This article will explain the difference between ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) when data transformation occurs. In ETL, data is extracted from multiple locations to meet the requirements of the target data file and then placed into the file. The transformation process occurs outside the target, a separate processing tool or system.
In ELT, data is extracted from multiple sources and placed into the target. The transformation process takes the data file using the processing power of the file. The transformation is performed after the data has been placed into the file.
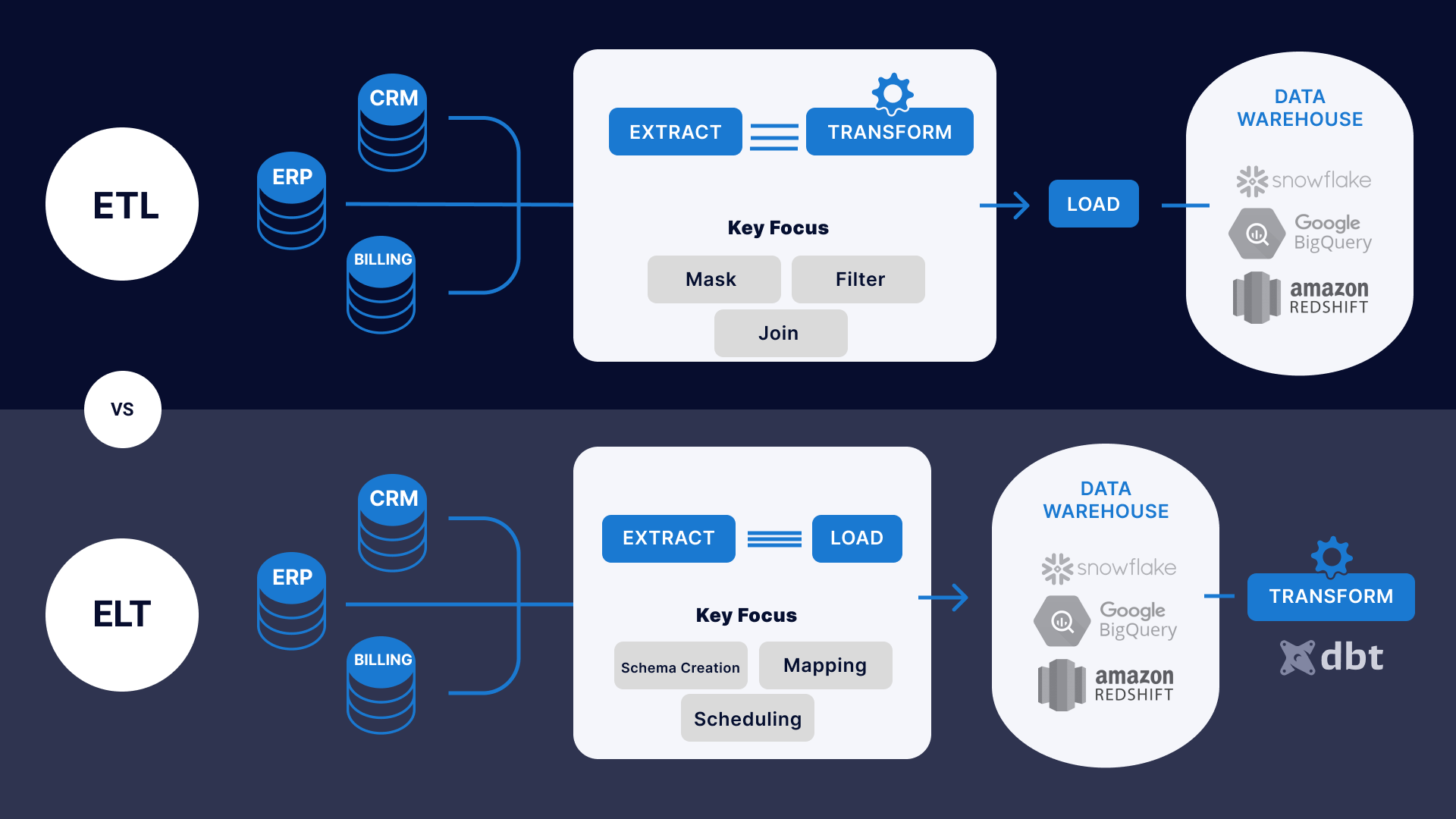
In summary, the main difference between ETL and ELT is the order of operations for data transformation and the location where the transformation occurs. ETL performs the transformation before loading data into the target file, while the ELT performs the transformation after loading data into the file.
Learning Objectives:
Here is some potential the article on ETL vs. ELT pipelines:
1. Understanding the difference between ETL and ELT pipelines, including when and where data transformations take place in each approach.
2. Comparing the pros and cons of ETL and ELT pipelines, including speed and data quality.
3. Becoming familiar with real-life examples of companies that have implemented ETL or ELT pipelines and understanding the factors that influenced their choice of approach.
4. Understanding the future trends and advancements in data integration, including the growing importance of cloud computing and real-time data processing.
Gaining a comprehensive overview of the data integration process, including the key steps in loading data. Evaluating the suitability of ETL and ELT pipelines for different types of data integration scenarios, factors that should be taken choosing between these approaches.
This article was published as a part of the Data Science Blogathon.
