DataNode fails, the NameNode will immediately copy the data from the replicas to another node and make the data available. In HDFS, this provides fault tolerance.
Q2. Write the Features of HDFS.
- HDFS has a high fault-tolerance level.
- HDFS may be made up of thousands of server computers. Every computer saves a part of the file system data. HDFS identifies and automatically recovers problems that may occur on computers.
- HDFS has a high throughput price.
- HDFS is intended to store and scan millions of data rows and count or add sections of the data. The length of time necessary for this process is determined by the intricacies involved.
- It was created to handle very large datasets in batch-style processes. However, the emphasis is on high data throughput rather than low latency.
- HDFS is cost-effective.
- HDFS is meant to be constructed on commodity machines and heterogeneous platforms that are low-cost and widely available.
Q3. Differentiate Between Regular FileSystem and HDFS?
Regular FileSystem: In a regular FileSystem, all of the data is kept in one place. Data recovery is difficult due to the machine’s low tolerance for failure. Because seek time is longer, it takes longer to process the data.
HDFS: Data is scattered and managed across several platforms using HDFS. Data can still be retrieved from other nodes in the group if a DataNode fails. Reading takes more time due to the need to read data from the disc locally and coordinate data from multiple systems.
Q4. What are the Most Important Parameters for Configuring a MapReduce Program?
The following configuration parameters are required:
- Enter the job’s location in HDFS.
- The job’s output location in HDFS
- Formats for input and output
- Classes with map and reduce functions
- The JAR file contains the classes for the mapper, reducer, and driver.
Q5. Name the Three Different Modes in which Hadoop May Operate.
There are three ways in which Hadoop may operate:
- Standalone (local) mode: This is the default mode if nothing is configured. All Hadoop elements, like NameNode, DataNode, ResourceManager, and NodeManager, operate as a single Java process in this mode. This makes use of the local filesystem.
- Pseudo-distributed mode: A single-node Hadoop deployment is termed a pseudo-distributed Hadoop system. All Hadoop services, including the master and slave services, were run on a single compute node in this way.
- Fully distributed mode belongs to Hadoop deployments in which the Hadoop master and slave services operate on distinct nodes.
Q6. What are the Functions of RecordReader, Combiner, and Partitioner in a MapReduce operation?
- RecordReader- This interacts with the InputSplit and turns the data into key-value pairs that the mapper can read.
- Combiner- This is an optional step that functions like a micro reducer. The combiner accepts data from the map tasks, processes it, and then forwards the results to the reduction phase.
- Partitioner- The partitioner determines the number of reduced jobs that will be used to summarize the data. It confirms too, how combiner outputs are routed to the reducer and regulate the important segmentation of intermediate map outputs.
Q7. How Do you Restart NameNode and all of Hadoop’s Daemons?
The following commands will help you in restarting NameNode and all daemons:
- Stop the NameNode with the ./sbin/Hadoop-daemon.sh stop NameNode command and restart it with the ./sbin/Hadoop-daemon.sh start NameNode command.
- You may use the ./sbin/stop-all.sh command to halt all daemons and then restart them using the ./sbin/start-all.sh command.
Q8. In HDFS, How do you Define Block? What is the Hadoop 1 and Hadoop 2 Default Block Size? Is it Possible to Modify It?
Blocks are the smallest continuous space on your hard disk where data is stored. Each record is kept in a separate “block” on the HDFS, and then those blocks are dispersed around the Hadoop clusters. Files in HDFS are divided into block-sized pieces and stored in separate units.
- Hadoop 1 has a 64 MB block size by default.
- Hadoop 2 has a 128 MB block size by default.
Yes, blocks may be modified. In a Hadoop context, the dfs.block.size option in the hdfs-site.xml file can be used to set the size of a block.
Q9. Contrast HDFS with Network Attached Storage (NAS).
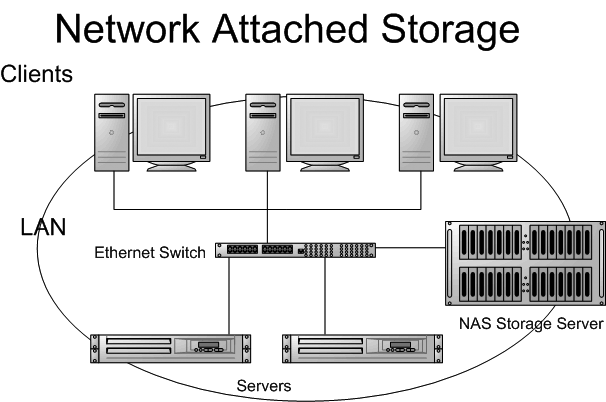
- A network-attached storage (NAS) server is a file-level computer data storage server that is linked to a computer network and provides data access to a wide group of customers. NAS can be either hardware or software that provides file storage and access services. Hadoop Distributed File System (HDFS) is a Distributed File System that uses a commodity system to store data.
- Data Blocks in HDFS are spread across all machines in a group. NAS, on the other hand, stores data on a specialized system.
- HDFS is built to operate with the MapReduce paradigm, which shifts computing to the data. Because data is kept apart from calculations, NAS is unsuitable for MapReduce.
- HDFS uses a low-cost commodity system, while NAS is a high-end storage system with a high price tag.
Q10. What Will you do if NameNode Fails?
To get the Hadoop group up and running again, the NameNode recovery process includes the following steps:
- Use the file system metadata copy to start a new NameNode (FsImage).
- Then, set up the DataNodes and users so that they can identify the newly created NameNode.
- After loading the latest checkpoint FsImage (for metadata information) and receiving enough block reports from the DataNodes, the new NameNode will begin serving the client.
However, this NameNode recovery process would potentially be time-consuming on big Hadoop clusters, which becomes much more difficult at the time with normal maintenance. As a result, we use HDFS High Availability Architecture.
Conclusion
The Hadoop Distributed File System (HDFS) is a fault-tolerant data storage file system that works on commodity systems. It was made to solve problems that regular databases couldn’t handle. This page focuses on interview questions for all levels, along with the following points:
- Hadoop Distributed File System is shortened to HDFS.
- Hadoop Distributed File System (HDFS) and MapReduce are two main elements.
- Data stored in a regular FileSystem is preserved in a single system.
- A network-attached storage (NAS) server is a computer data storage server that stores files on a network.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.