Here are some of the pros and cons of ETL and ELT pipelines:
Advantages of ETL pipelines:
Disadvantages of ETL pipelines:
Advantages of ELT pipelines:
Disadvantages of ELT pipelines:
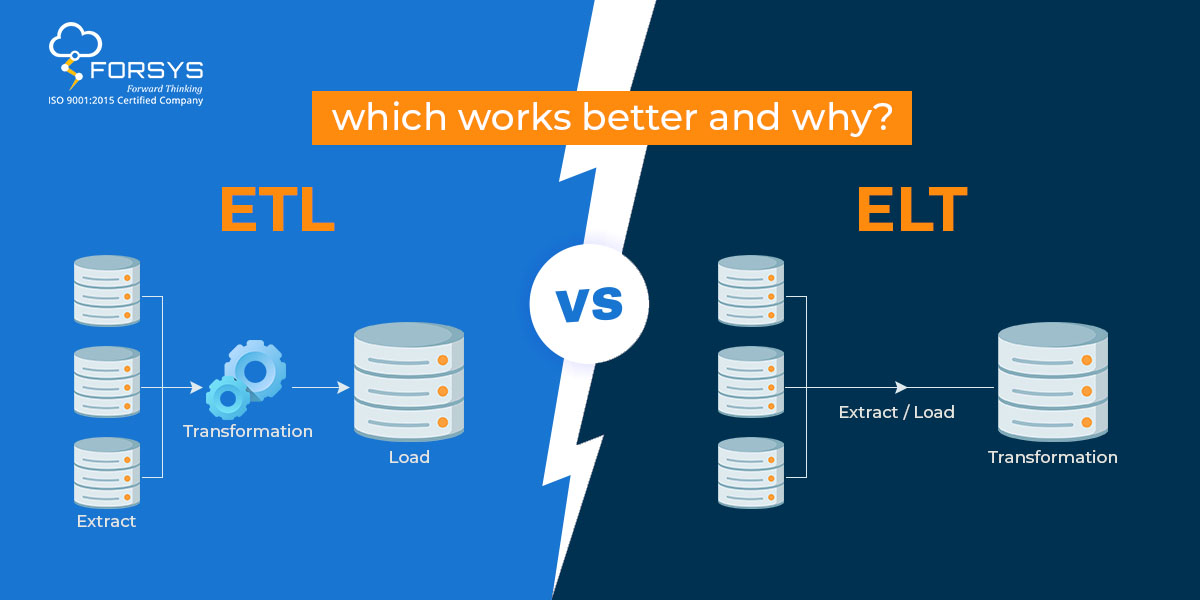
When choosing between ETL and ELT, it is specific requirements. For example, if the need to integrate data from multiple sources and perform complex transformations, ETL may be the better choice. ETL transformation capabilities and can handle complex data integration scenarios.
Some pointers to differentiate the two:
Here is an example of an ETL process using Python and the popular ETL tool Apache NiFi. The following code extracts data from a CSV file, performs, and loads the data into a MySQL database.
from nifi import ProcessGroup, ExtractText, ReplaceText, PutSQL
# Extract data from a CSV file
extract = ExtractText(path="path/to/input.csv")
replace = ReplaceText(search="old_value", replace="new_value")
# Load the data into a MySQL database
load = PutSQL(connection_url="jdbc:mysql://host:port/database",
username="username", password="password",
sql_select_query="INSERT INTO table (column1, column2) VALUES (?, ?)")
# Create a ProcessGroup to link the processors together
pg = ProcessGroup(processors=[extract, replace, load])
# Run the ETL process
pg.run()
Below is an example of an ELT process using Python and the SQLAlchemy library. The following code extracts data from a CSV file, load it into a PostgreSQL database and performs using SQL queries.
from sqlalchemy import create_engine
import pandas
# Connect to the PostgreSQL database
engine = create_engine("postgresql://username:password@host:port/database")
# Load the data from a CSV file into a Pandas DataFrame
df = pd.read_csv("path/to/input.csv")
# Load the data into the PostgreSQL database
df.to_sql("table_name", engine, if_exists="replace")
# SQL queries
with engine.connect() as con:
con.execute("UPDATE table_name SET column1 = column1 + 1")
con.execute("DELETE FROM table_name WHERE column2 = 'value'")
It’s important to note that these examples are just ETL and ELT processes, and the process is much more complex in the real-world scenario. It may involve different libraries and tools.
Security and data governance are critical factors when choosing between ETL and ELT. In ETL, data governance by the ETL tool can provide more granular control over the data. The ETL tool can be configured to implement security measures, encryption, data masking, and access controls. This can provide an added layer of security for sensitive data.
On the other hand, ELT relies on the target system for data governance. At the same time, the target system may provide robust security measures, but it has a different level of control than an ETL tool. Also, ELT loading data into the target system can create a security risk if the data contains sensitive information.
Data governance quality, lineage, cataloging, and compliance regulations. ETL can provide better data and allows better control over the data quality and lineage, making it easier to track data changes and better understand the data. On the other hand, ELT can be more challenging in data. It takes more work to track data changes and clearly understand the data.
Source: Analytics Vidhya
Here are some future trends and advancements in the field of data integration:
These trends and advancements will play a crucial role in shaping the future of data integration, making better data-driven decisions, improve their overall efficiency in the business landscape.

Here are some real-life examples of ETL or ELT pipelines:
In conclusion, ETL and ELT are common data integration approaches used to move from one system to another. ETL is the traditional approach, where data is the target system. ELT is a newer approach, where data is 1st loaded into the target system and then changed. ELT has benefits over ETL, including performance, more efficient use of resources, more real-time data integration, and governance.
ETL and ELT are not mutually exclusive and can be combined depending on ETL loading and ELT for real-time data integration. The choice between ETL and ELT should be based on specific requirements.
Key takeaways from this article:
1. ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) are integration approaches used to move from one system to another.
2. We discussed the benefits of ETL and ELT pipelines. As we have mentioned that ELT is more powerful and useful than ETL.
3. We discussed how to choose between ETL and ELT. We must discuss and decide which pipeline best works.
4. We coded some examples of ETL and ELT pipelines using Python, in which we read data from a CSV file and put it into a MySQL database after performing. After that, we concluded the article.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Lorem ipsum dolor sit amet, consectetur adipiscing elit,







